こんにちは
AIチームの戸田です
本日、KaggleのコンペCornell Birdcall Identificationが終了しました。私も参加していたのですが、結果は167位で、残念ながらメダル獲得には至りませんでした。とはいえ初めてきちんと取り組んだ音声データを扱ったコンペティションで、色々学びがありましたので今回はそのふりかえりをしたいと思います。
コンペ概要

鳴き声から鳥の種類を推定する音声処理タスクとなっています。スコアはmicro averaged F1で計算します。
今回のポイントは以下の3点だと考えています
1. "nocall"の予測
対象クリップ内に鳥の声が存在しない場合"nocall"というラベルをつけます。これだけならばピッチのしきい値などの対処方法があるかもしれないのですが、学習データに無い鳥の鳴き声がする場合でも"nocall"と予測する必要があります。
2. シングルラベルデータからマルチラベルを予測
学習データは"aldfly"、"ameavo"といった、鳥種類が名前になったフォルダにその鳥の音声ファイルが入っています。つまり音声データに対して1対1のラベルしか付与されていません。しかしテストデータはマルチラベル問題で、"aldfly comyel"のように半角スペースで区切って予測ラベルを作る必要があります。
3. テストデータが2種類
テストデータはsite1, site2, site3の3箇所で撮られた音声データです。site1とsite2は5秒ごとにラベル付けされているので、音声を読み込んだあと、5秒ごとにクリップして予測を行います。site3はファイルレベルでしかラベル付けされていないため、長い音声を読み込んで、予測結果を集計しなければなりません。
また大部分が隠されている(Private Test Data)ので、Kaggleでは常套手段となっているPseudo-Labelingなども使いづらい状況でした。
他にもファイルによってサンプリングレートが違ったりと、なかなか扱いが難しそうなデータでしたが、Tawaraさんの学習用NotebookとHidehisa Araiさんの推論用Notebookが非常に参考になり、巨人達の肩に乗ることで色々と試行錯誤できました。
詳細についてはコンペのページを参照ください。
計算環境
すべてGoogle ColaboratoryとKaggle Notebookで行いました。
今回は音声データということもあり、データの総量が23.61 GBもありました。このままでは、データの転送に非常に時間がかかってしまいますし、Google Colaboratoryのディスク容量をオーバーしてしまう恐れがあります。
そこで私は音声データをすべてスペクトログラムの画像としてjpg形式で保存することでこれを3.74 GBまで減らしました。
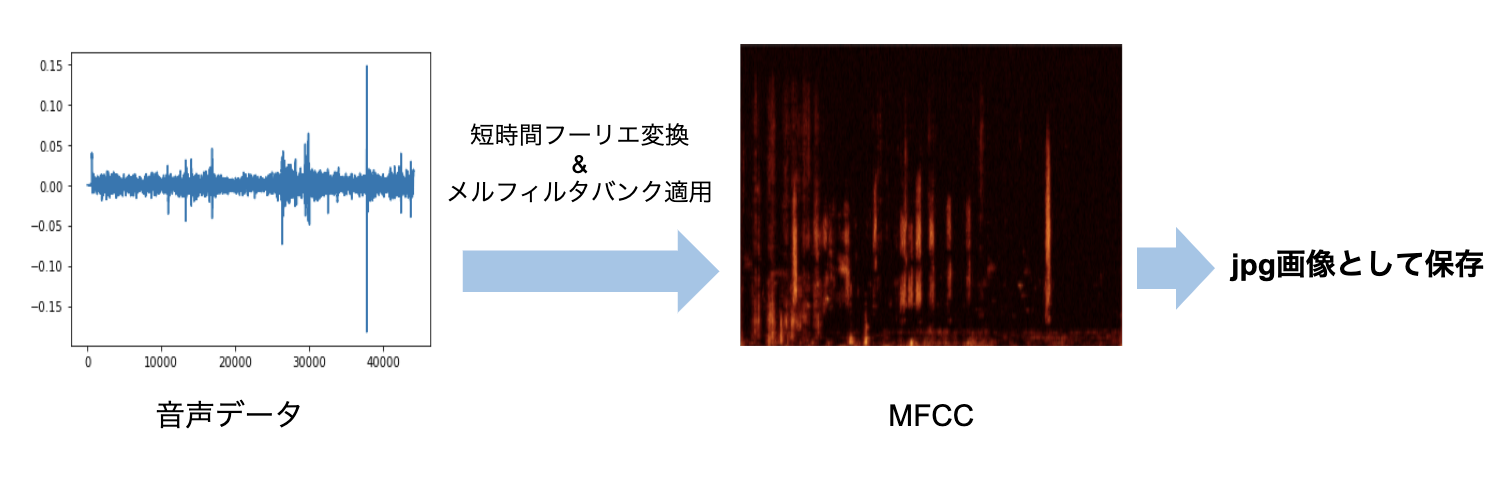
jpgにすることで若干情報が失われてしまう上に、ここで提案されているような波形のData Augmentationは使えなくなりますが、その分モデルや損失関数の試行錯誤を頑張りました。
スペクトログラムの画像データはこちらにPublic Datasetとして公開しています。
解法
最終Submitの解法概要は以下のようになります
- Model
- DenseNet201のヘッダーをカスタムしたモデル
- ImageNetで学習した重みを使って転移学習
- BCE loss
- 5-foldのCVをアンサンブル
こちらの論文を参考に、弱いラベルから疑似ラベルを生成し、Sound Event Detectionを学習するヘッダーを追加しました。
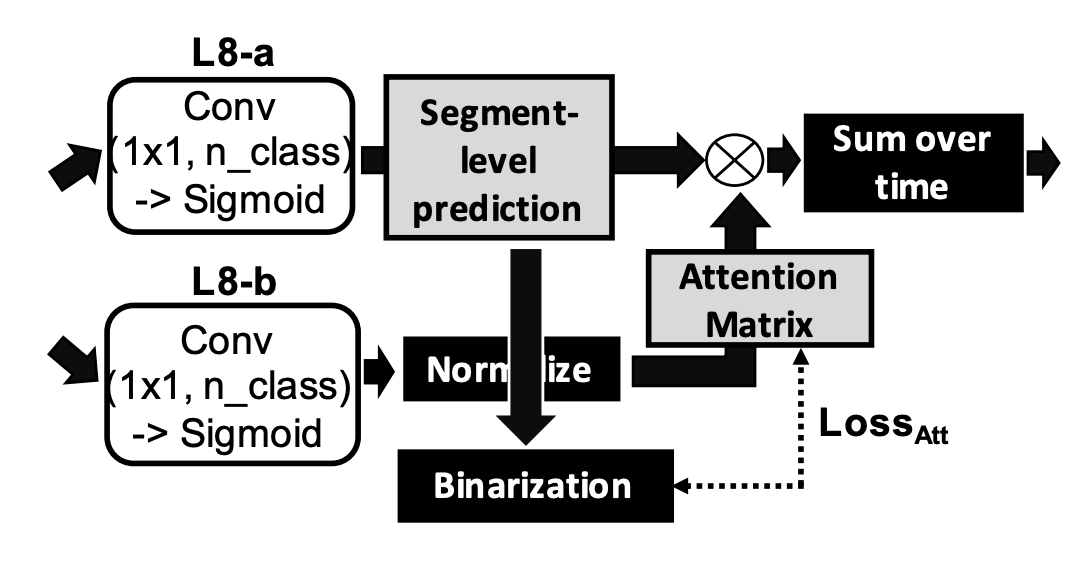
prediction is binarized on-the-fly and attention loss is computed between the
psuedo-strong label and attention matrix.
- Optimizer
- Adam+CosineAnnealingWarmRestarts
- learning_rate=1e-3, warm_upの周期 10epoch
- 55 epoch学習した後、追加で10 epoch SWAで学習
Optimizerは、私自身あまりこだわりがなく、探索するのもコストがかかるので、このコンペに限らず普段からあまり調整していません。今回工夫した点でいうと、SWAを使った追加学習でしょうか。SWAは初めて使ったのですが、手元のCVとPublic LB両方が上昇したので採用しました。
- Data Augumentation
- ガンマ補正
- Spec Augumentationの周波数方向のMASK
- MixUp(α=0.2)
こちらは色々試行錯誤した結果です。前述の通り、スペクトログラムの画像として音声データを扱っていたのでAugumentationパターンは制限されてしまいましたが、その中では色々試しました上でこちらに落ち着きました。
MixUpが効いたのはシングルラベルでの学習→マルチラベルの予測というタスクの特殊性もあったのかなと考えています。
学習に使用したコードはすべてGitHubに公開しました。
試したけどうまくいかなかったこと
毎回そうなのですが、試したけどうまく行かないことの方が多かったです...
また別のコンペでは役に立つかもしれませんし、こちらもまとめておきます。
- ResNet
- 多くの方がモデルにResNetを使っていたようですが、私はあまり精度が出なかったので使用しませんでした。
- Denoise
- テストデータはかなり雑音が多いとにらんでいたので、コンペ中盤ではノイズ除去に積極的に取り組んでおり、試行錯誤のNotebookも公開していました。
- しかしPublic LBでほとんど効果がみられず、計算コストも大きかったので、最終提出用には使用しませんでした。
- このあたりは今後公開されるSolutionなども参考にもう少し勉強したいです。
- 学習済みモデルでnocall予測
- PANNsという学習済みモデルをつかって、配布されている学習データに存在しないnocallラベルを予測しようと考えていました。
- PANNsの学習済みモデルは鳥の声に限らず電話のベルの音など、様々な音の分類を行うことができますが、鳥の声に絞って推論し、鳥の存在が確認できるデータのみで予測を行い、確認できなかったものはnocallとして扱うようにしました。
- 結果、スコアはあまり改善されなかったので、提出には使いませんでした。
- Transformer
- WaveNet
- WaveNetは音声合成で使用されるモデルですが、こちらを分類にも使えるのでは、という提案がこちらのDiscussionで提案されていました。
- 2ラベルのみに絞った少量データを使い、公開Notebookで学習を試したのですが、全く上手く行きませんでした。
- 上記のDiscussionでも議論しているのですが、WaveNetを使った分類モデルはノイズの影響を受けやすいことが原因だと考察しています。
- Secondary Labelの使用
- 実は学習データにsecondary_labelsという列が存在し、実際にラベルになっている鳥以外の、遠くで鳴いている鳥の種類があります。
- しかしすべてのデータに対して存在するわけではなく、データ収集者によって精度もまちまちでした。
- secondary_labelsを使ってマルチラベル問題として学習したりもしたのですが、どうも精度が改善せず採用しませんでした。
- その他
- しきい値調整
- Focal Loss
- CutMix
- Label Smoothing
- 時間軸方向のSpec Augumentation
- 回転などの画像系のData Augumentation
- 層ごとに異なる学習率の適用
- Multi Sample Dropout
おわりに
今回コンペティションでメダルは取れませんでしたが、ノートブックやDiscussionを積極的に公開した結果、なんと今回だけでNotebookメダルを5枚もいただき、Notebook Expertになることができました。
Hidehisa AraiさんやCamaroさんなど、尊敬するKagglerにもコメントもいただく事ができ、非常に嬉しかったです。
今後は、もちろんコンペティションでの金メダルを目指して頑張りますが、NotebookやDiscussionでもコミュニティに積極的に貢献していければなと思います。
余談
アイキャッチに使わせていただいた画像は、同僚の飼っている文鳥の銀次郎ちゃんです。(リモート会議でたまにさえずりが聞こえてきますw)
ピンクのくちばしがとっても可愛いですね^^

最後までお読みいただきありがとうございました
参考
KaggleのDiscussionに上げたSolution: https://www.kaggle.com/c/birdsong-recognition/discussion/183196




