こんにちは
AIチームの戸田です
先日、huggingfaceのAutoNLPで日本語が扱えるようになりました。
今回はAutoNLPを使って、言語処理学会 第27回年次大会で発表されたデータセット、WRIMEの感情分類を行い、従来手法との比較を行ってみようと思います。
AutoNLPとは
最先端の自然言語処理モデルの学習とデプロイを素早く簡単に行うことのできるライブラリです。コマンドライン数行書くだけで最新のTransformerのモデルを学習することができます。
現在解くことのできるタスクは以下の5種類のみです。
- binary_classification: 2値分類
- multi_class_classification: 多クラス分類
- entity_extraction: エンティティ抽出
- summarization: 要約
- speech_recognition: 音声認識
huggingfaceはBERTなどの最先端のモデルを利用できるOSS、Transformersで有名ですが、今回のAutoNLPは有料になりますのでご注意ください。
インストール方法などの詳細は公式ドキュメントをご参照いただければと思います。
WRIME
感情分析の研究のために、テキストの筆者の感情を注釈付けしたデータセットで、80人の筆者から収集した43,200件のSNSへの投稿が元データなっています。このデータセットに、8種類の感情(喜び、悲しみ、期待、驚き、怒り、恐れ、嫌悪、信頼)を4段階(0:無、1:弱、2:中、3:強)で主観(テキストの筆者1人)と客観(クラウドワーカ3人)の両方の立場から感情ラベルを付与しています。
こちらのGitHubリポジトリから使用することができます。
問題としては段階のある多ラベル問題になるのですが、AutoNLPが対応していないので、今回は問題を簡単にし、喜びの感情かどうかの2値分類問題として解いてみようと思います。
import pandas as pd
SEED = 42
wrime_df = pd.read_csv("wrime/wrime.tsv", sep="\t")
targets = (wrime_df['Avg. Readers_Joy'].values > 0).astype(int)
user_ids = wrime_df["UserID"].values
sentences = wrime_df["Sentence"].valuesデータ分割
80名の筆者ごとに特徴が分かれることを考慮して、UserIDをstratifyに設定してデータ分割します。全体の20%をテストデータとし、残りのデータの80%を学習、20%を評価用データとします。
from sklearn.model_selection import train_test_split
idx_lst = list(range(len(targets)))
_train_idx, test_idx, _, _ = train_test_split(idx_lst, idx_lst, test_size=0.2, random_state=SEED, stratify=user_ids)
train_idx, valid_idx, _, _ = train_test_split(_train_idx, _train_idx, test_size=0.2, random_state=SEED, stratify=user_ids[_train_idx])
train_texts = sentences[train_idx]
valid_texts = sentences[valid_idx]
test_texts = sentences[test_idx]
y_train = targets[train_idx]
y_valid = targets[valid_idx]
y_test = targets[test_idx]従来手法
シンプルなTF-IDF+ロジスティック回帰と、近年スタンダードなBERTをfine-tuningする手法を比較したいと思います。
TF-IDF+ロジスティック回帰
まずはMeCabで分かち書きをするクラスを作ります。
import MeCab
class WakatiMecab():
def __init__(self):
self.m = MeCab.Tagger ("-Ochasen")
def __call__(self, text):
wakati = [w.split("\t") for w in self.m.parse (text).split("\n")[:-2]]
return wakati
def wakati(self, text):
wakati = self.__call__(text)
wakati = [w[0] for w in wakati]
return " ".join(wakati)このクラスを使って、データの文章を分かち書きし、TF-IDFを計算します。
import tqdm
wakati_mecab = WakatiMecab()
train_corpus = [wakati_mecab.wakati(s) for s in tqdm(train_texts)]
valid_corpus = [wakati_mecab.wakati(s) for s in tqdm(valid_texts)]
test_corpus = [wakati_mecab.wakati(s) for s in tqdm(test_texts)]
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(train_corpus)
X_valid = vectorizer.transform(valid_corpus)
X_test = vectorizer.transform(test_corpus)正則化項の探索をします。
for c in [0.1, 0.3, 1.0, 3.0, 10.0]:
lr = LogisticRegression(C=c, random_state=SEED, n_jobs=-1)
lr.fit(X_train, y_train)
y_pred_valid = lr.predict(X_valid)
valid_acc = accuracy_score(y_valid, y_pred_valid)
print(f"C={c} : Validation Accuracy = {valid_acc:.4}")こちらを実行すると、以下のような出力が得られます。

最適と思しきC=3.0でテストデータの予測をします。
lr = LogisticRegression(C=3, random_state=SEED, n_jobs=-1)
lr.fit(X_train, y_train)
y_pred_test = lr.predict(X_test)
test_acc = accuracy_score(y_test, y_pred_test)
print(f"Test Accuracy = {test_acc}")
# Test Accuracy = 0.796412037037037約79.6%の正解率となりました。
BERTのfine-tuning
まず私がGitHubにあげているBERT学習のユーティリティコードをダウンロードしてインポートします。
import sys
sys.path.append("~/WrimePredict/src")
from model import WrimeBert
from dataset import WrimeDataset
from loop import train_loop, test_loop学習パラメータは以下のように設定します
import torch
from transformers import *
device = torch.device("cuda")
MODEL_TYPE = "cl-tohoku/bert-base-japanese-whole-word-masking"
LEARNING_RATE = 1e-5
WARM_UP_RATIO = 0.1
BATCH_SIZE = 256
N_EPOCHS = 3学習済みトークナイザーを使ってテキストをIDに変換し、学習/評価/テストに分割します。
TOKENIZER = BertJapaneseTokenizer.from_pretrained(MODEL_TYPE)
toks = []
for sent in tqdm(sentences):
tok = TOKENIZER.encode_plus(sent,
add_special_tokens=True,
max_length=64,
pad_to_max_length=True)
toks.append(tok)
train_toks = [toks[i] for i in train_idx]
valid_toks = [toks[i] for i in valid_idx]
test_toks = [toks[i] for i in test_idx]データセットやモデルを定義します。
train_dataset = WrimeDataset(train_toks, y_train)
valid_dataset = WrimeDataset(valid_toks, y_valid)
test_dataset = WrimeDataset(test_toks, y_test)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
drop_last=True,
)
valid_dataloader = torch.utils.data.DataLoader(
valid_dataset,
batch_size=BATCH_SIZE,
drop_last=False,
)
test_dataloader = torch.utils.data.DataLoader(
test_dataset,
batch_size=BATCH_SIZE,
drop_last=False,
)
model = WrimeBert(MODEL_TYPE, TOKENIZER)
model.to(device)
optimizer = Adam(model.parameters(), lr=LEARNING_RATE)
num_train_steps = len(train_dataloader) * N_EPOCHS
n_warmup = int(num_train_steps * WARM_UP_RATIO)
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=n_warmup,
num_training_steps=num_train_steps
)これですべての準備は完了です。実際に学習を回すコードは以下になります。
for epoch in range(N_EPOCHS):
print(f"Epoch-{epoch}")
train_loop(train_dataloader, model, optimizer, scheduler, device, tqdm)
y_pred, valid_loss = test_loop(valid_dataloader, model, device, tqdm)
valid_acc = accuracy_score(y_valid, y_pred)
y_pred, test_loss = test_loop(test_dataloader, model, device, tqdm)
test_acc = accuracy_score(y_test, y_pred)
print(f" valid: loss={valid_loss}/score={valid_acc}")
print(f" test: loss={test_loss}/score={test_acc}")こちらを実行すると、以下のような出力が得られます。

Validationのスコアが最高の時点のテストデータの正解率は約83.2%となり、シンプルな手法よりよい結果を得られました。
AutoNLP
いよいよAutoNLPをつかって学習を行います。
まずはautonlpにログインします。
autonlp login --api-key {登録すると発行されるAPI_KEY}
次に学習するプロジェクトを作成します。本来のWRIMEはマルチラベル問題ですが、今回は二値分類問題に簡易化したので、taskはbinary_classificationを設定します。
autonlp create_project --name wrime_joy_only \
--language ja \
--task binary_classification \
--max_models 1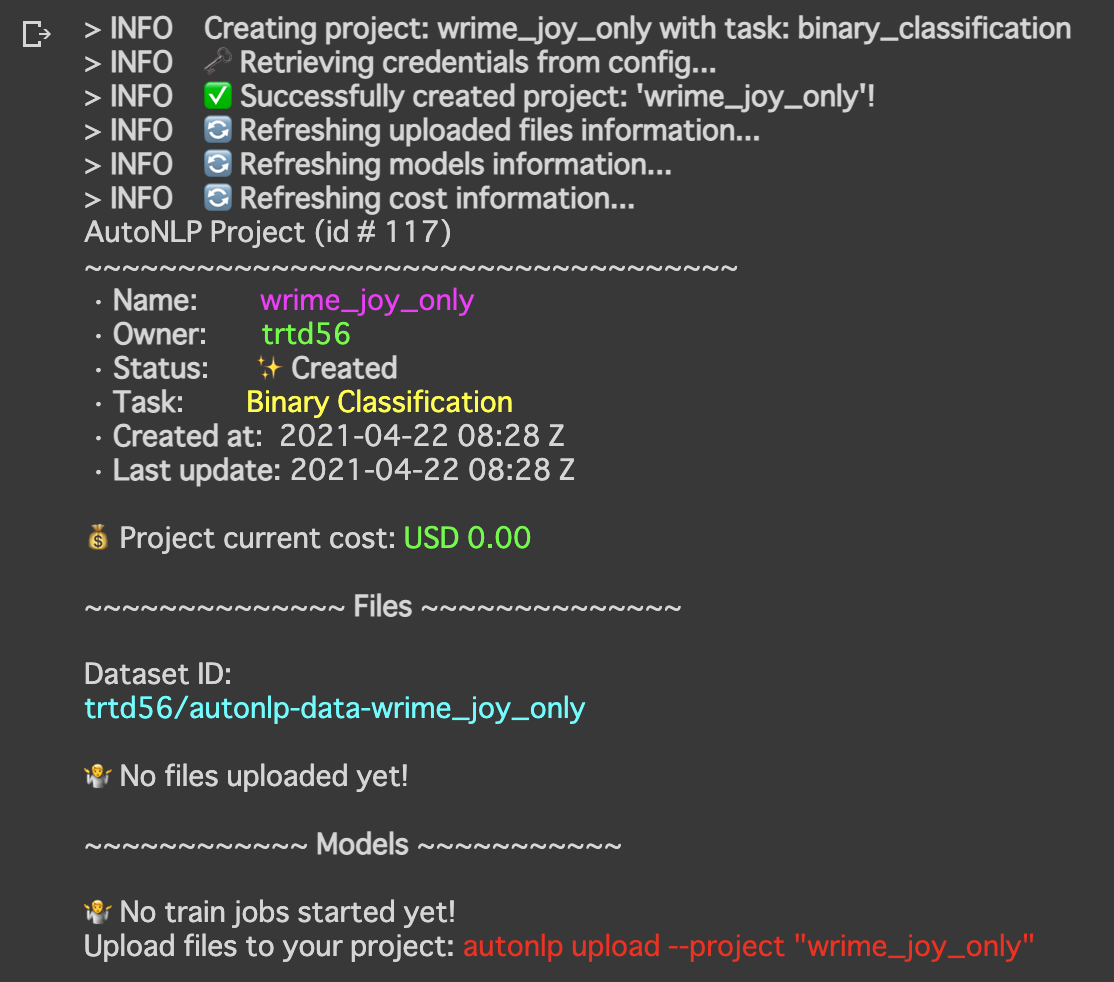
学習データと評価データをcsv形式でアップロードする必要があるので、それを作成します
train_df = pd.DataFrame(zip(train_texts, y_train), columns=["text", "label"])
valid_df = pd.DataFrame(zip(valid_texts, y_valid), columns=["text", "label"])
train_df.to_csv("train_joy.csv", index=None)
valid_df.to_csv("valid_joy.csv", index=None)アップロードするコードは以下になります。
autonlp upload --project wrime_joy_only --split train \
--col_mapping text:text,label:target \
--files ~/train_joy.csv
autonlp upload --project wrime_joy_only --split valid \
--col_mapping text:text,label:target \
--files ~/valid_joy.csv以下は学習データのアップロード時のログになります。

データのアップロードが完了したらいよいよ学習です。以下の一行で終わりです。
autonlp train --project wrime_joy_only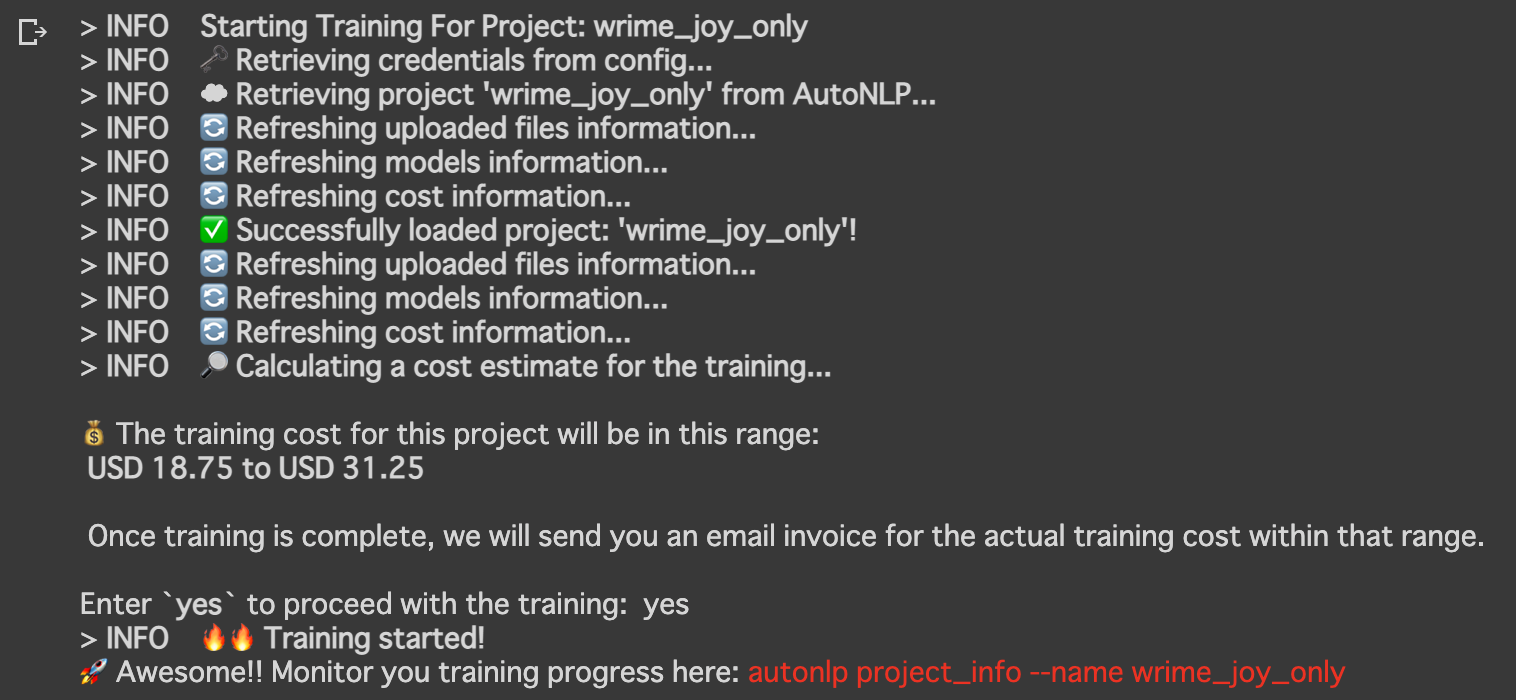
あとは学習が終わるまで待つだけです。以下のコードで学習の状況を確認することができます。
autonlp project_info --name wrime_joy_only
Modelsの状態がsuccessになっていれば成功です!
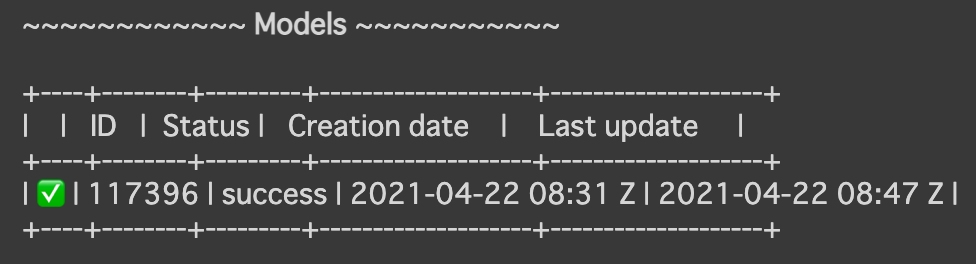
huggingfaceの自分のページに行くと学習結果を見ることができます

設定していなくても様々な指標が標準で計算されています。
学習したモデルはgitを使ってダウンロードすることができます
git clone https://huggingface.co/trtd56/autonlp-wrime_joy_only-117396ダウンロードしたモデルは以下のように読み込み、既存のtransformersのモデルと同様に扱うことができます。
from transformers import AutoModelForSequenceClassification, AutoTokenizer
autonlp_model = AutoModelForSequenceClassification.from_pretrained("./autonlp-wrime_joy_only-117396")
autonlp_tokenizer = AutoTokenizer.from_pretrained("./autonlp-wrime_joy_only-117396")テストデータで評価を行います。
model.eval()
pred_y = []
for text in tqdm(test_texts):
input_ids = autonlp_tokenizer.encode(text)
X = torch.tensor(input_ids).unsqueeze(0).to(device)
with torch.no_grad():
output = autonlp_model(X)
pred_y.append(int(output[0].cpu().argmax()))
accuracy_score(y_test, pred_y)
# 0.7612268518518519正解率は約76.1%となり、やや過学習してしまったように見受けられます。今回に関しては、学習方法というより、validatinの切り方を適当にやり過ぎたのが一つの原因かな、と考えています。
ちなみに以下のような形式でAPIとして試すこともできます。
curl -X POST -H "Authorization: Bearer {API_KEY}" \
-H "Content-Type: application/json" \
-d '{"inputs": "雨がめちゃくちゃ降ってきた"}' \
https://api-inference.huggingface.co/models/trtd56/autonlp-wrime_joy_only-117396
# [[{"label":"0","score":0.9993489384651184},{"label":"1","score":0.0006510863313451409}]]学習したモデルはPublicで公開しているので、よければ使ってみてください。
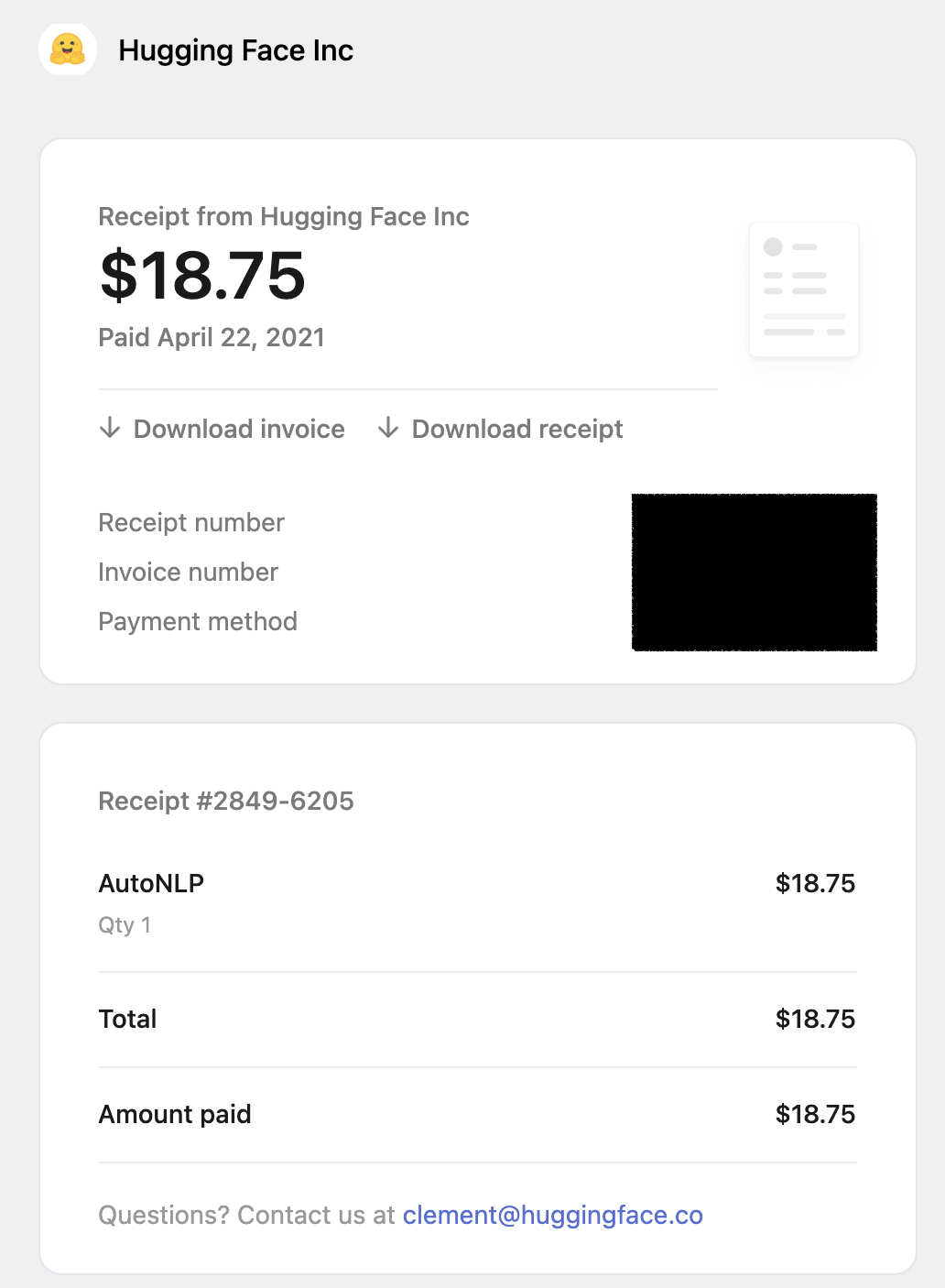
ちなみにかかった料金は$18.75でした。
おわりに
今回はhuggingfaceのAutoNLPで日本語の感情分類を簡易的に解いてみました。結果は過学習してしまったようですが、デプロイまでの速度を考えると、かなり便利なのではないでしょうか。また要約などのタスクをぱぱっと学習できるのは非常に嬉しいです。
最後までお読みいただき、ありがとうございました!




