こんにちは
AIチームの戸田です
11/29から11/30にかけて開催される第12回対話シンポジウムにて、AI Shiftからインダストリーセッションに1件、加えてAI Shiftと共同研究をしている名古屋工業大学 李研究室からポスターセッションに1件の発表を行います
本記事では発表内容をまとめますので、お聞きになる際の参考にしていただけると幸いです
ポスターセッション
- 発表日時:2021年11月29日 11:30-12:50
- タイトル:自動音声対話におけるネガティブ感情認識のための転移学習の性能比較
- 著者:〇高井幸輝,李晃伸(名工大),戸田隆道,東佑樹,下山翔(株式会社AI Shift)
AI Messenger Voicebotのような自動音声対話サービスではユーザが対話の途中で回線を断って対話を離脱する現象が頻繁に発生します。
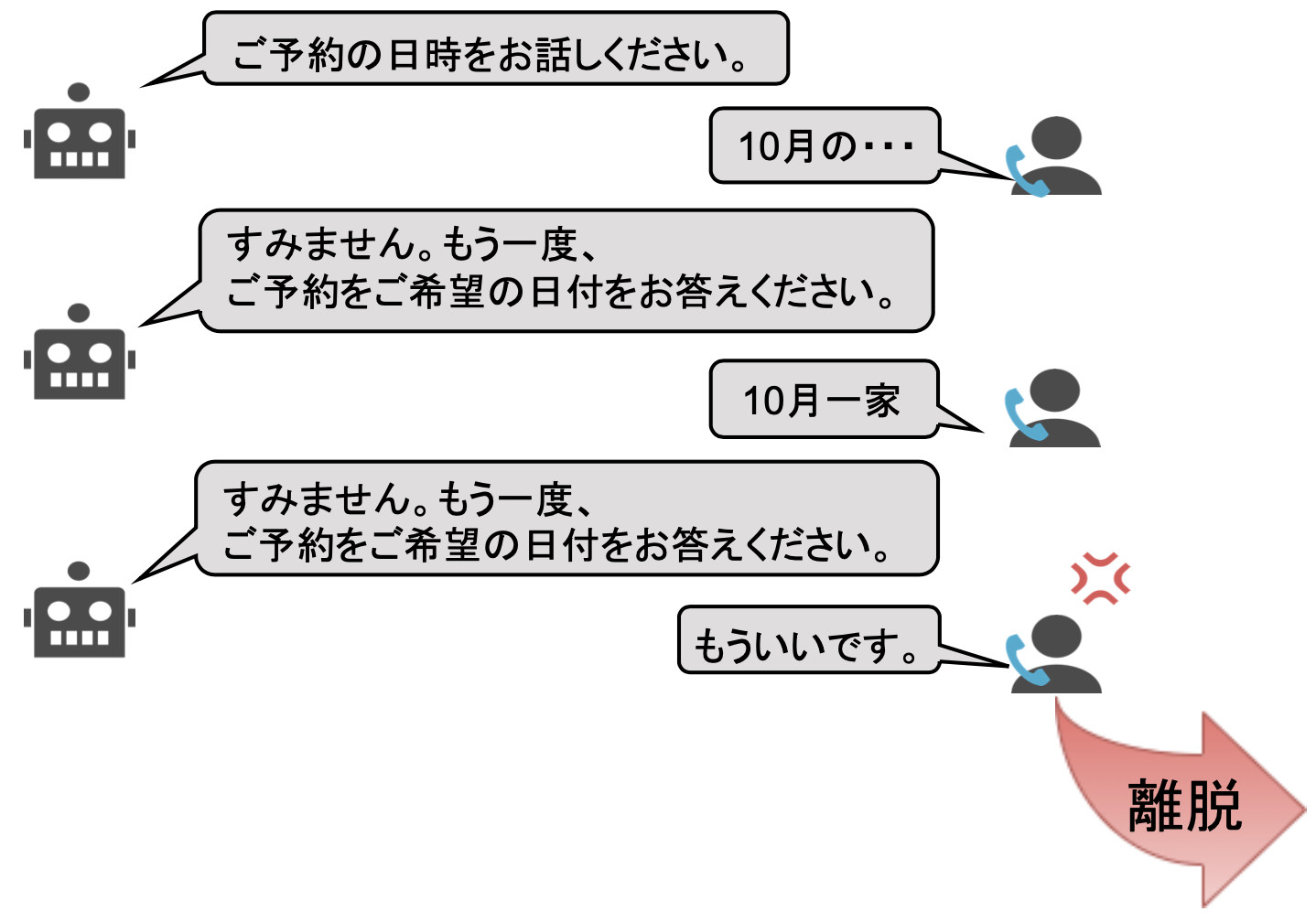
この離脱は、対話の満足度やユーザの興味の度合い、あるいはエンゲージメントの有無等の点から研究されており、例えばユーザのセンチメント(ポジティブ・ネガティブ)を推定することで対話に満足しているかどうかを評価している研究[1][2]や、非タスク指向の対話ではユーザが対話内容に興味を持っているかどうかを検出する研究[3]も行われています。
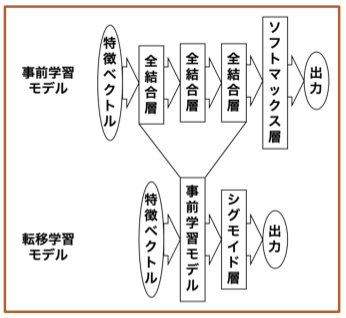
本研究は,離脱の直前のユーザとシステムのやりとり、およびそのユーザ音声に離脱を予測する手がかりが含まれていると仮定し、ユーザ音声から困惑や苛立ちなどのネガティブ感情の認識を行うことで、対話シナリオの修正や動的な発話誘導の判断指標とすることを目標としています。
今回の発表では、データ数の少ないネガティブ感情の認識精度向上のため、異なるドメインの感情音声データセットを用いた転移学習の有用性の検証・分析の結果を発表します
インダストリーセッション
- 発表日時:2021年11月30日 11:25-12:45
- タイトル:電話をインターフェースとした音声自動対話の取り組み
- 著者:〇戸田隆道,友松祐太,杉山雅和,邊土名朝飛,東佑樹,下山翔(株式会社AI Shift)
AI ShiftではAI Messenger Voicebotという音声自動対話サービスを提供しています。電話口での対応の自動化を目的としており、自治体などを中心に予約や質問応答などカスタマーから電話を受ける入電(インバウンドコール)だけでなく、サービス側からの架電(アウトバウンドコール)にも対応しています。

今年から始まったインダストリーセッションでは、学術的な完成度・新規性にこだわらず、技術的な取り組みや製品などを紹介できるセッションとのことだったので、我々が実際に音声自動対話サービスを運用して直面した、音声劣化による音声認識誤りの影響や大量接続の負荷, 音声自動対話に不慣れなユーザーへの対話誘導などの課題について紹介させていただきます
また、AI Shiftの親会社にあたるサイバーエージェントが、人間らしい自然で高度な音声対話応答の実現へ向けて設立しました完全自動対話研究センターについても紹介させていただきたいと思います

今回学会に参加されない方も、カジュアル面談は随時受け付けておりますので、少しでも気になる方は下記よりお問い合わせください
▽カジュアル面談フォーム
http://adtech-cyberagent-4430529.hs-sites.com/casual_meeting
▽募集要項
・機械学習エンジニア(音声/対話)
・機械学習エンジニア(NLP/対話)
・リサーチサイエンティスト
おわりに
以上の内容で当日は発表いたしますので、少しでもご興味を持った方はぜひセッションに参加していただき、様々な議論ができればと思います
最後までお読みいただきありがとうございました
参考文献
[1] Yelin Kim, Joshua Levy, Yang Liu.: SpeechSentiment and Customer Satisfaction Estimationin Socialbot Conversations. inProc of INTER-SPEECH, 2020, pp.1833-1837.
[2] Atsushi Ando, Ryo Masumura, HosanaKamiyama, Satoshi Kobashikawa, Yushi Aono.:Hierarchical LSTMs with Joint Learning forEstimating Customer Satisfaction from ContactCenter Calls. inProc of INTERSPEECH, 2017,pp.1716-1720.
[3] William Yang Wang, Julia Hirschberg.: Detect-ing Levels of Interest from Spoken Dialog withMultistream Prediction Feedback and SimilarityBased Hierarchical Fusion Learning. inProc ofSIGDIAL, 2011, pp.152-161.




