こんにちは。AIチームの杉山です。
本記事は AI Shift Advent Calendar 2021 の13日目の記事です.
今回の記事では、音声認識後のテキストデータに対する機械学習によるNLPのために、そのデータ数を増強する取り組みについて紹介します。
はじめに
弊社が提供している、電話での音声自動応答サービスであるAI Messenger Voicebotではユーザーの発話内容を音声認識で文字起こしし、その発話内容からタスクの完了に必要な意図推定やエンティティ抽出を行います。
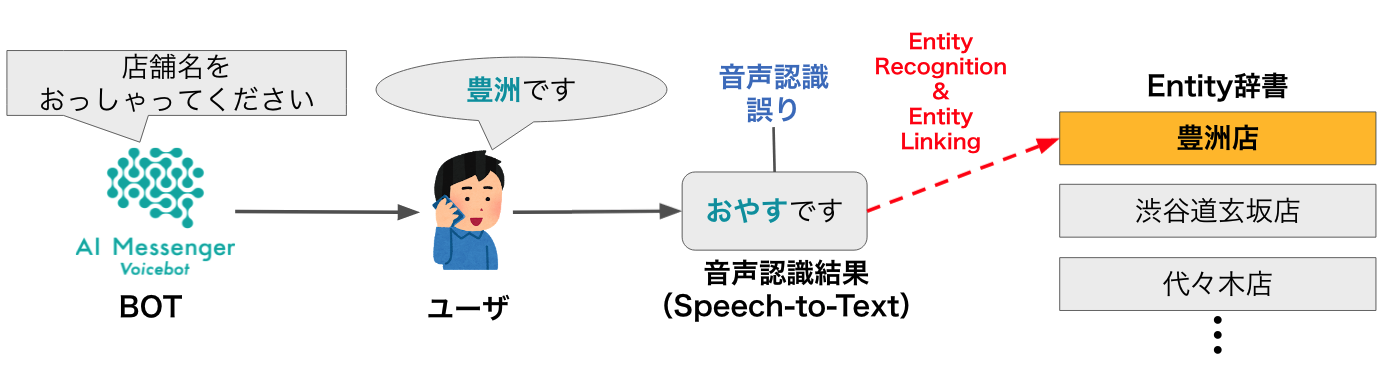
そのため、ユーザーの発話内容を正しく音声認識できることはタスクの完了率に直結する重要な要素ですが、近年大幅に進歩しているとはいえその精度は完璧ではありません。
そこで、対象のテキストデータに音声認識誤りが含まれていることを前提として機械学習によるエンティティ抽出を行う手法が近年提案されるようになっています。[1]
また、JSAI2021では音声認識誤り訂正において事前学習モデルのファインチューニングに擬似音声認識誤りを付与したデータを用いることでその精度が向上することを報告しました。[2]
上記報告では音声認識誤りデータの誤り傾向を分析し人手でルールを作成することで擬似音声認識誤りデータを作成しましたが、誤りのバリエーションは多い方が頑健なモデルになると考えられるため、今回は別の方法をいくつか試してみたいと思います。
音声認識のn-best
音声自動応答サービスで音声認識を使用する場合、通常は認識の確信度が最も高い結果を利用します。しかし、内部的には一つではなく確信度の劣る複数の認識候補を出力しているケースが多いため、ここではそれらを認識誤りを含むデータとみなして利用してみます。
なお、今回はGoogle社の提供するSpeech to Text APIを利用した際の方法を紹介します。
GoogleのSpeech to Textはその音声認識モデルとして複数のタイプ(default、スマートアシスタントへの命令用の短い認識を行うcommand_and_search, etc.)があり、その中には電話用に8kHzで収録された音声で学習したphone_callもあるのですが、こちらは執筆時点で日本語版がベータ版でしか提供されていないため、ここではベータ版のライブラリを使用します。今回は、データ増強のバリエーションを増やすためにdeafult, command_and_search, phone_callモデルの3パターンで検証し、その結果がどのように異なるかを確認します。
前回の私の記事と同様、QuickTime Playerで録音し電話音声と同じ8kHzにダウンサンプリングした音声データを使用します。
from google.cloud import speech_v1p1beta1 as gsv1
import io
gsv1_client = gsv1.SpeechClient()
speech_file = 'YOUR FILE PATH'
with io.open(speech_file, "rb") as audio_file:
content = audio_file.read()
audio = gsv1.RecognitionAudio(content=content)
config = gsv1.RecognitionConfig(
encoding=gs.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=8000,
language_code="ja-JP",
max_alternatives= 5,
model="MODEL TYPE", # default, command_and_search, phone_call
)max_alternativesを指定しないと確信度最大の結果だけが返ってきますが、今回は確信度上位5件の結果を取得するようにします。
それぞれのモデルに対し以下のように認識結果と確信度を表示します。
response = gsv1_client.recognize(config=config, audio=audio)
for result in response.results:
for alt in result.alternatives:
print(f"transcript:{alt.transcript}, confidence: {alt.confidence}")今回は以下の2パターンのスクリプトの読み上げを行いました。実際の電話口での発話を想定して、言い淀み(フィラー)を含めたり、意識的に明瞭すぎないように発話しています。
・えー、今日は12月13日の月曜日なので今年はあと19日しかないってことですかね?
・越前市(だいぶ曖昧に発音しています)
・えー、今日は12月13日の月曜日なので今年はあと19日しかないってことですかね? --------default------- transcript:今日は12月13日の月曜日なので今年はあと19日しかないってことですかね, confidence: 0.9450016021728516 transcript:えー今日は12月13日の月曜日なので今年はあと19日しかないってことですかね, confidence: 0.9373281598091125 transcript:今日は12月13日の月曜日なので今年はあと29日しかないってことですかね, confidence: 0.9475383758544922 transcript:今日は12月13日の月曜日なので今年は後19日しかないってことですかね, confidence: 0.943204402923584 transcript:きょうは12月13日の月曜日なので今年はあと19日しかないってことですかね, confidence: 0.9395167827606201 --------command_and_search------- transcript:今日は12月13日の月曜日なので今年はあと19日しかないってことですかね, confidence: 0.9384368658065796 transcript:今日は12月13日の月曜日なので今年は後19日しかないってことですかね, confidence: 0.9366952776908875 transcript:えー今日は12月13日の月曜日なので今年はあと19日しかないってことですかね, confidence: 0.9351337552070618 transcript:きょうは12月13日の月曜日なので今年はあと19日しかないってことですかね, confidence: 0.9405474662780762 transcript:今日は12月13日の月曜日なので今年はあと19日しかないって事ですかね, confidence: 0.9392229914665222 --------phone_call------- transcript:今日は12月13日の月曜日なので今年はあと19日しかないってことですかね, confidence: 0.9384368062019348 transcript:今日は12月13日の月曜日なので今年は後19日しかないってことですかね, confidence: 0.9366952776908875 transcript:えー今日は12月13日の月曜日なので今年はあと19日しかないってことですかね, confidence: 0.9351336359977722 transcript:きょうは12月13日の月曜日なので今年はあと19日しかないってことですかね, confidence: 0.9405474066734314 transcript:今日は12月13日の月曜日なので今年はあと19日しかないって事ですかね, confidence: 0.9392229318618774 ・越前市 --------default------- transcript:越前市, confidence: 0.802216649055481 transcript:一時停止, confidence: 0.5140787363052368 transcript:内弟子, confidence: 0.9035046696662903 transcript:愛知電子, confidence: 0.915828287601471 transcript:焼き菓子, confidence: 0.915828287601471 --------command_and_search------- transcript:小千谷市, confidence: 0.7011903524398804 transcript:味よし, confidence: 0.48776644468307495 transcript:越前市, confidence: 0.5940070748329163 transcript:襟足, confidence: 0.7328063249588013 transcript:味美, confidence: 0.8080649375915527 --------phone_call------- transcript:小千谷市, confidence: 0.7011904716491699 transcript:味よし, confidence: 0.48776644468307495 transcript:越前市, confidence: 0.5940070152282715 transcript:襟足, confidence: 0.7328063249588013 transcript:味美, confidence: 0.8080649375915527
一つめの方では、フィラーが省かれるか否かくらいでほぼ違いが見られない結果となってしまいましたが、defaultモデルでは19日->29日という誤りを含む結果が得られ、確信度も最も値として出力されました。
二つめの方では、それぞれのモデルで様々な認識誤り候補が得られました。これはだいぶ曖昧に発話したことも原因だと思いますが、スクリプトが名詞句だけの発話であったため言語モデルがうまく寄せられなかったのではないかと考えられます。
特にシステム主導のタスク指向対話では、タスク完了のためのエンティティのヒアリングのためのシナリオとして、
システム「目的地を教えてください」→ユーザー「越前市(です)」
のように名詞(句)+αで発話されるケースが多いためこちらのパターンで多様な認識誤りパターンを作成できることの方が実用的だと考えます。
実運用ではこのような入力に対してエンティティリンキングをうまく行って認識誤りに頑健にタスクを進めていけることが重要になります。
読み仮名からの翻字
次に、読み仮名からカナ漢字変換を行うことでバリエーションを作れないかを検証します。
こちらの記事で音素列認識を行うモデルを紹介しましたが、同様にカナ認識を行うモデルも作成しているため今回はそちらを用いることにします。
import librosa
from espnet2.bin.asr_inference import Speech2Text
speech2text = Speech2Text('YOUR MODEL', nbest=5)
speech, sr = librosa.load('YOUR AUDIO FILE')
bests = speech2text(speech)
for nbest in nbests:
asr_kana_result, *_ = nbest
print(asr_kana_result)また、カナ漢字変換にはGoogleのTransliterate APIを使うことにします。
import requests
text = "YOUR ASR_KANA RESULT"
url = f"http://www.google.com/transliterate?langpair=ja-Hira|ja&text={text}"
response = requests.get(url)
trans_result = response.json()
print(trans_result)カナ認識候補もカナ漢字変換候補もどちらも複数出力することができるため、それぞれの組み合わせで多様なバリエーションが作れることを期待しています。
前章と同様の音声に対してそれぞれ適用した結果は以下のようになりました。
・えー、今日は12月13日の月曜日なので今年はあと19日しかないってことですかね? エ エ ウ キ ョ ウ ハ ジ ュ ニ ワ シ ユ サ ン ジ ジ ヨ ビ ナ ノ デ ワ タ シ ハ ジ ュ ウ ビ ン チ シ カ ナ イ ッ テ コ ト デ ス カ ネ → [['ええ', ['ええ', 'エエ', '絵絵', '詠', '工エエェェ(´д`)ェェエエ工']], ['う', ['う', '兎', '甕', '鵜', '卯']], ['きょうは', ['今日は', 'きょうは', '教は', '強は', '凶は']], ['じゅ', ['樹', 'ジュ', '傑', 'ヂュ', 'JUS']], ['にわし', ['丹羽市', '庭師', '丹羽氏', '二輪氏', '庭し']], ['ゆさんじじ', ['油山寺じ', 'ユサンジじ', 'ゆさんじじ', 'ユサンジジ', 'ユサンジジ']], ['よびなので', ['予備なので', '呼びなので', 'よびなので', 'ヨビなので', '喚びなので']], ['わたしは', ['私は', 'わたしは', '渡しは', 'ワタシは', 'ワタシハ']], ['じゅうびんちしか', ['重便池しか', '重ビンチしか', '重Vinceしか', '重Vinceしか', '重Vinciしか']], ['ないってことですかね', ['ないってことですかね', 'ないって事ですかね', '無いってことですかね', '無いって事ですかね', 'ないってことですかネ']]] エ エ ウ キ ョ ウ ハ ジ ュ ニ ワ シ ユ サ ン ジ ジ ヨ ビ ナ ノ デ ワ タ シ ハ ジ ュ ウ ビ ン ジ シ カ ナ イ ッ テ コ ト デ ス カ ネ # → 文として成立していない出力のため以下略 エ エ ウ キ ョ ウ ハ ジ ュ ニ ワ シ ユ ウ サ ン ジ ジ ヨ ビ ナ ノ デ ワ タ シ ハ ジ ュ ウ ビ ン チ シ カ ナ イ ッ テ コ ト デ ス カ ネ エ エ ウ キ ョ ウ ハ ジ ュ ニ ワ シ ユ ウ サ ン ジ ジ ヨ ビ ナ ノ デ ワ タ シ ハ ジ ュ ウ ビ ン ジ シ カ ナ イ ッ テ コ ト デ ス カ ネ エ エ ー キ ョ ウ ハ ジ ュ ニ ワ シ ユ ウ サ ン ジ ジ ヨ ビ ナ ノ デ ワ タ シ ハ ジ ュ ウ ビ ン チ シ カ ナ イ ッ テ コ ト デ ス カ ネ ・越前市 エ キ ゼ ン シ → ['駅前し', 'えきぜんし', 'エキゼンシ', 'エキゼンシ'] エ チ ゼ ン シ → ['越前市', '越前氏', 'エチゼンし', '越膳し', 'えちぜんし'] エ ク ゼ ン シ → [['えく', ['エク', 'えく', '笑空', '江区', '壊苦']], ['ぜんし', ['全史', '前肢', '前翅', '全市', '前史']]] エ キ デ ン シ → ['駅伝し', '駅田市', 'エキデンし', '易田し', 'えきでんし'] イ キ ゼ ン シ → ['いき', ['行き', 'いき', '息', '生き', '粋']], ['ぜんし', ['前歯', '前死', '前市', '全史', '前肢']]
結果として、読み認識だけだと後段の言語モデルが効いておらず単語、文として成立していない系列が出力されてしまい、特に長文だとうまくいかない結果となりました。
名詞句のみのケースでは正解を含むいくつかそれらしいケースが出力されましたがそれでもやはりそのまま使うには厳しい結果となってしまいました。
終わりに
今回の記事では、音声認識誤りにおける擬似音声認識誤りデータの作成の可能性を2つ検証しました。今回紹介した方法は特に後者は残念ながらあまり良い結果とはなりませんでしたが、今後もより良い音声自動応答でのタスク指向対話の実現のために様々なアプローチで改善を試みていきたいと思います。
参考
https://cloud.google.com/speech-to-text/docs/languages?hl=ja
https://cloud.google.com/speech-to-text/docs/reference/rest/v1p1beta1/RecognitionConfig
https://www.jstage.jst.go.jp/article/pjsai/JSAI2021/0/JSAI2021_2Yin504/_article/-char/ja/




