こんにちは、AIチームの東です。
今回は3月9日(水)から3月11日(金)の3日間開催されていました、音響学会の発表報告をさせていただければと思います。
共同研究の発表概要についてはこちらをご覧ください。
日本音響学会2022年春季研究発表会
今年の音響学会は主にZoomを用いたオンライン開催で、口頭発表とポスターセッションに加え、前日企画、特別講演、懇親会が行われました。
AI Shiftの参加は今回が初めてでしたが、音声処理だけでなく聴覚や超音波、音楽音響など、音に関わるあらゆる分野を広範囲にカバーしており、参加者としても学びの大きい研究発表会となりました。
発表報告
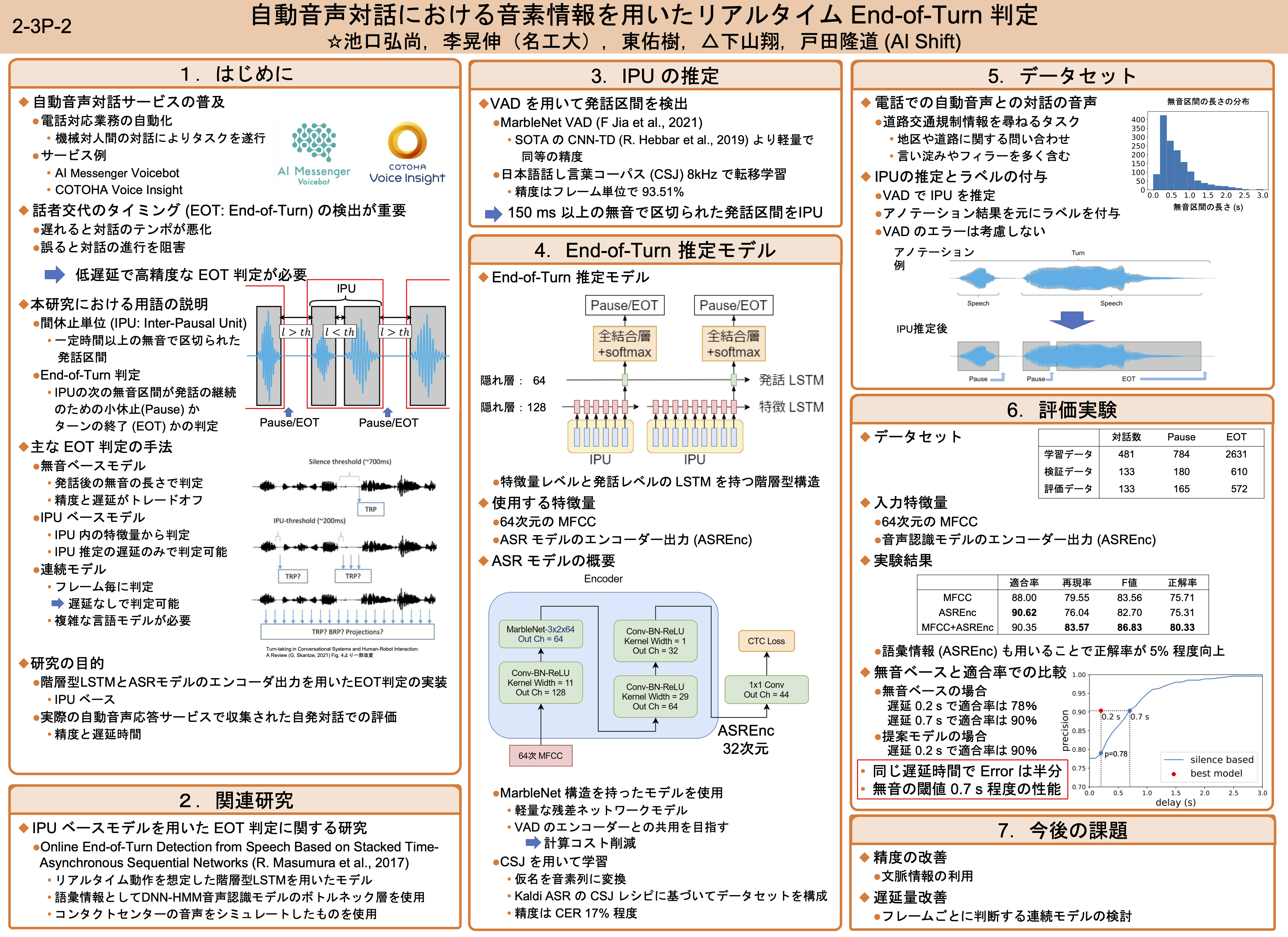
今回AI Shiftからはポスターセッションで1件の発表を行いました。
[2-3P-2] 自動音声対話における音素情報を用いたリアルタイム End-of-Turn 判定
著者:池口弘尚、李晃伸(名工大)、東佑樹、下山翔、戸田隆道 (AI Shift)
質疑応答一覧
Q:軽量なモデルとのことだが、どのようなモデルを使用したか?
A:NVIDIAにより開発されたMarble Netを使用。ノイズに頑健なモデルで、最先端のモデルの約10分の1のパラメーター数で同程度の性能を達成している。
Q:目的は、「お客さんの発話を素早くきちんと区切りたい」であっているか?
A:その通り。
Q:発話内容によってEoTのタイミングを柔軟に変えることができそうな気がする(フィラーを無視する、など)が、本手法はそれを考慮したものになっているか?
A:研究のモチベーションとしてはそのような柔軟さを改善していきたい。今回のデータは短い単位の発話が多かったからか、市町村名や道路名の間の無音ではうまく対処できている。
Q:今回の手法ではなぜそれが可能になっているのか?
A:ASRのエンコーダー出力を入力に加えているのが効いているのではとの印象を持っているが、原因は分析を行っている段階である。
Q:150ms以上の無音でしか判定は行っていないのか?だとすると判定ミスが起きるとEoT判定にならずそのままになってしまうのか?
A:実験設定としてそのような状況になる可能性はあるが、運用時には無音ベースの手法と併用することを検討している。
Q:データの詳細が知りたい。電話口での対話ということはマルチターン(何回もやりとりがある)であるか?だとするなら何ターン程度あるのか?
A:状況としてはマルチターンの発話。ターン数は10ターンを超えないくらいである。
コメント:学習設定としては妥当だと感じる
Q:データセットでは、ユーザはどういうつもりで喋っているのか?相手が機械だという前提で喋っているのか?
A:機械だという前提で喋っている。
Q:音響特徴は人間同士とどれくらい違う?応答が自然になると人間側も自然になって、もっと柔軟な対話になるのか?
A:データを見た実感として、人間同士の対話とは全く異なっていると感じている。
コメント:現在のシステムではユーザーとしてはちょっと遅いと感じているかもしれないが、ターンテイキングが早すぎると逆に気持ち悪さを感じるのでは?
Q:従来手法との違いはASRのエンコーダー出力を利用している点か?
A:エンコーダー出力を用いている点と、実際に運用された音声対話サービスのデータを用いて検証を行なっている点
Q:話者は何種類あるか?
A:話者数の分析は行なっていないが、実際のサービスで収集した音声なので、基本的には1データには1人の話者のみが存在する。
Q:学習データと評価データでは異なる話者となっているか?
A:話者によってデータを分けるということは行なっていない。
Q:話者による結果の違いは分析できているか?
A:現時点で分析はできておらず、今後検証していきたい。
印象に残った発表
大変勉強になる発表が非常に多く、追いきれなかったものも多々あるのですが、人間の知覚評価をフィードバックに用いる手法や、音声認識と音声合成を同時に使用したラベルなしの手法など、ドメイン適用にも様々な手法が提案されているのだと学びになりました。
研究対象としては話速やピッチなどを制御可能な音声合成や叫び声、笑い声を扱った研究など、テキストに現れないパラ言語情報を扱った研究が多かったのも印象的でした。
超音波を用いたコーヒーの成分抽出促進といった内容もあり、改めて音響学会のカバーする研究範囲の広さを感じられました。
おわりに
音を扱った研究を広く扱った大規模な学会ということもあり、最新の研究動向など多くの学びを得られる機会となりました。また、共同研究では多数の質問やコメントをいただき、良い議論の場になりました。
このような場を提供してくださった運営の皆様に大変感謝しております。今後も継続的に発表、参加していければと思います。




