こんにちは
AIチームの戸田です
本記事では先週終了しましたKaggleのコンペティション、NBME - Score Clinical Patient Notesの振り返りを行いたいと思います
コンペ概要

背景
米国の医師免許試験では患者の症状のメモ(患者メモ)を取る試験があります。この試験では、受験者はテスト患者(特定の臨床例を話すようにしている仮想の患者)の話を聞いて患者メモをとります。そして医師の採点者がそのメモを採点するのですが、この作業には多大な時間と人的・経済的リソースが必要になります。
この問題を解決するために、近年自然言語処理を用いたアプローチが考えられています。しかしメモの特徴は様々な表現が可能であるため、「キーワードが出現するか」のよう単純な方法ではスコアリングできません。
コンペ概要
患者メモに含まれる特定の臨床概念を特定します。具体的には、臨床概念(例:「食欲不振」)と、医学生が書く患者メモにある様々な表現方法(例:「食事量が少ない」「服がゆったり着られる」)を対応づけます。
学習に使えるデータは以下3種類です
- train.csv: アノテーション情報
- features.csv: 臨床例
- patient_notes.csv: 受験者がとった患者のメモ
またCode Competitionなので、推論コードを提出し、推論時間は9時間に収める必要があります
解法
今回のタスクは臨床例に合わせて患者メモ中の特定の単語をマーキングするような問題になるので、Question AnsweringとNamed Entity Recognitionをあわせたようなタスクになります。
最近のNLPでは定番だと思いますが、基本的な解法は学習済みTransformerモデルのfine-tuningでした。Discussionや公開Codeをみると、今回はMicrosoftのDeBERTaがよく使われている印象でした。
今回キモになったのは、以下の2点だと私は考えています。
- ラベルなしデータの利用
- トークナイザーの特性を考慮した後処理
上記2点に加え、コンペ終了後、Discussionで公開されてた私が気づけなかった解法を紹介します
なお、私の使った実験コードはGitHubにあげています
ラベルなしデータの利用
配布データのpatient_notes.csvには4万件近くの患者メモが存在しますが、その中でアノテーションされているのは1000件程しかありません。つまりドメインの文章ではあるがラベル付けされていない文章が大量にあるということです。このラベルなしデータをどう利用するかが上位に食い込むカギになっていたと思います。
私はアノテーションされたデータで学習したモデルを使って、ラベルなしデータに擬似的なラベリングを行うPseudo Labelingを試しました。今回Pseudo Labelingを行う際に気をつけなければならないのは、ラベルなしデータがアノテーションされたデータと同じ症例を扱っているので非常によく似ているということです。
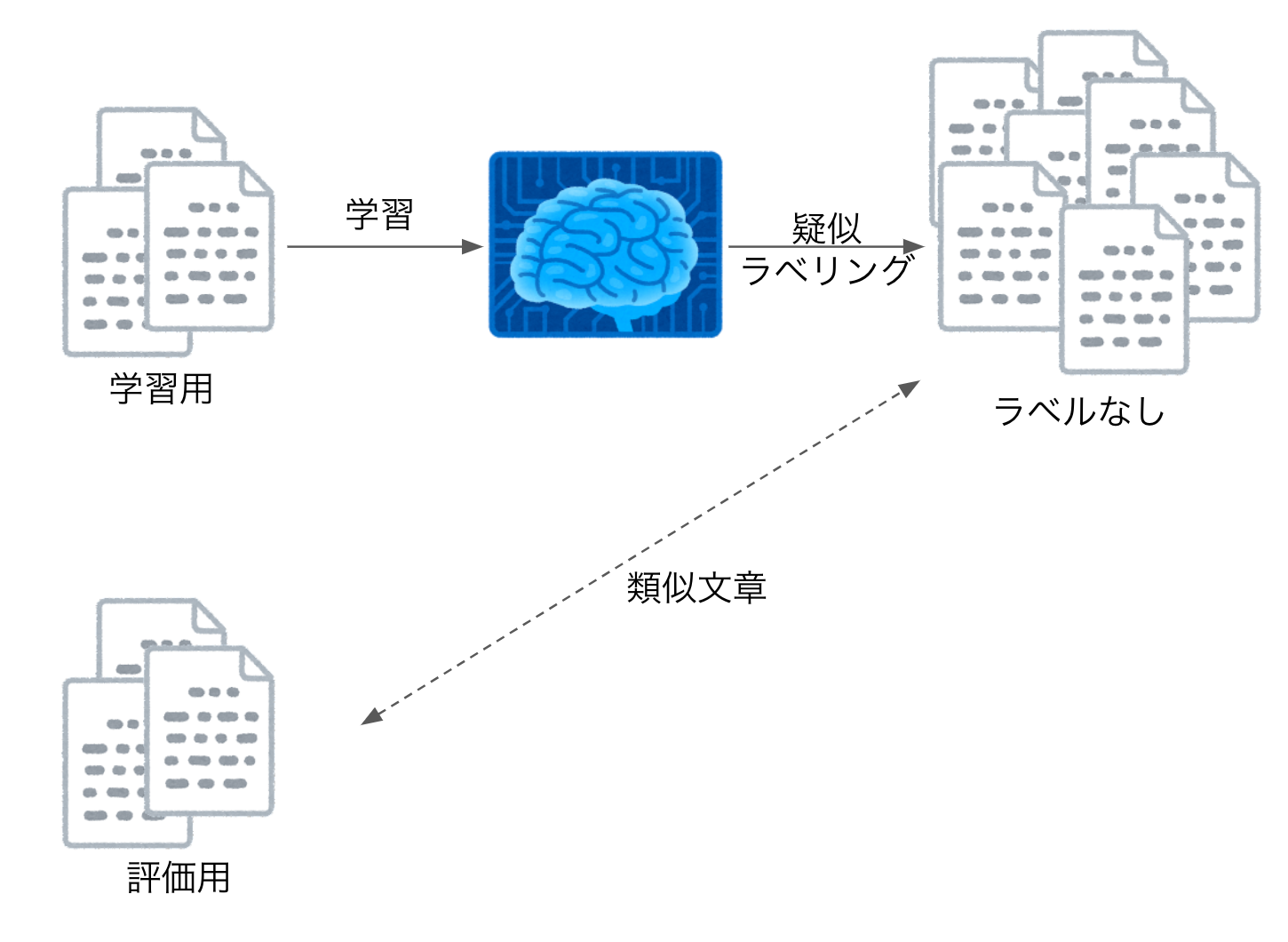
従来、Pseudo Labelingを行う際は、クロスバリデーションの各Foldの予測の平均をとることが一般的ですが、今回の場合、評価データによく似たデータを学習してしまうことになるので、いわゆるleakが発生してしまいます。
クロスバリデーションのFoldごとにPseudo Labelingをすることでこれを回避します。こちらは以前行われていたGoogle QUEST Q&A Labelingというコンペティションの1位の解法に詳しく書かれています。
また、ラベルなしデータの活用方法として、ドメインデータのテキストとしてMasked Language Modelの学習(MLM)を行うという方法もあります。こちらはDon't Stop Pretraining: Adapt Language Models to Domains and Tasksという論文で言及されており、wikipediaなどの一般的な文章で学習されたBERTなどの大規模言語モデルをfine-tuningする前に、解きたいタスクに関係する文章で再度MLMのpre-trainを行うことで精度を向上させることができるという内容になっています。
こちらは、私も試したかったのですが、計算リソースの都合上断念してしましました。上位解法を見てみると多くの方(10位以内はほぼ全員?)が使っていたので、ちょっと無理にでもこちらにリソースを割けばよかったと反省しています。
トークナイザーの特性を考慮した後処理
今回のデータでは、アノテーションの境界線が、トークナイザーで区切られた範囲をとびだしてしまうケースが多くみられました。例えば「67 years old」の67が6と7に分かれてしまったり、「1-2 month」が1と-2に分かれてしまったり、といったケースが多くあります。加えて、今回の問題では回答の位置を文字単位で予測しなければならないので、予測の先頭が改行文字やスペースだったり、ということが考えられます
これらのケースに対応した後処理を行う必要があります。後処理の詳細に関しては4thの解法がとてもわかりやすいコードを載せていただいているのでこちらをご参照いただければと思います。
また、19thや18thなど後処理ではなく、トークナイザーにトークンとして改行コードや空白文字を追加する手法もあったようです。
気づけなかった解法
気づけなかったけど効果的だったと思われる解法について、箇条書きで書いていきます
- [QA CASE=0]のような、症例特徴に合わせた特殊トークンの追加
- 症例特徴から明らかにわかる間違いをフィルタリング
- duration-2-monthsのような症例特徴で2weekやyearを除外する
- 回答ワードだけでなく、回答スパンの始点と終点も予測するマルチラベル予測
- 症例や症例特徴ごとの閾値の調整
- fine-tuning時もMASKトークンを混ぜることでのOverfitの抑制
- LSTMヘッダー
- 今回、かなりアノテーションがノイジーだったのですが、同じワードが繰り返し出現する際に、2回目以降のアノテーションがつけ忘れられている、というケースが多く見られたので、系列考慮ができるRNN系のヘッダーが有効ではないか、という分析がされていました
- FHやPMHなどの医療用語の略語に対応するトークンの追加
- Meta Pseudo Labeling
- すべて小文字で処理する
- EDAで大文字小文字による影響はなかった事がわかった
- AWPやFGMなどのAdversarial training
- augumentation
- orの語順を入れ替える
- アノテーションされていない文章を除外
色々と書きましたが、やはり最初に紹介させていただいた2点が重要だったのではないかな、と考えています。AWPなどは本コンペと関係なく使える手法だと思うので、また機会があれば試してみたいと思います
おわりに
本コンペの結果ですが、Publicでは143位で銅メダル圏内だったのですが、Privarteでは圏外の160位までShakeDownしてしまいました。後処理やモデリングなどは上位解法と大差なかったので、やはりMLMを諦めたのが敗因かな、と考えています。
今回のコンペは
- アノテーションされたデータは少ない
- ラベルなしのデータは沢山ある
- 一般的でない専門用語が含まれる
- アノテーションがノイジー
といった、実務でNLPを扱う際に直面する課題と近い問題設定だったのではないかな、と考えています。まだまだ解法から学べることは沢山あると思うので、もう一度見直して、しっかり復習していきたいと思います。
最後までお読みいただき、ありがとうございました!




