こんにちは AIチームの戸田です。
前回に引き続き、タスク指向対話の開発ツールキット、ConvLab-2を使った対話エージェントのPolicyモデルを強化学習を使って構築したいと思います。
今回の後編では、いよいよPolicyモデルの学習を行います。
ConvLab-2の基本的な使い方や、対話モジュールについては前回の記事をご参照ください。
使用データ
今回学習に使用するデータはMultiWoZ 2.1を使用します。こちらはレストラン検索やホテル検索などのマルチドメインのタスク指向対話用のデータセットで、人間同士の対話にラベル付けをしたものになっています。ConvLab-2ではこれにgreet(”Hello”などの挨拶)やthank(”Thank you”などのタスク完了時の感謝の言葉)などの対話独自の行為を意図として追加しています。
ConvLab-2はパラメータで何のデータセットを使うか指定しない場合、デフォルトでこのMultiWoZ 2.1のデータが設定される仕様になっています。
事前準備
GitHubにあるConvLab-2のリポジトリをcloneしてきて必要なライブラリをインストールします。
$ git clone <https://github.com/thu-coai/ConvLab-2.git>
$ cd ConvLab-2 && pip install -e .
$ python -m spacy download en_core_web_sm上記インストールが完了しましたら、必要なライブラリのインポートを行います。
import torch
import json
import logging
import random
import numpy as np
import pandas as pd
from tqdm.auto import tqdm
from convlab2.dialog_agent.agent import PipelineAgent
from convlab2.dialog_agent.env import Environment
from convlab2.dst.rule.multiwoz import RuleDST
from convlab2.policy.rule.multiwoz import RulePolicy
from convlab2.policy.ppo import PPO
from convlab2.policy.rlmodule import Memory
from convlab2.nlg.template.multiwoz import TemplateNLG
from convlab2.evaluator.multiwoz_eval import MultiWozEvaluator
from convlab2.nlu.jointBERT.multiwoz import BERTNLU
from convlab2.util.analysis_tool.analyzer import Analyzer
from convlab2.util.analysis_tool.example import build_user_agent_bertnlu
本記事の執筆中、コードの実行確認はGoogle Colabで行いましたが、このインポートの前にセッションの再起動が必要なようです。同環境で試される方はご注意ください。
また、グローバルの設定を行います。
# global configuration
class GCF:
SEED = 0
BS = 32
EPOCH = 200
MAX_TURN = 50
OUTPUT_DIR ="/content/test"
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
DEVICEだけ、ConvLab-2の内部でグローバル変数を使っているため、別に定義しています(実装としては少し不安が残りますが、研究用ツールなので今回は目を瞑りましょう)
Policyモデルの学習
学習のために対話のサンプルを取得する関数を定義します。
def sample(env, policy):
buff = Memory()
real_traj_len = 0
sampled_num = 0
while sampled_num < GCF.BS:
# 環境の初期化と初期状態sの取得
s = env.reset()
for t in range(GCF.MAX_TURN):
# 状態sから行動aを取得
a = policy.predict(s)
# 環境にaを流して次の状態を報酬を得る
next_s, r, done = env.step(a)
# 終了フラグ
mask = 0 if done else 1
# 各情報のベクトル化
s_vec = policy.vector.state_vectorize(s)
next_s_vec = policy.vector.state_vectorize(next_s)
a_vec = policy.vector.action_vectorize(a)
# バッファに保存
buff.push(s_vec, a_vec, r, next_s_vec, mask)
# ステップの情報更新
s = next_s
real_traj_len = t
if done:
break
# 対話数を追加
sampled_num += real_traj_len
return buff.get_batch()
対話状態、行動(システム発話)、報酬、次の対話状態、対話が完了しているかのマスク、の5要素がバッチで取得できます。OpenAIのgymを使ったことのある方でしたら馴染みのあるインターフェースなのではないでしょうか。
続けてバッチごとの学習を行う関数を定義します。
def update(env, policy, epoch):
batch = sample(env, policy)
s = torch.from_numpy(np.stack(batch.state)).float().to(device=DEVICE)
a = torch.from_numpy(np.stack(batch.action)).float().to(device=DEVICE)
r = torch.from_numpy(np.stack(batch.reward)).float().to(device=DEVICE)
mask = torch.from_numpy(np.stack(batch.mask)).to(device=DEVICE)
batchsz_real = s.size(0)
policy.update(epoch, batchsz_real, s, a, r, mask)
各モデルの学習は、ConvLab-2のpolicyモジュールに定義されており、updateを呼び出すことで学習を行うことが出来ます。
これで準備は整ったので、各モデルを定義して、学習を実行します。
# システム側の設定
sys_dst = RuleDST() # ルールベースのDST
sys_policy = PPO(is_train=True)
sys_policy.load(GCF.MLE_MODEL) # 事前学習(模倣学習)済みのモデルをPolicyに読み込む
# ユーザー側の設定
usr_policy = RulePolicy(character='usr') # ルールベースのPolicy
simulator = PipelineAgent(None, None, usr_policy, None, 'user')
evaluator = MultiWozEvaluator()
env = Environment(None, simulator, None, sys_dst, evaluator)
# デフォルトのログレベルがDEBUGなので、INFOにする
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# 学習(30分くらいかかります)
for epoch in tqdm(range(GCF.EPOCH)):
update(env, sys_policy, epoch)
Policyの学習には前段階のDSTの情報があればよいので、システム側のNLUやNLGはNoneに設定しており、ユーザー側のパイプラインもPolicyのみ設定されています。
また、今回のPolicyの学習モデルはPPOを使用しています。
模倣学習について
上記学習実行コード中のシステム側の設定の3行目に「事前学習(模倣学習)済みのモデルをPolicyに読み込む」という部分について、少し補足の説明をします。
多くの強化学習アルゴリズムはランダムな行動を初期方策としており、偶然得られた報酬をもとにより良い方策を学習していきます。シミュレーション環境なのでどれだけ間違えても問題ないのですが、非常に時間がかかってしまうのでこれを効率化する手法として模倣学習を使います。
模倣学習の詳細については本記事では触れませんが、以下の論文を読むと理解が深まるかもしれません
- Maximum Entropy Inverse Reinforcement Learning
- エキスパートの行動から報酬関数を予測する逆強化学習の提案
- Deep Q-Learning from Demonstrations
- Atariのゲームで人間のプレイを初期方策とする手法
ConvLab-2ではMultiWoZやCrossWoZなど、提供しているデータセットのtrainデータで模倣学習したモデルを含んでおり、PPOやGDPLといった強化学習アルゴリズムの初期方策としてこれを利用することが出来ます。(※1)
Policyモデルの評価
学習したPolicyモデルを評価してみましょう。ConvLab-2ではAnalyzerというモジュールを使って、学習したモデルの評価を行うことが出来ます。
sys_nlu = BERTNLU()
sys_dst = RuleDST()
sys_policy = PPO(is_train=True)
sys_policy.load(f"{GCF.OUTPUT_DIR}/199") # 一番最後に保存されたモデルを読み込みむ
sys_nlg = TemplateNLG(is_user=False)
sys_agent = PipelineAgent(sys_nlu, sys_dst, sys_policy, sys_nlg, 'sys')
# 評価用のBERT NLUを使ったユーザーエージェントは以下のメソッドで取得できる
user_agent = build_user_agent_bertnlu()
analyzer = Analyzer(user_agent=user_agent, dataset='multiwoz')
analyzer.comprehensive_analyze(sys_agent=sys_agent, model_name='sys_agent', total_dialog=100)
こちらのコードを実行すると以下のような出力が得られます
====================================================================================================
complete number of dialogs/tot: 0.59
success number of dialogs/tot: 0.62
average precision: 0.6630591630591631
average recall: 0.8373737373737374
average f1: 0.7110030822152034
average book rate: 0.7419354838709677
average turn (succ): 14.258064516129032
average turn (all): 20.08
percentage of domains that satisfy the database constraints: 0.846
percentage of dialogs that satisfy the database constraints: 0.740
====================================================================================================
色々な指標が出ていますが、他のモジュールの評価指標(例えばaverage f1などはNLUモジュールの評価指標)もあるので、Policyモジュールの指標となる対話成功率(success number of dialogs/tot)を見てみます。対話成功率はユーザーシミュレータに設定された目的が対話によって達成された数/総対話数で計算され、出力結果では0.62となっています。
学習経過も確認したいと思います。ConvLab-2は学習中のログをDEBUGログとして出力しているのですが、整形されていないため、解析するのが難しいです。なので以下のようなコードで対話成功率のepochごとの推移を可視化してみます。
result = []
epoch = 4
while epoch < GCF.EPOCH:
sys_policy.load(f"{GCF.OUTPUT_DIR}/{epoch}")
sys_agent = PipelineAgent(sys_nlu, sys_dst, sys_policy, sys_nlg, 'sys')
set_seed(GCF.SEED)
res = analyzer.comprehensive_analyze(sys_agent=sys_agent, model_name='sys_agent', total_dialog=100)
res = [epoch] + list(res)
result.append(res)
epoch += 5 # 5 epoch毎にモデルが保存されるので
result_df = pd.DataFrame(result, columns=["epoch", "complete", "success", "precision", "recall", "f1", "book rate", "all turn"])
result_df.set_index("epoch")[["success"]].plot()
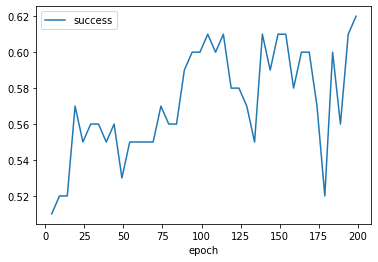
揺れはありますが、epochを経るにつれて徐々に対話成功率が上がっているのがわかります
性能比較
ConvLab-2のREADMEにPolicyモデル以外を
- NLU: BERT NLU
- DST: Rule DST
- NLG: TemplateNLG
に固定した場合の性能比較があったので、Policyモデルが影響する対話成功率(Success rate)を以下に転記します。
| モデル | 対話成功率 |
| 模倣学習(MLE) | 35.9% |
| PPO | 71.7% |
| ルールベース(RulePolicy) | 81.3% |
今回使ったPPOですが、ConvLab-2のREADMEの例ではバッチサイズ1024で学習しているところ、今回はマシンスペックの都合でバッチサイズ32で学習していたので、スコアに差が出てしまったようです。同じスコアを再現するにはバッチサイズに合わせて学習率などを調整する必要がありそうです。とはいえ今回の実験も模倣学習よりは良い精度が出せているようです。
そして注目すべきはルールベース(RulePolicy)でしょう。こちらの比較ではルールベースのPolicyが一番精度が良いという結果になっています。これは現在の対話システムが抱える問題の1つで、高い成功率で動作する対話システムを作るには人の作りこみが必要不可欠なものとなっています。単純に対話を強化学習の枠組みに当てはめるだけではなく、対話独自の特徴などを取り入れた学習方法を考える必要がありそうです。
おわりに
本記事では、タスク指向対話の開発ツールキットConvLab-2を使った、強化学習によるPolicyモデルの学習を試してみました。
PPOを用いた学習を実行することができましたが、単純に強化学習のフレームワークに対話を当てはめるだけでは現状ルールベースのPolicyに劣ってしまうという課題も見えてきました。GDPL(※2)のような対話に特化した強化学習手法もあるので、今後はそういったモデルを試していきたいです。
最後までお読みいただき、ありがとうございました!
注釈:
※1. 模倣学習と通常の強化学習を組み合わせるアプローチは多く取り組まれているようなのですが、ConvLab-2に実装されているpre-trainのような手法はなかなか見つけられず、唯一見つかったのがこちらのGitHub issueでの議論のみだったので、このテクニックを紹介した論文をご存知の方がいましたら教えていただきたいです。
※2. 論文中ではSuccessが86.5%となっており、上記のルールベースを超えていますが、評価データとして使っているMultiWOZのバージョンが古い(1.0)ので、環境を揃えて再現実験をする必要がありそうです。




