こんにちは AIチームの戸田です。
今回はHuggingfaceのライブラリ、transformersのテキスト生成で、XLAを使った高速化を試してみたいと思います。
OpenAI GPTの登場以降、テキスト生成の分野では大規模言語モデルの使用がスタンダードになってきました。要約や翻訳の分野での活躍が期待され、一部のタスクではZero-Shotでの性能も実証されています。
しかし大規模言語モデルはその名の通りモデルのサイズが大きく、学習はもちろんのこと推論にも時間がかかってしまうという課題があります。これはテキスト生成に限らず大規模言語モデルを使用する際の共通課題ですが、テキスト生成においては、より多様な文章を生成するために多く推論を行う必要があります。
こういった傾向からTorch TensorRTやONNXなど、推論の高速化を行うフレームワークが近年多く提案されています。本記事ではその中の一つであるXLAを使った推論の高速化を試してみたいと思います。
XLA

XLAはもともとTensorflowのモデルを高速化するために作られたコンパイラです。近年注目されているJAXのバックエンドやPytorchでTPUの学習を行う際にも使われています。
transformersから使う場合は推論に使用する関数に対してtf.functionでjit_compile=Trueを指定してコンパイルすることで簡単に使うことが出来ます。
以下より実際のコードを見ながら試してみたいと思います。
XLAによる高速化
従来の生成コードは以下のようになります。
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
# グローバル設定
class GCF:
MODEL = "gpt2" # モデル
INIT_TEXT = "Hello, my name is" # 始まりのテキスト。この文に続く文章を生成する
TOKENIZER = AutoTokenizer.from_pretrained(MODEL) # トークナイザ
# tensorflowのモデルと始まりのテキストのテンソル
tf_model = TFAutoModelForCausalLM.from_pretrained(GCF.MODEL)
tf_inputs = GCF.TOKENIZER([GCF.INIT_TEXT], return_tensors="tf")["inputs"]
model_output = tf_model(tf_inputs)
実際のテキスト生成では最終的に出力されたmodel_outputのargmaxを取って、トークナイザーでdecodeする、といった処理が入るのですが、今回は計算時間のみ扱うので省略しています。
こちらのコードに続きXLAで生成を行うため、推論用関数を追加し、jit_compileの設定をします。
def tmp(inputs):
return tf_model(inputs, training=False)
xla_output = tf.function(tmp, jit_compile=True)
model_output = xla_output(tf_inputs)
かなり簡単に書けますね。
速度検証
実際にどの程度早くなったのかを、XLAを使わないTensorflow(以下Tensorflowと表記します), XLAを使うTensorflow(以下XLAと表記します), PyTorchの3パターンで比較してみます。
環境はGoogle ColabのT4で実験しました。
import time
import torch
import pandas as pd
from tqdm.auto import tqdm
from transformers import AutoModelForCausalLM
tf_res = []
for i in tqdm(range(1000)):
time_sta = time.time()
tf_model(tf_inputs, training=False)
time_end = time.time()
diff = time_end- time_sta
tf_res.append(diff)
xla_res = []
for i in tqdm(range(1000)):
time_sta = time.time()
xla_output(tf_inputs)
time_end = time.time()
diff = time_end- time_sta
xla_res.append(diff)
pt_model = AutoModelForCausalLM.from_pretrained("gpt2")
device = torch.device("cuda:0")
pt_model.to(device)
pt_model.eval()
pt_inputs = torch.tensor(GCF.TOKENIZER.encode(GCF.INIT_TEXT)).to(device)
pt_res = []
for i in tqdm(range(1000)):
time_sta = time.time()
with torch.no_grad():
pt_model(pt_inputs)
torch.cuda.synchronize()
time_end = time.time()
diff = time_end- time_sta
pt_res.append(diff)
res_df = pd.DataFrame(zip(tf_res, xla_res, pt_res), columns=["Tensorflow", "XLA", "PyTorch"])
res_df.head()
1000回生成を行いましたが、全て確認するのはスペースの都合上難しいので、最初の5回だけ推論時間を見てみます。
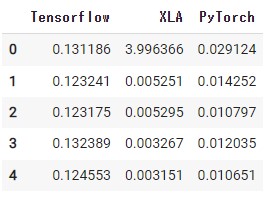
2回目以降をみるとXLAが圧倒的に早そうですが、最初の1回にかなり時間がかかっているようです。これはXLAのコンパイルが、その関数が呼び出された際に行われるためです。
かかった時間の累積結果を見てみます。
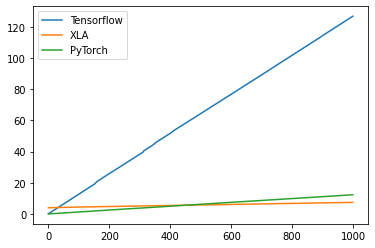
従来のTensorflowに比べると圧倒的に早くなっているのがわかります。Huggingfaceではその柔軟性からeagerモードをベースにコードが書かれていますが、graphモードと比べると実行時間が大きく遅れるようなので、これが原因ではないかと考えています。Tensorflowのモードについてはこちらの記事に詳細がありますので、詳しく知りたい方はこちらをご参照ください。
PyTorchとXLA比較すると、最初のコンパイルの時間で少しハンデがありますが、500回目くらいで逆転しているのがわかります。500文以上生成するケースではXLAを使った方が良さそうですね。
ちなみに今回は同じ文からの生成で試していますが、実際はいろいろな文からの生成を試したいと思うので、パディングを使って入力テンソルをそろえてあげる必要があります。 詳細は、本記事でも参考にさせていただいたhuggingfaceのブログ記事にサンプルコードと一緒に解説が載っていますので、こちらをご参照ください。
おわりに
本記事ではtransformersの大規模言語モデルのテキスト生成で、XLAを使った高速化を試してみました。以前公開されたrinna社の13億パラメータのGPTなどを利用する際は使ってみたいです。
最後までご覧いただきありがとうございました!
追記(2022.10.14)
Tensorflowのモデルで予測するときにtrainingパラメータをFalseに設定していなかったのと、TensorflowのGraphモードでの推論を試していなかったので追加実験しました。
状況コードの該当箇所を修正しています。また、Graphモードでの推論の追加部分は以下になります。
tf_output = tf.function(tmp) # XLAで使った関数を利用
tf_res_compile = []
for i in tqdm(range(1000)):
time_sta = time.time()
tf_output(tf_inputs)
time_end = time.time()
diff = time_end- time_sta
tf_res_compile.append(diff)結果は以下のようになりました。
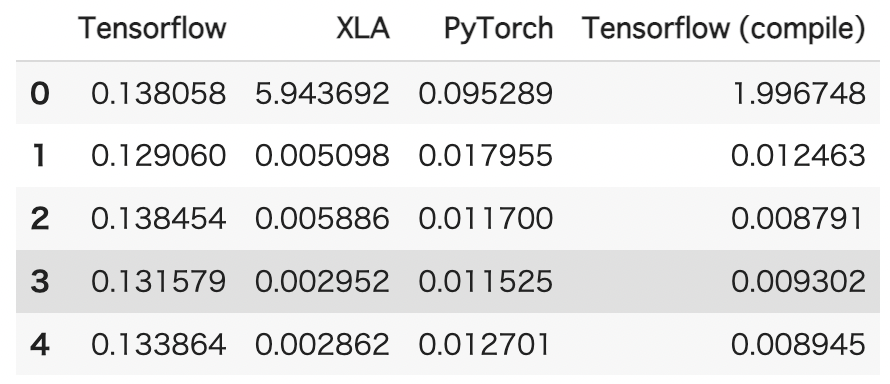
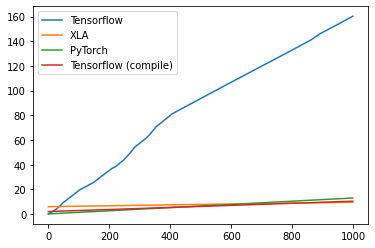
PyTorchよりはやや高速ですが、やはりXLAの方が高速ですね。




