こんにちは!AIチームの二宮です.
本記事はAI Shift Advent Calendar 2022の2日目の記事です.
本記事では,チャットボットの一機能であるFAQ検索の概要と,関連する論文紹介を行いたいと思います.紹介するのはスマートデバイスの研究開発で有名なHuawei ResearchのAssemらによる論文で,SIGDIAL2021で発表されました(論文はこちら).
FAQ検索について
背景
ユーザの疑問に答えるようなチャットボットの機能の一つに,よくある質問集FAQ(Frequently Asked Questions)から回答を検索する機能があります.弊社が提供するチャットボットでもこのFAQ検索機能が搭載されています.
このFAQ検索の仕組みは類似文書検索をベースとしていることが多く,(1)単語の表層形に着目した検索(e.g. BM25)と,(2)文の意味に着目した検索(e.g.BERT)があります.近年は機械学習モデルの発展に伴って後者が採用されることが多く,現在も研究が盛んに行われています.
FAQ検索の問題設定
FAQ検索タスクは,ユーザ発話に対して最も関連するFAQを選択するタスクであり,FAQはそれぞれ質問と回答のペアからなります.例えば,
- ユーザ発話:マイページへの入り方を教えて
- FAQ_1
- 質問:ログイン方法について
- 回答:ホームページの右上のボタンをクリックしてください....
- FAQ_2
- 質問:銀行振り込みについて
- 回答:まずお送りしたメールに記載されているリンクをクリックしてください....
といった例を考えてみます.
(実際はFAQ_1, FAQ_2, ...と数十件から数百件程度のFAQが存在します.)
この場合,ユーザ発話に最も類似するFAQの質問は,FAQ_1の「質問:ログイン方法について」であると考えられるため,システムは回答としてFAQ_1の回答を出力します.このように,一般的にFAQ検索ではユーザ発話に最も類似するFAQの質問を検索することで回答を選択しています.
さらに,FAQ検索の精度を高めるための工夫としてよく行われている方法として,1質問に対して複数の言い換え表現(拡張質問)を登録しておくというものです.例えば,
- FAQ_1の質問:ログイン方法について
- 拡張質問1_1:ログインの仕方について
- 拡張質問1_2:マイページへ入る方法
- FAQ_2の質問:銀行振り込みについて
- 拡張質問2_1:銀行に自動で送金したい
- 拡張質問2_2:お金を振り込みたい
のように拡張質問を登録しておくことで,先例のように「マイページへ入る方法」と質問された場合でも拡張質問を検索することで,適切にFAQを選択できる可能性が高くなります.まとめると,FAQ検索のために(質問,拡張質問,回答)を組とするFAQのデータベースによってFAQ検索の準備が整います.
論文について
FAQ検索に関して,今回はHuawei Researchの研究の紹介をしたいと思います.
論文の要点
- FAQ検索はオープンドメイン質問応答と比べてユーザの質問が短文で入力される傾向にあるため,質問の語彙情報と詳細な意味情報を別々のモジュールで分けて捉えることが有効である.
- Assemらが提案するDTAFAは,これらを別々に捉えるように学習させたモデルであり,計算コストを抑えつつ,高い精度でFAQ検索を行うことができる.
- DTAFAは多言語で学習させることもでき,グローバル事業への応用可能性も示唆される.
提案手法DTAFA
AssemらはFAQ検索モデルであるDTAFA (Decoupled Training Architecture for FAQ Retrieval)を提案しています.DTAFAは(1)質問の語彙情報と詳細な意味を分けてモデル化しており,(2)多言語での学習にも対応しているという特徴があります.
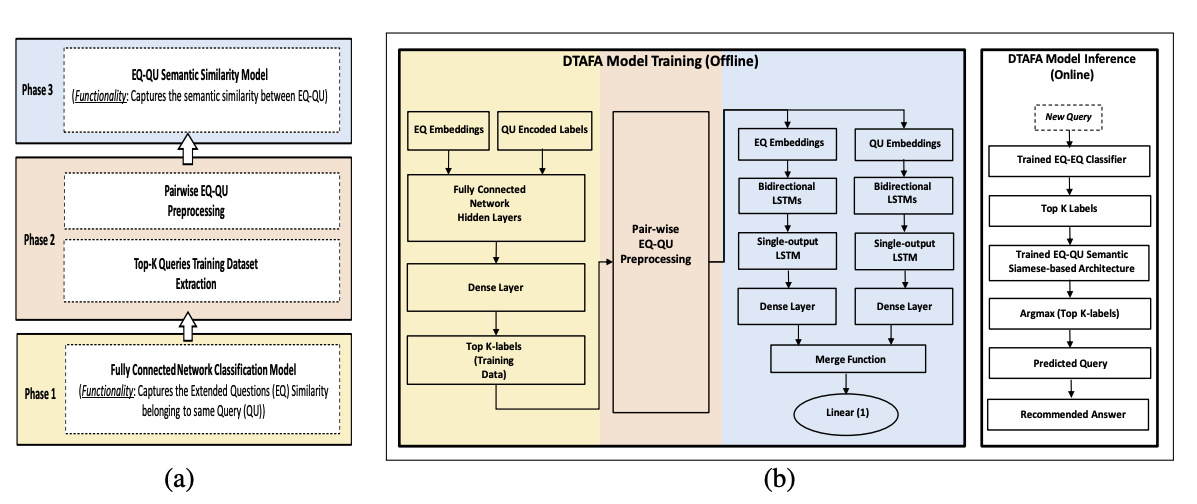
DTAFAの学習は3つのPhaseからなります.
Phase1:拡張質問検索モデルの学習
図の黄色に該当します.拡張質問から対応するFAQの質問を推測するように学習させることで,ユーザ発話に対してどのFAQの質問を返すべきか推論する分類モデルを獲得します.これが,質問の語彙情報を特定する役割を担っており,後段の意味的検索モデルがより詳細な意味に着目するために役立っています.分散表現はLASERを用いて作成しており,分類モデルは2層ニューラルネットで構成されます.
Phase2:意味的検索モデルの学習データの前処理
図のオレンジに該当します.Phase1で獲得した分類モデルを用いて,拡張質問からFAQの元の質問を推論します.これにより,拡張質問それぞれに対してFAQの元の質問の確率分布を表す分類スコアを得ることができます.これをPhase3の意味的検索モデルの学習に教師信号として利用することで,過学習の抑制に繋がります.
Phase3:意味的検索モデルの学習
図の青色に該当します.Phase2で得られた分類モデルの分類スコアがこのPhase3に与えられることになります.ここでの意味的検索モデルは意味的に重要な違いを認識する役割を担っており,LSTMベースのSiamese-network(回帰モデル)で構成されます.BERT等と比べてパラメタ数を大きく削減することに成功しており,推論時間の低減などを見込めます.
推論処理
図(b)の右端に該当します.まずPhase1の分類モデルで語彙情報を捉え,上位K件(実験ではK=45がベスト)のFAQの質問を選択します.その後,Phase3で獲得された意味的検索モデルでそれらの中から最も意味的に類似するFAQの質問を選択し,最終的にそれに対応するFAQの回答を出力します.
実験
(1)Enterpriseデータセットと(2)StackExchange FAQデータセットを用いて実験を行っています.
- Enterpriseデータセット:Huawei社がモバイルサービスにて収集したデータセット.13言語からなり,FAQの質問は336件からなる.それぞれの質問に対して平均15件の拡張質問が存在する.
- StackExchange FAQデータセット:公開されているFAQに関する英語データセット.機械翻訳を用いることで他12言語分のデータセットが用意されている.
英語における評価
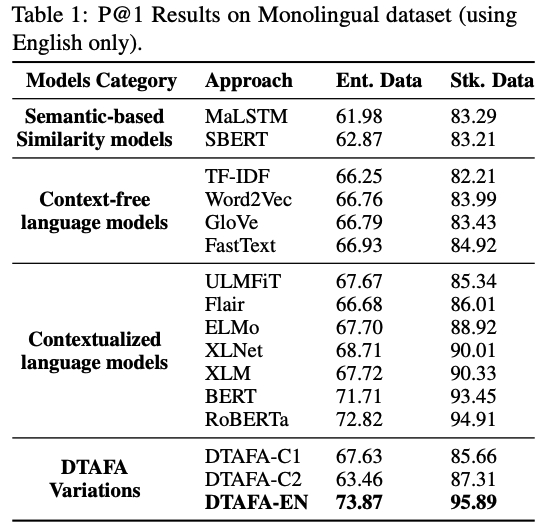
提案手法であるDTAFA-ENが両方の実験において高い性能を示しています.
また,Semantic-based Similarity modelsが比較的低い性能となっていますが,これは多様なFAQをまとめて意味的検索モデルを学習していることが原因であると考えられるため,やはり事前に語彙情報をもとに検索対象となるFAQの質問を限定しておくことが重要なことがわかります.(Sentence-BERTでも性能が低い点には驚きました.)
Contextualized language modelsであるRoBERTaは高い性能を示していますが,Siamese-networkと異なりユーザ発話とFAQの質問を1文にしてRoBERTaに与える必要があるため,推論コストが大幅にかかります.一方でDTAFAの場合はRoBERTaと比べて30分の1程度のパラメタ数であるため推論コストが非常に小さく,検索精度もRoBERTaより1%程度高い値を達成しています.
多言語における評価
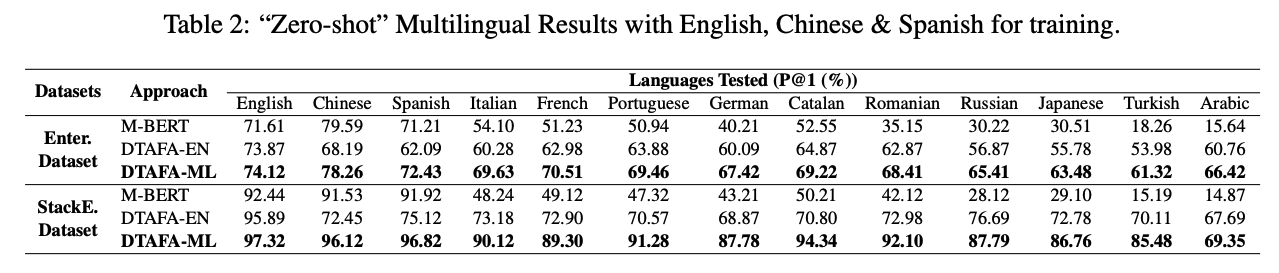
多言語版の提案モデルであるDTAFA-MLは,英語・スペイン語・中国語の3言語を用いて学習させたモデルです.結果,両方のデータセットの実験において,全言語でDTAFA-MLが最も高い性能を示しました.さらに,Assemらの実験ではスペイン語で学習させた場合はポルトガル語やルーマニア語における性能が向上することがいわれています.そのため,言語的な特徴が類似する場合はユースケースに応じて学習に用いるデータセットの言語を変えると良いそうです.グローバル事業では多言語対応したシステムが必要となるので,DTAFAの応用範囲の大きさが窺えます.
まとめ
本記事ではAssemらの論文 "DTAFA: Decoupled Training Architecture for Efficient FAQ Retrieval"の紹介を行いました.FAQ検索においてAssemらの提案するDTAFAでは,(1)質問の語彙情報を捉える役割と意味的な内容を捉える役割を分けたモデル化が有効であり,(2)グローバル事業での利用を念頭に多言語で学習しているという特徴があることがわかりました.
弊社が提供するチャットボット・ボイスボットでもFAQ検索の性能向上のために日々工夫を行っています.今後もFAQ検索に重要な技術を追いつつユーザにとって使いやすい機能の実現に努めて参ります!
ここまでお読みいただきましてありがとうございました!
明日はバックエンドチームの須永から,gRPC Streamingの負荷テストについて紹介を行う予定です!




