はじめに
こんにちは、AIチームの杉山です。
本記事はAI Shift Advent Calendar 2022の7日目の記事です。
今回の記事では音声対話システムにおける課題の一つであるユーザー発話からのエンティティ解決に関する研究として、Amazon AlexaチームがINTERSPEECH 2022に投稿したPhonetic embedding for ASR robustness in entity resolution[1]という論文を紹介します。
音声対話システムにおけるエンティティ解決の課題
現在の音声対話システムでは、ユーザーの発話を音声認識してテキスト化し、そのテキストに対して発話意図理解やエンティティ解決を行なって対話状態を遷移させるパイプライン形式が一般的です。
その一部であるエンティティ解決モジュールでは、音声認識結果のテキストを入力クエリとして、エンティティ集合(地名:東京、大阪、・・・etc.)に対して検索などを行い入力の中から対話システムが期待するドメインに関連するエンティティを解決します。しかし、その検索の精度は、検索ロジックの良し悪しだけでなく、入力クエリの質に影響されます。特に音声対話システムの場合では、クエリの質は音声認識の精度やユーザーの発話内容(フィラーが含まれていたり、テキスト入力と比較してまとまっていない内容になるなど)に大きく影響を受けます。
これらの誤りを含む入力クエリによる悪影響として、検索対象のエンティティ集合から正解のエンティティを抽出することができなくなったり、不正解のはずの別のエンティティを抽出してしまうといった問題を引き起こす懸念があります。
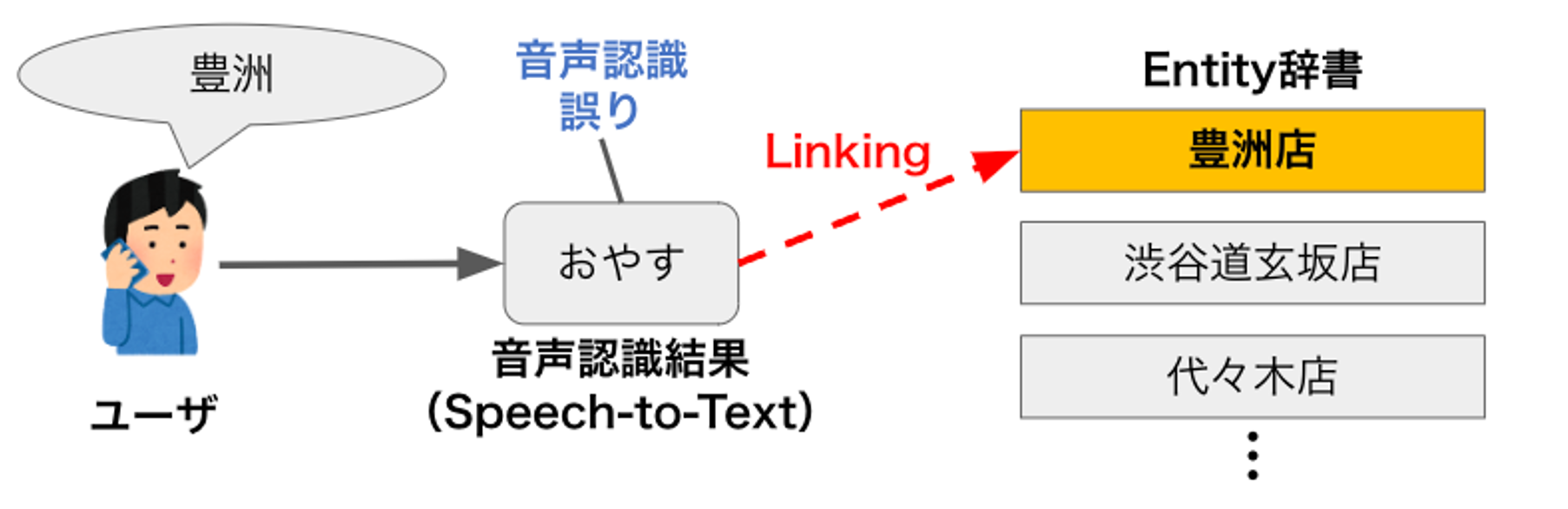
私たちのチームでもこれらが音声対話システム、特にタスク指向対話での音声対話において大きな問題になることを認識しており、いくつかの手法を研究・発表していますが[2]、未だ試行錯誤を続けている途中です。
先行研究
音声認識誤りを除去する方法は様々提案されています。
例えば、文字レベルでの曖昧検索を用いることで、"shipping potato" と "chip and potato" のように音的に似たフレーズを見つけることができます。しかし、"by/buy/bye", "know/no", "eye/I", 日本語であれば"はい/タイ"など、音は似ているが表記が異なる単語は考慮することができません。
別の方法では、単語のスペルではなく、発音(音素)を用いてマッチングを行う音素検索(n-gramを用いる方法)があります。これは、異表記語や発音が似ている単語の検索空間を広げることができます。しかし、音素検索ではどの音素がより似ているのかを判断できないため、発音の表現に限界があるといった問題点があります。例えば、"ban", "van", "can "はそれぞれ音素(XSAMPA [3])"b { n", "v { n", "k { n "に変換されますが、互いの編集距離は全く同じになります。しかし、"ban "と "van "は "can "よりも発音が似ていて音声認識的にも間違われやすいことがわかっています。
また、音素検索は下流タスクでリランキングする候補が増えるため、問題が難しくなり精度が低下する可能性があります。
その問題に対し、可変長のクエリを発音に基づいた固定次元のベクトルに変換する音声埋め込みも提案されています[4][5]。音声埋め込みでは、発音の類似性はそのままベクトル距離に反映されるため、その一手法である音素埋め込みはn-gram検索に比べて長いクエリをより適切に表現することができると考えられます。
また音素埋め込みベクトルはword2vecなどの意味埋め込みベクトルと合成して、同じNeural Vector Search(ニューラルベクトル検索、以降NVS)の仕組みに組み込むことができるため、リランキングのための検索候補空間の次元が爆発的に増大するのを避けることができるといったメリットもあります。
今回紹介する論文の手法では、音素のばらつきに頑健な類似度計算に焦点を当て、入力クエリとエンティティ集合の両方の音素を埋め込みモデルの入力として使用しています。
これにより、音声認識の中間出力、例えば音素埋め込みやE2E音声認識の中間層などに対する依存性を低減することができます。同様の発想の適用先として、機械翻訳[6]やNLU[7]における音声認識の頑健性向上など、音響入力のない音声埋め込みをNLPタスクに適用した取り組みがいくつかありますが、エンティティ解決に適用・検証した例はありませんでした。
提案手法
今回の論文では、大きく以下の3つの手法が提案されています。
Neural Vector Search
エンティティ解決モデルの学習には距離学習の一手法であるSiamese Network[8]を使用し、クエリとエンティティの距離を学習することで音素を用いないナイーブな意味埋め込みベクトルでのNVSのベースラインとして使用します。入力ベクトルの獲得にはBERTを用いており、NLIとSTSのデータセットでpre-trainしたのちにドメイン固有のデータセット(後述)でfine-tuningしたモデルを用いています。
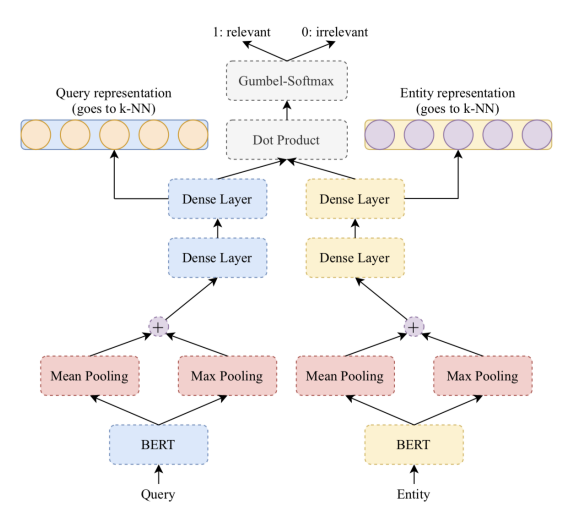
図は元論文より引用
Phonetic Embedding Models
ベースラインのNVSが一定の精度を出したことから、音素埋め込みベクトルも組み合わせて使用することを考えます。
音素埋め込みベクトルの学習には、図のBERTの箇所を2層のbi-LSTMに置き換えた同様のSiamese Networkを用います。(音素の語彙サイズは50)
Combining Phonetic and Semantic Embedding
音素埋め込みと意味埋め込みの組み合わせには、あらかじめ定義した比率βで加算するWeighted Sumモデルを用います。両埋め込みを同じ次元に対応させるため、意味埋め込みには1層のDNNを適用しています。
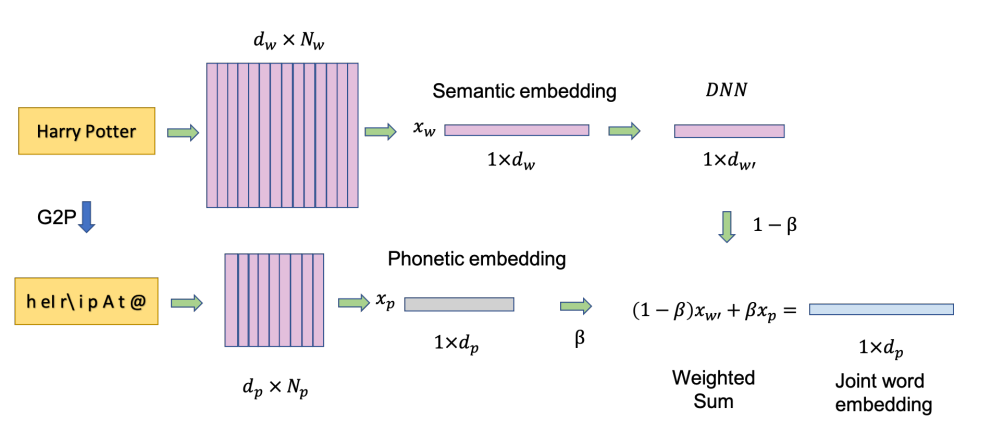
図は元論文より引用
データ
学習データとテストデータ
この論文では、前章で述べた手法の紹介だけでなく、独自の音声検索データセットを構築しています。
動画音声検索のドメインで、ユーザーの発話とクエリに対する検索結果のペア(Query Result Pair: 以降QRP)からなり、ユーザーが検索結果を選択したかどうかの正誤のラベルがついています。
データのクオリティを高めるためのフィルタリング機構を挟んだのち(詳細は論文をご確認ください)、約1000万件のクエリと検索結果のペアをランダムサンプリングし、正誤それぞれのラベルの件数を揃えて学習データとしました。また、fine-tuningのためのテストセットとしてそのうち1/10を再度ランダムサンプリングしています。
データ拡張
エンティティ解決に音素埋め込みを用いる主な目的は音声認識誤りに頑健にすることなので、作成したQRPに加えて音声認識モジュールの出力結果N-best(N=5)から正誤のペアを作成し、音声認識結果のN-bestに対し間違いやすいものと正解のペアを作成します。また、他の出力結果からランダムサンプリングしたものと正解のペアを負例とし、正誤どちらのペアに対しても拡張を行います。
また、書籍の音声検索結果からもデータセットを構築しています。こちらに関してはクエリの正規化を行うことでデータを作成します。
例えば、最初に音声認識で"Harry Pot"と認識され、そのクエリではエンティティが解決できなかった場合に、その次のターンで"Harry Potter"と認識され希望する結果が返されると、どちらのクエリも正解エンティティは"Harry Potter"とみなすことができ正例のQRPとします。負例については、動画音声検索と同様にランダムサンプリングしたクエリを用います。
こちらはデータ拡張をおこなっておらず、このデータをテストデータとして用いることで、意味埋め込みや音素埋め込みが語彙検索のベースラインからどの程度改善できるかを確認することができます。
実験・評価
エンティティ解決における音声認識結果への頑健性をテストするために、以下のパターンで実験を行ないます。
- no variation
クエリとエンティティが辞書的に完全に一致するパターン - phonetic variation クエリとエンティティの音素編集距離が5以下のパターン。さらに次のように細分化する。
- spoken-wirtten variation
エンティティをwritten-to-spokenトークナイザーでクエリに変換したパターン - heterographs
同じ音素(G2Pツールで生成)だが、異なる表記のパターン - phone variation
クエリとエンティティの音素編集距離が1以上5以下のパターン
- spoken-wirtten variation
- lexical variation クエリとエンティティの音素編集距離が5より大きいパターン、さらに次のように細分化する。
- over-specification
query has more words than the entity
クエリがエンティティより単語数が多いパターン - under-specification
クエリがエンティティより単語数が少ないパターン - word variation
クエリとエンティティの音素編集距離が5以上の他のパターン
- over-specification
- no match
正解エンティティが存在しないパターン
実験
意味埋め込み、音素埋め込み共に、それぞれの埋め込みベクトルをエンティティ解決に適用し、近似近傍探索ライブラリFAISS[10]を用いてベクトル検索を行います。
動画検索、書籍検索データについて以下の5パターンの検索方法で実験を行ない、結果はそれぞれ表のようになりました。
- baseline (語彙検索)
辞書検索で上位50位までの候補を取り出し、動画や書籍の人気度を示す重要度スコアでリランキングを行う。 - phonetic search
語彙検索と音素検索で上位50位までの候補を検索し、重要度スコアでリランキングを行う。語彙検索と音素検索は、いずれもElasticsearchを用いた標準的な情報検索手法で行っています。 - NVS
意味埋め込みでのNVSと語彙検索を別々に行い、重要度スコアで上位50位までの候補のリランキングを行う。 - NVS+phonetic
QPRのみで学習した意味+音素の結合埋込みと、語彙検索を別々に行い重要度スコアで上位50位までの候補のリランキングを行う。 - NVS+phonetci+data augmentation
10%のASR N-best拡張データと90%のQRPを混ぜて学習した意味+音素の結合埋込みと語彙検索により上位50位までの候補のリランキングを行う。こちらの手法は動画検索データに対してのみ行った。
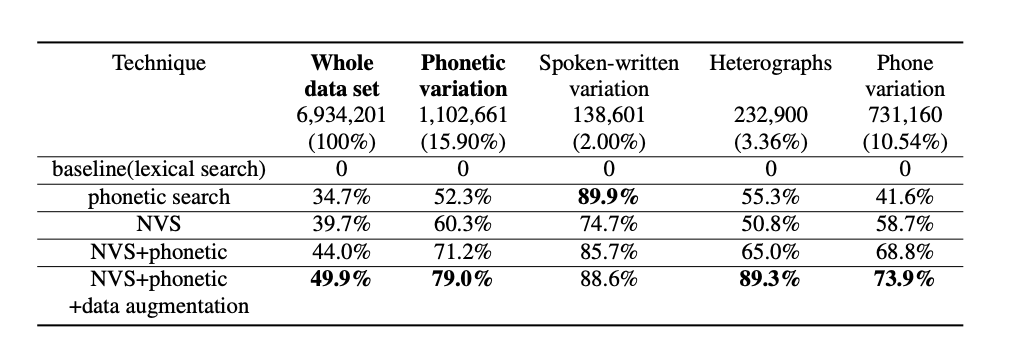
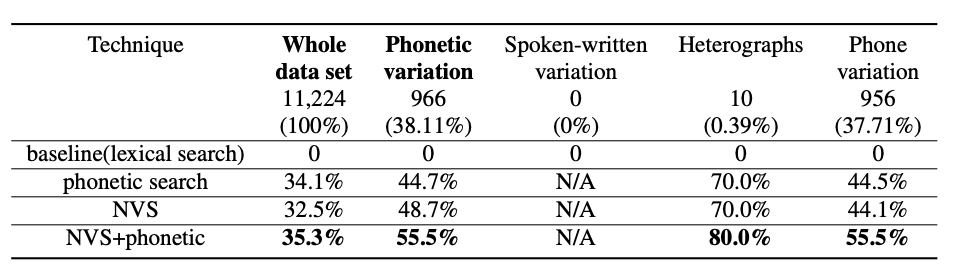
表の結果は、recall@5に対するベースラインからの相対的なエラー削減(ベースラインは0)です。また、音声認識結果のバリエーションがある可能性が高いクエリに対してこれらの技術がどのように機能するかを具体的に示すために、先述のように音素のバリエーションサブセットでもテストを行なっています。("Phonetic variation"は”Heterographs”・”Spokenwritten variation”・”Phone variation”の3つの列の合計)
評価
語彙検索のベースラインと比較して、動画検索データセットでは音素埋め込みにより音素バリエーションサブセットでの誤り率を71.2%、全テストセットでの誤り率を44.0%軽減し、書籍検索データセットでは音素バリエーションサブセットで誤り率を55.5%、全テストセットで35.3%エラー率を軽減しています。また音声認識結果のN-bestによるデータ拡張ではさらに動画検索データセットでの誤り率を79.0%、全テストセットで49.9%軽減し、音素情報は検索タスク、特に音素が変化したようなクエリに有効であることが示されました。
おわりに
今回の記事では、音声での検索を題材として音素情報と音声認識結果のN-bestを用いてエンティティ解決を行う研究を紹介しました。AI Messenger Voicebotでもユーザーの音声発話に対して人名や店舗名などのエンティティを認識・解決する必要があるシーンは多いため、大変参考になりました。日本語の音素でも同等の結果を出すことができるかはわかりませんが、手法自体はかなりシンプルなのでプロダクトの日本語音声データでも試してみたいと思いました。また、音素列に対する埋め込みベクトルの学習部分がシンプルだった点に対しPhoneme-BERT[10]などリッチな埋め込み表現を適用した時の結果も気になるため、調査してみたいと思います。
ここまで読んでいただきありがとうございました。明日はAIチームの東より音声認識モデルのWhisperについての記事が出る予定です。こちらもご覧いただけると幸いです。
引用・参考
[1]https://assets.amazon.science/7a/43/208b36704ed28a25dd6255d2d2cf/phonetic-embedding-for-asr-robutness-in-entity-resolution.pdf
[2]https://www.ai-shift.co.jp/techblog/2625
[3] J. C. Wells, “Computer-coding the IPA: a proposed extension of
SAMPA,” 1995.
[4]A. Haque, M. Guo, P. Verma, and L. Fei-Fei, “Audio-linguistic
embeddings for spoken sentences,” 2019.
[5]Y.-C. Chen, S.-F. Huang, C.-H. Shen, H. yi Lee, and L. shan Lee,
“Phonetic-and-semantic embedding of spoken words with applications in spoken content retrieval,” 2019.
[6]Hairong Liu, Mingbo Ma, Liang Huang, Hao Xiong, and Zhongjun He, “Robust Neural Machine Translation with Joint Textual and Phonetic Embedding.” 2019.
[7]A. Fang, S. Filice, N. Limsopatham, and O. Rokhlenko,“Using phoneme representations to build predictive models robust to ASR errors,”, 2020.
[8] S. Chopra, R. Hadsell, and Y. LeCun, “Learning a similarity metric discriminatively, with application to face verification,” , 2005
[9]https://faiss.ai/
[10]M.N. Sundararaman, A. Kumar, and J. Vepa, “Phoneme-bert: Joint lan- guage modelling of phoneme sequence and asr tran- script.” 2021




