こんにちは!AIチームの戸田です!
本記事では私がKaggleのコンペティションに参加して得た、Transformerをベースとした事前学習モデルのfine-tuningのTipsを共有させていただきます。
以前も何件か同じテーマで記事を書かせていただきました。
- Kaggleで学んだBERTをfine-tuningする際のTips①〜学習効率化編
- Kaggleで学んだBERTをfine-tuningする際のTips②〜精度改善編〜
- Kaggleで学んだBERTをfine-tuningする際のTips③〜過学習抑制編〜
- Kaggleで学んだBERTをfine-tuningする際のTips④〜Adversarial Training編〜
今回はラベルなしデータの活用について書かせていただきます。
ラベルなしデータ
世の中の様々な問題を、蓄積された大量のデータを使った教師あり学習で解こうとする試みは多くなされていますが、教師あり学習を行うためにはデータのアノテーションが必要になります。アノテーションは人手で行う必要があるのでコストが発生してしまい、「人手を削減したくてAIを導入したいのに、導入のために人手が掛かってしまう」というジレンマが起こってしまいます。
近年のKaggleでは、少量のアノテーションされたデータと大量のアノテーションされていないデータが配布されるコンペティション(NBME - Score Clinical Patient Notesなど)であったり、過去に同じオーナーが類似するコンペティションを開催しており、その時のデータを使ってもよいとされているコンペティション(Feedback Prize - Evaluating Student Writingなど)がよく開催されています。「データは沢山あるけど、アノテーションされたデータは少量しか用意できない」という現状に近い問題設定だと思います。
本記事では、こういった状況でアノテーションされていないデータ(以下ラベルなしデータ)を活用してスコアを上げていく工夫を紹介していきたいと思います。
Pseudo Labeling
Pseudo Labelingは所謂半教師あり学習(semi-supervised learning)の一種で、その名のとおり、ラベルなしデータに擬似的にラベルをつける手法になっており、元々は画像認識の分野で出てきたこちらの論文が元ネタになります。
こちらのサイトが非常にわかりやすい図を提供していたので引用させていただきます。

手法の流れとしては大きく3ステップになります。
- 少量のラベルづけされたデータで学習
- 1で学習したモデルを使ってラベルなしデータのラベルを予測
- 2で予測されたラベルをラベルなしデータのラベル(=擬似ラベル)として、もとのラベルづけされたデータと混ぜて学習
これに続いて3で学習したモデルを使ってラベルなしデータのラベルを再度予測して、そのデータを使って擬似ラベルを作って学習して...と、このサイクルを繰り返します。
擬似ラベルは間違ったラベルもつけられてしまいますが、Pseudo Labelingはある種の正則化の効果があるとされており、教師あり学習で学習するデータ数が少ない際に引き起こされる過学習を軽減してくれると言われています。
元論文のこの図ではMNISTの予測結果と特徴量をt-SNEで二次元に圧縮してプロットしています。

Pseudo-Labelを使ったもの(b)の方が、各クラス間の境界部分が疎になっている(綺麗に分割できている)ように見えます。
擬似ラベルはモデルの出力値をそのまま使うソフトラベルと、出力値から離散的なラベルに変換して使うハードラベルの2種類があり、タスクやドメインによって適切なものが異なります。(※個人的な印象ですが、ソフトラベルの方が効果的なケースが多いように感じています)
K-Foldを使う時の注意点
K-Foldで学習して、最終的に各Foldの平均値を予測結果として使うようなケースでpseudo labelingを行う際はleakに注意する必要があります。
3 Foldで分割して擬似ラベルを作るケースを例として説明します。
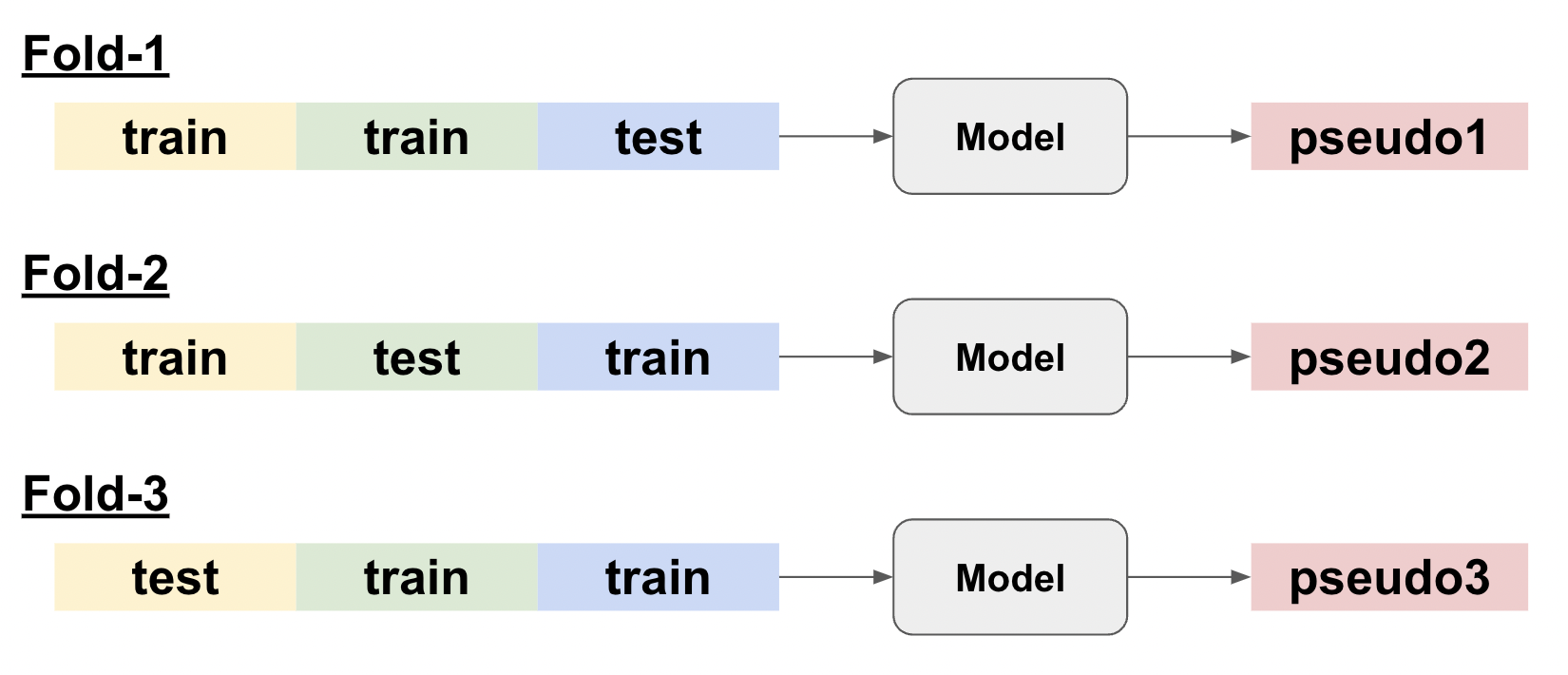
ここでFold-1で作られた擬似ラベルpseudo1は黄色と緑色のデータを学習してしまっているので、緑色がテストデータのFold-2や黄色がテストデータのFold-3の学習で使ってしまうと、答えを知っていることとなり、必要以上に評価が高くなってしまいます。
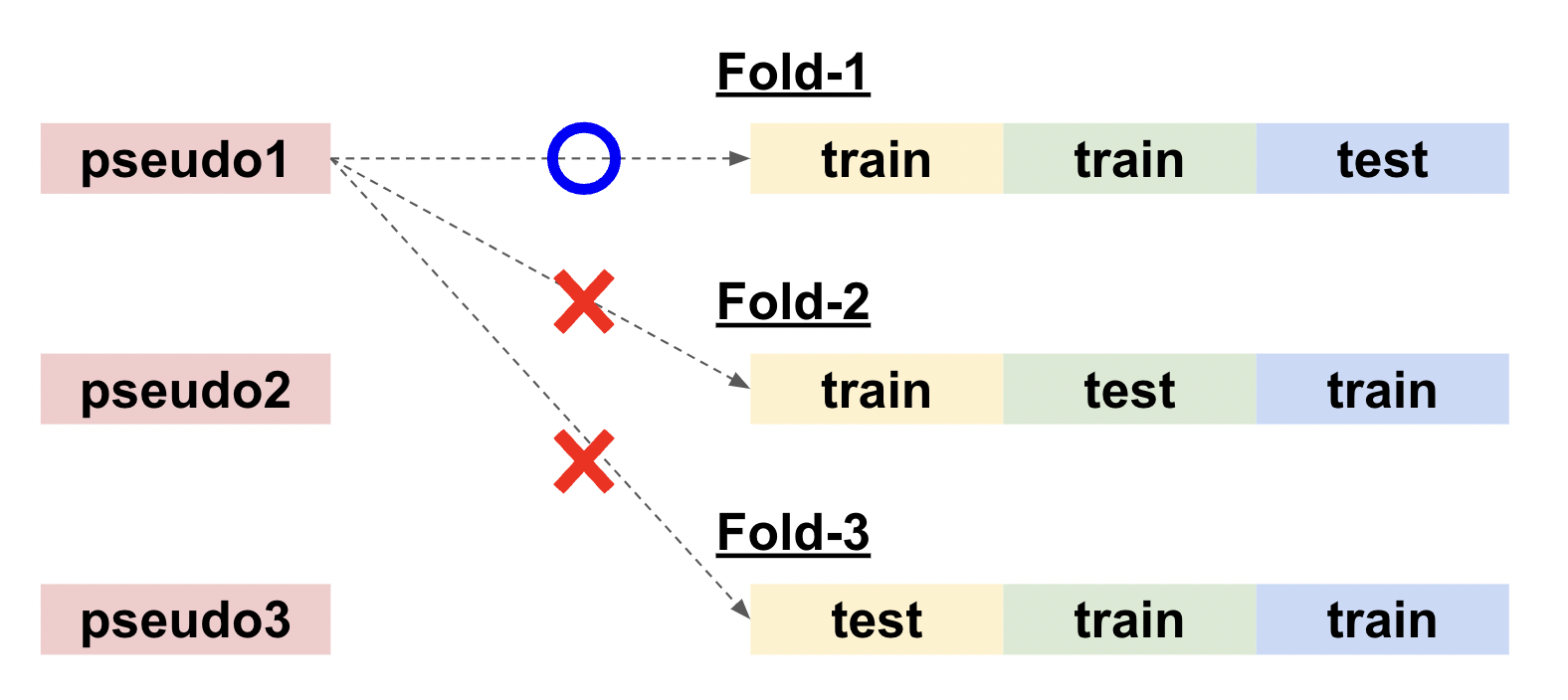
よくあるミスとして、各Foldで予測された擬似ラベルの平均値(もしくは多数決)をとってしまうケースがあります。K-FoldのAverage Ensembleとよく似ていますが、やはりテストデータを学習した予測結果を使ってしまっており、特に類似するテキストが多いタスクでは酷いleakが発生してしまいます。(私はNBME - Score Clinical Patient Notesに参加したときこのミスをしてしまい、大きくShake Downしてしまいました。)
K-FoldでPseudo Labelingを行う際は、Foldを混ぜないように気をつけるようにしましょう。
MLM
BERTやRoBERTaなどの事前学習済みのTransformerモデルは、WikipediaやBookCorpusなどの一般的なドメインのコーパスを使って、MLM(Masked Language Modeling)で事前学習されていますが、解きたいタスクの言語の分布とはやや異なる場合が多いです。

ここでのMLMはタスクやドメイン固有のデータに対して、再度MLMで学習することで、それによりモデルの性能を向上させようとする手法になります。この論文やこの論文で提案・評価されています。
ラベルなしデータによるMLMは、厳密には学習させるデータの種類によって以下の3種類に分類されます。
1. Within-task pre-training (ITPT) :
解きたいタスクの学習データを使用する。つまりラベルづけされた教師データや同じところから取得されたが、まだアノテーションされていないラベルなしデータからMLMの学習をする。
2. In-domain pre-training (IDPT) :
解きたいタスクと同じドメインのデータを使用する。例えばlivedoorニュースコーパスでニュース記事分類を行う際に、別のニュース記事分類のオープンデータを取得してMLMの学習を行う。
3. Cross-domain pre-training (CDPT) :
ドメインもタスクも異なるデータでMLMの事前学習を行う。
Meta Pseudo Labels
最後に紹介するのは、Pseudo Labelingに蒸留のテクニックを導入したMeta Pseudo Labelsです。KaggleのDiscussionでは略されてMPLと言われていたりします。ラベルなしデータに対して疑似ラベルを予測するTeacherモデルと、その疑似ラベルを使って学習するStudentモデルの2モデルを使って学習サイクルを回します。

Semi-Supervised LearningのTwoMoon(トイデータ)で、通常の教師あり学習、Pseudo Labeling(図中Pseudo Labels)、MPLで比較検証を行ったところ、星印のデータのみ与えた場合でも、MPLは自然な分類ができたと主張しています。

元論文は画像認識の分野で提案されており、評価ではImageNetで当時SOTAを達成していました。Kaggleで最初に使われたのはこちらのnotebookだと思われます。
MPLの学習は以下の2フェーズに分けられます。
1. Teacherモデルの出力からStudentモデルが学習する
Teacherモデルにラベルなしデータの予測を行わせ、そこから擬似ラベルを作成して、その擬似ラベルをStudentモデルに学習させる、所謂蒸留のフェーズになります。
2. Studentモデルの損失から Teacherモデルの学習を行う
Teacherモデルは従来のラベルを付けられたデータの学習に加えて、1つ目のフェーズの学習前と後のStudentの損失の差分を学習します。つまりStudentモデルの性能改善具合をTeacherモデルにフィードバックしてあげることで、Teacherモデルの学習効率を向上させることを期待しています。
比較実験
実際にKaggleの入門コンテストのデータを使って、各手法の評価を行ってみたいと思います。
データセット
以前、SetFitの記事でも利用させていただきましたNatural Language Processing with Disaster Tweetsを使いたいと思います。
こちらは災害があった際とそうでない時のTweetの分類タスクになります。一見簡単そうに見えますが、例えばablazeという単語は火災などで燃えるという意味がありますが、アトラクションなどで熱狂する、という意味でも使われるため、ある程度文脈を考慮する必要が出てきます。
実装
今回、実装は大量のコードを載せてしまうことになるので、Kaggleに公開codeでシェアしました。
- Baseline
- 2000件をアノテーション済みデータ、残りの5613件をラベルなしデータ
- アノテーション済みデータの内訳はtrain:valid:test=1000:500:500
- Pseudo labeling
- 擬似ラベルはハードラベル
- MLM
- MLMの学習はearly stoppingなしの8epoch(決め打ち)
- Meta Pseudo Labels
- 擬似ラベルの学習に時間がかかるので、epoch数をBaselineの3倍の15 epochに
お手数ですが、実装を確認したい方はこちらをご参照いただければと思います。
評価結果
各手法の精度をまとめた表が以下になります。
| 手法 | Validation Best | Test | Public Score |
|---|---|---|---|
| Baseline | 0.730 | 0.728 | 0.70211 |
| Pseudo labeling | 0.752 | 0.744 | 0.71743 |
| MLM | 0.774 | 0.758 | 0.73582 |
| Meta Pseudo Labels(Teacher) | 0.796 | 0.786 | 0.76310 |
| Meta Pseudo Labels(Student) | 0.776 | 0.786 | 0.75298 |
| full data | - | - | 0.79681 |
参考までに以前実験した同じパラメータでフルセットを使った評価結果(full data)も載せています。Validation、Testの分割が異なるので、こちらのスコアは載せていません。
どの手法もBaselineより良いスコアを得ることができていることがわかります。一方フルセットを使った結果には及ばないので、きちんとアノテーションされたデータを使った教師あり学習の方が性能は良くなると言えます。
MPLのepoch数に関する追加実験
MPLはepoch数を増やしていますが、それが精度改善の直接的な要因でないことを確認する実験を行いました。MPLと同じデータセットを使うPseudo Labeling(図中Pseudo)と5, 10, 15epochのPublic Scoreを比較しました。結果を以下にまとめます。

5 epochの時はMPLは精度が非常に低いですが、epochを増やすに従って精度が向上していることがわかります。一方Pseudo Labelingの方は若干は精度が改善していますが、MPLほど大きな改善は見られません。
おわりに
本記事ではTransformerをベースとした事前学習モデルのfine-tuningのTipsとして、ラベルなしデータの活用について紹介しました。
Kaggleの入門コンテストのデータを使って、各手法の評価を行い、どの手法もBaselineより良いスコアを得ることができることがわかりました。今回はMPLが最も良い結果となりましたが、MPLはチューニングが難しいので、使用時は注意が必要です。Kaggleの上位解法でも使われることは稀な印象です。(もちろんNBME 3rd Solutionのようにうまくハマっているケースはあります)
「データは沢山あるけど、アノテーションされたデータは少量しか用意できない」というケースは実務ではよくあるので、今回紹介した手法を積極的に試していきたいです。
最後までお読みいただき、ありがとうございました!




