はじめに
こんにちは、AIチームの杉山です。
今回の記事では、チャットボットや音声アシスタントにおけるout of domain(以降、OOD)検出に関する研究として、AAAI 2023のWorkshopに採択されたAmazon社のFew-shot out of domain intent detection with covariance corrected Mahalanobis distance[1]という論文を紹介します。
チャットボットや音声アシスタントにおけるOOD
チャットボットや音声アシスタントなどのユーザーからの入力クエリに対して回答する自動応答システムでは、大きくEnd-to-End型とパイプライン型が存在します。現時点では制御の柔軟性などの理由からエンタープライズ用途においては一般的にパイプライン型が用いられることが多く、その場合は入力クエリの意図(インテント)を推定し、推定された意図に対応する応答を選択して返答します。
意図推定モデルは意図の信頼度スコアだけでなく、入力クエリがシステムの対象外(OOD)である可能性も出力することが期待されます。
入力クエリがOODと判断できると、問い返しなどを行って質問の明確化を行ったり、「分かりませんでした、別の言い方でお願いします」のようにフォールバック応答することでタスクを完了に近づける手段を取ることができます。
OODの検出は二値分類タスクとしてモデル化することができ、システムの対象外および対象内(in domain、 以降IND)の2カテゴリに分類することで実現できます。良いUXを与えたりユーザーを失望させずQAシステムとして信頼を得るためには、回答できる質問には正しく回答しつつOOD検出器の精度を保つというトレードオフを達成することが重要になります。
最近の研究でも、OODの検出は様々行われていますが[2][3][4]、OODの例を含む大規模な学習データセットや大規模なラベルなしコーパスにアクセスする必要があるなど、プロダクトとしての実環境適用においてこれらの前提を満たすことは難しいという問題点があります。
マハラノビス距離によるOOD検出と問題点
入力クエリをOOD/INDの2クラスに分類するアプローチは、大きく以下の2つがあります。
- Data-centric: OOD/INDの例をよりよく分離できる表現を学習するために、大規模コーパスからのサンプリング、言語モデルを使用した文章生成、または文類似モデルを使用してフィルタリングするなどで追加のOODデータを作成し使用する方法
- Score-based:特徴量、モデルロジット、または勾配空間のノルムなどからOOD/INDの分類を決定するためにスコアを計算する方法
この論文では、産業応用を見据えて追加のOODデータを必要としない、Score-basedな手法をベースに検証しています。
Score-basedな手法によるOODの検出にはマハラノビス距離を用いた異常検知的なアプローチでOOD/INDの判定を行う方法がよく行われています。
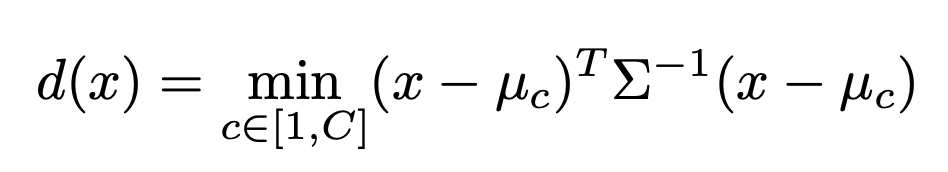
マハラノビス距離の定義式
x: 入力データ
C: 分類クラス
μ_c: 対応クラスの特徴の標本平均
Σ: 特徴の共分散行列
T: 分類閾値(上式のTransposeを表すTとは別)
スコア関数: G(x): if d(x) >= T then OOD else IND[2]では、RoBERTaの埋め込みで計算されたマハラノビス距離が、追加データを使用せずにOOD検出のためのベースライン手法を上回ることを示しましたが、マハラノビス距離は低リソース環境では性能が低いという報告もあり[5]、プロダクションとして実環境に提供するための問題点を解決できていません。
その理由としては、d次元のn個の点に対して計算されるd×dの共分散行列のランクはmin(n-1, d)によって上からおさえられるが、少数リソース環境ではn≪dなので共分散行列はspecificになるが、定義式のようにマハラノビス距離は共分散の逆行列を用いるため、擬似逆行列計算でベストフィットな解を推定することは、性能に悪影響を及ぼす可能性があると考えられます。
実際に共分散行列を計算する際のデータ数を変えながらOOD検出の精度がどのように変化したかを表すグラフが図1です。データ数が400を超えたあたりからは全データ30Kで計算した際の結果に漸近していますが、一方で400を下回ると急激に性能が悪化していることが確認できます。
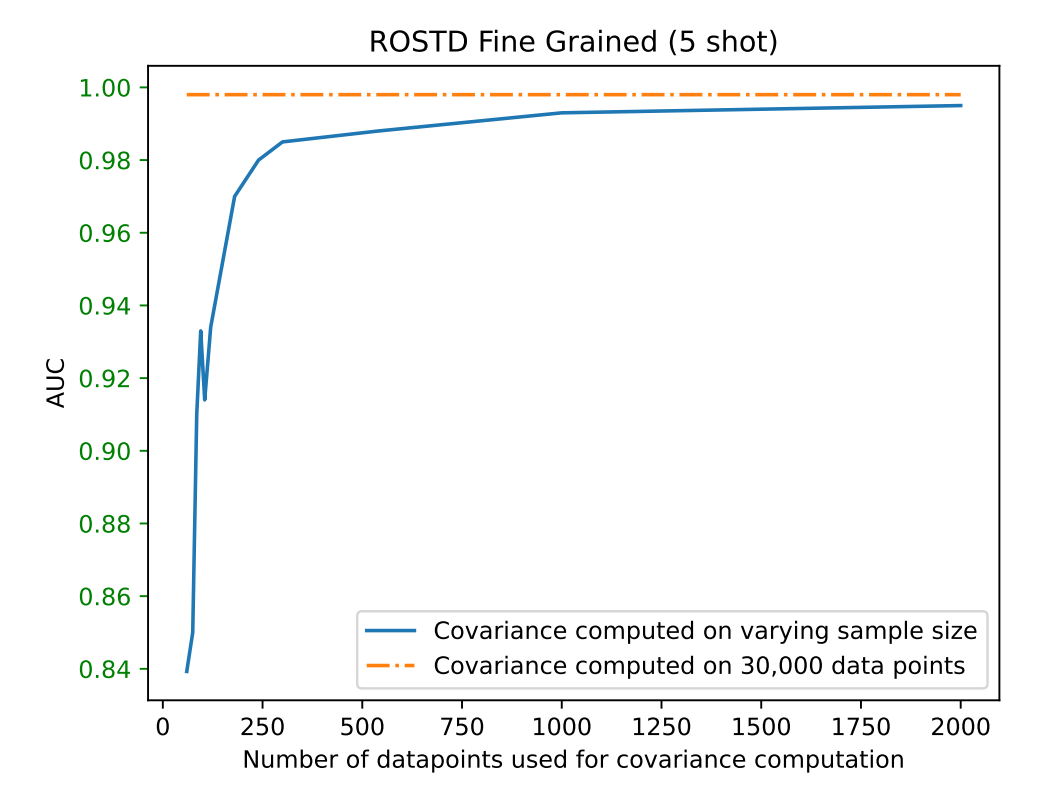
図1: ROSTDデータセット(後述)におけるマハラノビス距離に基づくOOD検出の性能。図は[1]より引用
手法と実験
上記の問題点に対し、共分散の計算にロバストな共分散推定としてベースラインのMaximum Likelihood estimator(MLE)と、完全互換の以下の3手法について検証・比較します。

加えて、energy-basedな手法[6]、勾配ノルムを用いる手法[7]、OOD検出の強力なベースラインであることが報告されているMaximum Softmax Probability(MSP)[8]に対して4手法をベンチマークします。どの実験でも、cross entropy lossに対し、意図推定のためのRoBERTaモデルをfine-tuningします。なお実験のパラメーターなどの詳細は割愛するため気になる方は元論文をご確認ください。
X-shot学習では、サイズd×dの共分散行列がサイズ(X・Nc)×dのデータ行列から計算されます。(次元数d=768、Ncはクラスの数)
実験の各iterationにおいて、1)訓練セットからクラスごとにX個のデータ点をランダムにサンプリング、2)対応する推定器を用いてX・Nc個のデータ点のみを使用して共分散行列を計算します。
データセットと評価指標
以下の4データセットで手法を評価します。
- CLINC150
OODクエリに対するタスク指向対話システムのパフォーマンスを評価するために提案されたデータセットで、10以上のドメインにまたがる150のインテントが含まれる - ROSTD
多言語タスク指向対話のためのcross lingual transfer learningをテストするために開発されたデータセットで、後に英語のOODクエリが追加された - ROSTD-COARSE
2のROSTDから3つのインテントのみを選択した粗視化版。2と3の両方のデータセットでテストには同じOODクエリのセットを使用する - SNIPS
7つのインテントが含まれ、インテントごとに約2000の発話があるデータセットでINDとOODの区別がないため、ランダムに5つのインテントをIND、残りの2つをOODとする
OOD検出は二値分類問題なので、Area Under the Curve(AUC)、Precision-Recall ROC Curve(PRROC)、True Positive Rateが95%の時のFalse Positive Rate(FPR@95%TPR)の3メトリクスで性能を評価します。
結果
ベンチマークデータセットにおけるマハラノビス距離の共分散補正法の性能を比較したものが表1です。
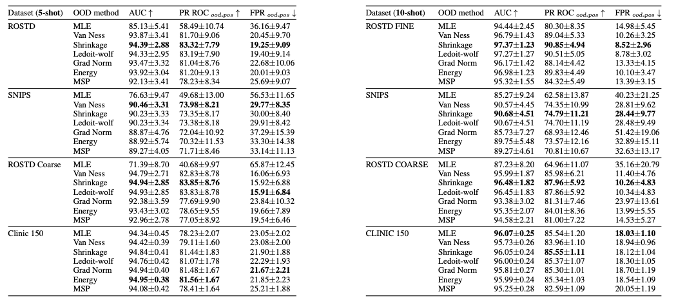
Shrinkage、LedoitWolf、Van Nessは、4つのデータセットのうち3つですべてのメトリクスにおいて他のOOD検出法を上回っていることがわかります。さらに、5-shotの設定では、共分散補正はすべてのデータセットでMLEを上回っています。
一方で10-shot設定のCLINC150データセットでの結果のように使用するサンプル数が増加すると、MLEと共分散補正法の差は無くなっていきます。
インテントクラスの数に対するOOD性能の影響を評価するために、CLINC150データセットからインテントのサブセットをサンプリングして、いくつかのモデルをトレーニングして実験した結果が図2です。
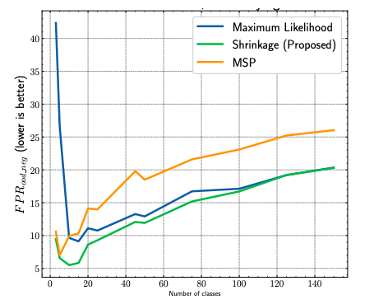
インテント数が少ない場合は、Shrinkage(緑線)がMLE(青線)を大きく上回り、インテント数が増えるにつれてMLEの性能に収束することがわかります。
OOD検出の有効性がINDクラスの数が増加するにつれて低下していますが、これはOODサンプルの数が固定されている場合INDサンプルのサイズが大きくなると、OOD/IND境界上にあるサンプルが多くなるため、OODクラスとの混同が大きくなるからであると考えられます。
おわりに
今回の記事では、OOD検出にマハラノビス距離を用いる場合の問題点とその対処法に関する論文を紹介しました。提案された低リソース環境にロバストな共分散推定器を用いて計算されたマハラノビス距離が、ベースラインを上回ることを確認し、中でもShrinkage estimatorが優れていることがわかりました。提案されたアプローチは、1クラスあたり1回の行列-ベクトルのドット積を追加するだけで計算量が少なく、補助データも学習手順の修正も必要ないためプロダクト環境にも適用しやすいと考えられます。
企業のFAQページなどにおけるClosed DomainなQAシステムの実運用においては、OODをより細分化したin domain but out of scope(ID-OOS)というクエリも考慮する必要があります。ID-OOSとは、ドメインとしては関連しているものの、そのQAシステムでは回答できないクエリのことを表します。(例えば金融系のドメインで「投資で儲けるにはどうしたらいいですか?」のようなドメインは合っているがシステムとして回答できないものなど)
埋め込みベクトルの類似度などを元にQuestionを探して該当するAnswerを返すようなQAシステムの場合、ID-OOSなクエリは本来回答できないにも関わらずドメインが関連しているため類似度が高くなりやすく結果として回答精度に悪影響を与えます[9]。そのため回答できないことはできないと判定し、別のフロー(例えば有人オペレーターに引き継ぐなど)に流すなどの処理を行う必要があります。
運用ログにそのようなクエリが多く存在する場合、ユーザーの知りたい・調べたいというニーズがあると考えられるため、QAシステムとして回答できるようQAセットを拡張するなどの改善が考えられます。
このようなID-OOSに関する研究も様々行われているため、今後それらの研究も紹介できればと思います。
最近話題のChat系LLMなどの性能には驚くことばかりですが、質問内容によっては迂遠な回答をしてどうにかそれらしい回答をしてくれようとしますが、結局どういうことだったかよくわからず「つまり要約すると?」といったやりとりの結果理解できるようになったり、結局正しい回答が得られなかったりするケースがあります。
回答できない場合はそのことをすぐに伝えてくれることもリアルタイム自動応答には必要な機能だと考えているので、引き続き周辺技術の調査や検証を続けていきたいと思います。
ここまで読んでいただきありがとうございました。
参考
[1] Few-shot out of domain intent detection with covariance corrected Mahalanobis distance
[2] Revisiting Mahalanobis Distance for Transformer-Based Out-of-Domain Detection
[3] Improving Out-of-Scope Detection in Dialogues using Data Augmentation
[4] PnPOOD: Out-Of-Distribution Detection for Text Classification via Plug andPlay Data Augmentation
[5] No True State-of-the-Art? OOD Detection Methods are Inconsistent across Datasets
[6] Energy-based Out-of-distribution Detection
[7] On the Importance of Gradients for Detecting Distributional Shifts in the Wild
[8] A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
[9] Are Pre-trained Transformers Robust in Intent Classification? A Missing Ingredient in Evaluation of Out-of-Scope Intent Detection




