こんにちは!
AIチームの戸田です。
今回はKaggleのInformation Retrievalタスクのコンペティション、Learning Equality - Curriculum Recommendationsの1st solutionでも使われていたsparse_dot_topnによるcos類似度計算の高速化を試してみたいと思います。
sparse_dot_topn
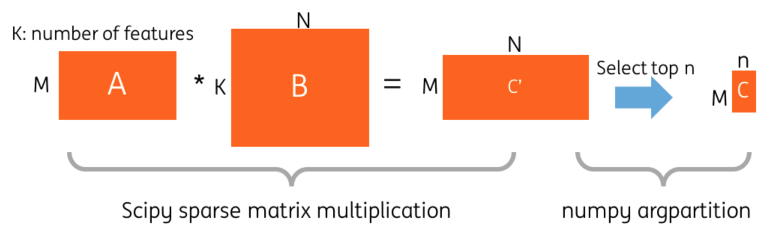
QA検索のようなクエリに類似する文章を検索するようなタスクにおいて、近年はBERTなどの事前学習済みモデルから文章の特徴ベクトルを抽出して比較したり、Dense Passage Retrievalのような文書間の類似度を直接推定するモデルを利用する方が精度が良いと言われています。しかし実務では推論速度やGPUなどのマシンコストの点から、古典的なTF-IDFなどのスパースなベクトルの類似度を利用するケースも多くあります。
sparse_dot_topnはそのようなスパースな行列の乗算とそれに続くトップ N件の選択を高速に実行するPythonライブラリです。リポジトリのREADMEによると、推論速度が最大40%も向上するそうです。
高速化技術の詳細についてはこちらの2つのブログをご参照ください。
- Boosting the selection of the most similar entities in large scale datasets
- Boosting Selection Of Most Similar Entities In Large Scale Datasets
インストール方法
pipで簡単にインストールすることができます
pip install sparse_dot_topn依存ライブラリはnumpyとcythonのみなので、手間取ることはほどんどないと思われます。
使い方
公式のExampleを転記します
import numpy as np
from scipy.sparse import csr_matrix
from scipy.sparse import rand
from sparse_dot_topn import awesome_cossim_topn
N = 10
a = rand(100, 1000000, density=0.005, format='csr')
b = rand(1000000, 200, density=0.005, format='csr')
# Default precision type is np.float64, but you can down cast to have a small memory footprint and faster execution
# Remark : These are the only 2 types supported now, since we assume that float16 will be difficult to implement and will be slower, because C doesn't support a 16-bit float type on most PCs
a = a.astype(np.float32)
b = b.astype(np.float32)
# Use standard implementation
c = awesome_cossim_topn(a, b, N, 0.01)
# Use parallel implementation with 4 threads
d = awesome_cossim_topn(a, b, N, 0.01, use_threads=True, n_jobs=4)
# Use standard implementation with 4 threads and with the computation of best_ntop: the value of ntop needed to capture all results above lower_bound
d, best_ntop = awesome_cossim_topn(a, b, N, 0.01, use_threads=True, n_jobs=4, return_best_ntop=True)awesome_cossim_topnの引数は何個かありますが、基本的には比較するベクトルA, Bとトップ何件を返すかのNだけで大丈夫です。
高速化検証
以前AIチームの杉山が書いた埋め込みベクトルを用いたSVMによる類似文検索の検証という記事と同様、JGLUEのJSTSをQA検索データに見立てて、検索のための計算を行なった際にかかった時間を計測し、scikit-learnのcos類似度計算と比較したいと思います。
前処理
JSTSは1万件以上データがあるので、問題を簡単にするためにlabel(文書間類似度)が4以上のものにデータを絞り、sentence1をクエリ、sentence2を検索対象文章としてリストにします。また、形態素解析にはjanomeを使います。
from tqdm.auto import tqdm
from datasets import load_dataset
from janome.tokenizer import Tokenizer
dataset = load_dataset("shunk031/JGLUE", 'JSTS', split='train')
tokenizer = Tokenizer()
queries, corpus = [], []
for d in tqdm(dataset):
if d['label'] < 4:
continue
s1 = " ".join([token.surface for token in tokenizer.tokenize(d['sentence1'])])
s2 = " ".join([token.surface for token in tokenizer.tokenize(d['sentence2'])])
queries.append(s1)
corpus.append(s2)計測
以下のような計測用の関数を作ります。
import time
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sparse_dot_topn import awesome_cossim_topn
def calc_cos_for_retrieve(corpus, queries, mode):
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
t0 = time.time()
p_at_n = []
for i, query in enumerate(queries):
qx = vectorizer.transform([query])
if mode == "sklearn":
sim = cosine_similarity(X, qx, dense_output=False)
elif mode == "sparse_dot_topn":
sim = awesome_cossim_topn(X, qx.T, 10)
else:
raise ValueError(f"Unknown mode `{mode}`")
sim = sim.toarray()[:, 0]
relevant_documents = np.argsort(-sim)
idx = np.where(relevant_documents == i)
idx = idx[0][0]
p_at_n.append(idx < 10) # P@10
t = time.time() - t0
return np.mean(p_at_n), tawesome_cossim_topnはtop_nを返さない設定になっているのですが、Nは必須の引数なのでとりあえず10を設定しています。返却は計算にかかった時間に加えて、sparse_dot_topnとscikit-learnが同じ結果になるかを確認するため、Precision@10も返すようにしています。
こちらの関数を実行すると以下のような結果になります。
p_at_n, _ = calc_cos_for_retrieve(corpus, queries, "sklearn")
p_at_n # 0.775570272259014
p_at_n, _ = calc_cos_for_retrieve(corpus, queries, "sparse_dot_topn")
p_at_n # 0.775570272259014結果は同じようになることがわかりました。
計測結果
上記のコードを10回実行した平均時間とその標準偏差を計算したところ、以下のような結果になりました。
| sparse_dot_topn | scikit-learn |
| 1.7749 秒 (std=0.0231) | 2.5862 秒 (std=0.0227) |
現在一般的な手法であるscikit-learnを使ったcos類似度計算より約30%ほど高速化しました。
READMEにある最大40%の高速化には届きませんでしたが、大量のリクエストを捌く時などは30%でも十分ありがたいのではないでしょうか。
ちなみに今回検証に使ったコードはKaggle Notebookにアップロードしているので、再現してみたい方はこちらをご参照ください: link
おわりに
本記事ではsparse_dot_topnによるスパースベクトルのcos類似度計算の速度をscikit-learnのcos類似度計算と比較してみました。結果、scikit-learnのものより30%ほど高速化することがわかり、依存するライブラリも少ないので、すぐに実務でも使えそうなものだとわかりました。
最近はChatGPTの影響で、なんでもLLMで解決しようとする流れがありますが、プロダクトに組み込むとなると、やはりコスト面や速度面での懸念があるので、こういったシンプルな手法を組み合わせて開発していけたらよいなと思いました。
最後までお読みいただき、ありがとうございました!




