こんにちは!
AIチームの戸田です
本記事では私がKaggleのコンペティションに参加して得た、Transformerをベースとした事前学習モデルのfine-tuningのTipsを共有させていただきます。
以前も何件か同じテーマで記事を書かせていただきました。
- Kaggleで学んだBERTをfine-tuningする際のTips①〜学習効率化編
- Kaggleで学んだBERTをfine-tuningする際のTips②〜精度改善編〜
- Kaggleで学んだBERTをfine-tuningする際のTips③〜過学習抑制編〜
- Kaggleで学んだBERTをfine-tuningする際のTips④〜Adversarial Training編〜
- Kaggleで学んだBERTをfine-tuningする際のTips⑤〜ラベルなしデータ活用編〜
今回は学習効率化について書かせていただきます。このテーマは以前書かせていただいたのですが、記事を書いてから2年ほど経つので情報アップデートがあったことと、近年流行しているLLMのfine-tuningにも応用できるものもあるので、その観点も入れて書いていきたいと思います。
学習効率化
以前の記事では以下の4点について共有させていただきました
- 混合精度
- 文章の切り詰め
- Uniform Length Batching
- 勾配累積
1, 3, 4についてはLLMの学習にも適用できますが、2は文章が変な部分で切れてしまい、LLMの学習がうまくいかなくなる可能性があることが考えられる(実際には検証していないです)ので適用しない方が良いかもしれません。
今回は新たに3種類の手法について共有したいと思います。
Embedding Freeze
TransformerのEmbedding層をFreeze、つまり学習しないようにし、その分のGPUメモリを節約する手法になります。
「学習するパラメータを減らしてしまうことになるので、精度が落ちるのではないか?」という懸念も考えられますが、Embedding層は各トークン(単語)の表現を事前学習で獲得しており、この単語表現はドメインに適用する際も事前学習時のものと大きく変わらないだろう、という想定から問題ないと考えられています。逆にfine-tuningするデータがごく少量の場合、事前学習で得られたEmbedding層の表現を破壊してしまう可能性もあるので、過学習抑制効果もあるのではないか、という期待もあるようです
実装は以下のように簡単に実装できます。
model = {transformersのモデルの定義}
model.base_model.embeddings.requires_grad_(False)LLMの学習でも若干の効果はあるとは思いますが、そもそものパラメーター数が大きいので効果が少なそうなことと、LoRAを使う場合は全てのLayerがFreezeされることから、LLMの学習ではあまり使う意味はないと思われます。
Gradient Checkpoint
通常のニューラルネットの学習では、backpropagationで損失関数の勾配を計算するためにメモリに保存されたforwardの計算結果を使います。Gradient Checkpointは一部のノードをCheckpointとして指定し、forwardの計算結果はそのノードでのみ覚えておき他は捨ててしまいます。backpropagationの際はチェックポイントより前方のforwardは再計算する、というアプローチになります。こちらの論文で提案されました。
言葉で説明すると難しいですが、こちらのブログで使われた以下の図だと理解しやすいかもしれません。
上の段の左から三番目のノードがCheckpointになります
大幅なメモリ削減を行うことができますが、foward計算を余分に実行する必要があるので学習時間が増加してしまうというデメリットもあります。
実装は以下のようなモデルのパラメータによってON/OFFを切り替えるパターンと、Trainerを使う場合はgradient_checkpointingパラメータで設定するパターンがあります。
model = {transformersのモデルの定義}
model.gradient_checkpointing_enable() # ON
model.gradient_checkpointing_disable() # OFF大幅なメモリ削減ができるのでLLMの学習でも活躍しそうです。
Adafactor
Adafactorはこちらの論文で提案されたAdamを元にした最適化アルゴリズムで、メモリ容量の削減と学習率の自動調整を兼ね備えた手法になっています。機械翻訳タスクにおいて省メモリでAdamと同等の結果を達成したと言われています。詳細は元論文を参照いただければと思います。
デメリットとして通常のAdamよりも収束が遅くなると言われています。
optimizer自体はtransformersに実装されているのと、TrainingArgumentsの引数としても設定されているので簡単に使えると思います。
LLMの学習でももちろん利用可能で、trlのRLHFのサンプルスクリプトでも引数で指定できるようになっています。
比較実験
実際にKaggleの入門コンテストのデータを使って、各手法の評価を行ってみたいと思います。
モデルは時間短縮のためにmicrosoft/deberta-v3-xsmall、GPUはT4を利用しました。
データセット
以前、SetFitの記事でも利用させていただきましたNatural Language Processing with Disaster Tweetsを使いたいと思います。
こちらは災害があった際とそうでない時のTweetの分類タスクになります。一見簡単そうに見えますが、例えばablazeという単語は火災などで燃えるという意味がありますが、アトラクションなどで熱狂する、という意味でも使われるため、ある程度文脈を考慮する必要が出てきます。
実験結果
このコンペティションの評価指標であるAccuracyに関して、各モデルの結果を以下にまとめます。
| validation | test | |
| Baseline | 0.809 | 0.796 |
| Embedding Freeze | 0.798 | 0.800 |
| Gradient Checkpoint | 0.808 | 0.799 |
| Adafactor | 0.809 | 0.811 |
どれも0.8前後でそこまで大きな性能の差はなさそうです。Adafactorは収束が遅くなると言われていますが、今回の問題設定では特に大きな影響はなかったようです。
次にWeights & Biasesで記録したGPUメモリ使用率を以下に示します。
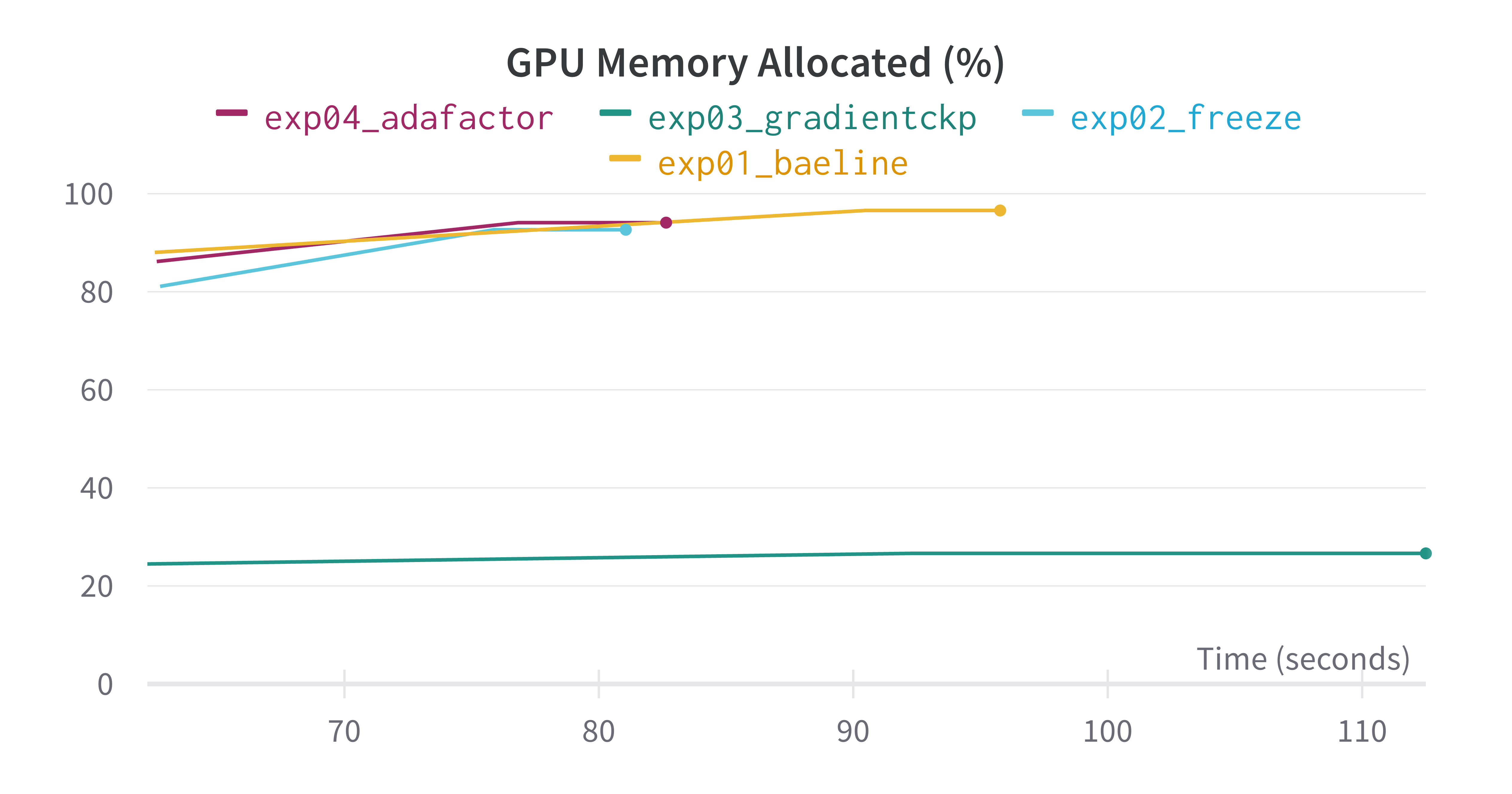
| 実行時間(秒) | 最大GPUメモリ使用率 | |
| Baseline | 95.772866 | 96.58% |
| Embedding Freeze | 81.058064 | 92.65% |
| Gradient Checkpoint | 112.504774 | 26.64% |
| Adafactor | 82.643495 | 94.10% |
どの手法もBaselineに比べて最大GPUメモリ使用率が減っているのがわかります。特にGradient Checkpointは大幅な削減がされれいるのがわかります。
実行時間に関してもGradient Checkpoint以外はBaselineより短い時間で終わっていることがわかります。Gradient Checkpointはforward計算が余分に必要な分若干増えてしまっていますが、メモリを削減した分バッチサイズを大きく設定することもできると思うので、調整すれば差は小さくなるのではないかと思います。
今回実験に使用したコードは以下に公開しております。
Kaggle Code: Disaster Tweets Efficiency
おわりに
本記事ではTransformerをベースとした事前学習モデルのfine-tuningのTipsとして、学習効率化についてLLMの学習で使う際の観点と共に紹介しました。Kaggleの入門コンテストのデータを使って、各手法の評価を行い、どの手法もメモリや実行時間の点で精度を犠牲にせず効率化を図れることがわかりました。
以前紹介した混合精度などの手法と組み合わせるとGoogle ColabのT4のような無料で使えるGPUでもKaggleのNLPコンペで十分戦えるようになるのではないでしょうか。実務でもリソースは無限に使えるわけではないので、こういった効率化手法は活用できると思います。
これまではSingle GPUでの学習効率化について書かせていただきましたが、最近Kaggle NotebookではT4 x 2のマルチGPUも使えるようになっており、学習のノウハウも溜まってきているので、これについても今後書いていきたいです。
最後までお読みいただき、ありがとうございました!




