はじめに
この記事はAI Shift Advent Calendar 2023の19日目の記事です。
こんにちは!AI チームで内定者アルバイトとして働いている長澤です。
昨今、言語モデルを含めたニューラルモデルの大規模化が止まりませんね。
「大きすぎてモデルがメモリに乗らん…」は最早あるあるなお悩みかと思います。
大規模化の流れに伴って、上記の問題を解決する1つの手段として「量子化」というワードをよく耳にするようになりました。
この量子化について、
「とりあえず低ビットにすれば、精度は落ちちゃうけどメモリ消費量抑えられるみたいな話だよね…?」
というボヤッとしたイメージの解像度をあげるベく、Hugging Face ライブラリでの実装を例に取り、量子化について初歩的な内容を整理していこうと思います!
なお、本記事では単純化のため fp32 から int8 への量子化を扱います。また原理的な理解を狙いとするため、実運用でどれほど精度が変わるか、推論速度が上がるかという話はスコープ外とします。
(出典を明記していない図表については自作したものになります)
fp32とint8
まずはきちんとデータ型について整理するところから始めてみようと思います。
「もうこんな内容は理解済みだぜ」な方は適宜読み飛ばしてください。
ここで登場するキーワードは3つです。
- sign: 符号ビットのことで、扱うデータの正負を表現します。
- mantissa: 仮数部を指します。ここが大きいほど扱える値の範囲が広くなるイメージです。(ここでは便宜上 int8 の整数部分も含意するとします)
- exponent: 指数部を指します。仮数部に基数の何乗を掛け合わせるかを決定します。ここが大きいほど、扱える値のスケール感が変わってくるようなイメージかと思います。(0.0003 などの小さい値や、100000 のような大きい値が扱えるようになっていく)

図を見ると、int8 と fp32 でそれぞれのビットの振られ方が違うことが分かります。
そしてこのビット数の違いがメモリ消費量に効いてくるのは言わずもがなかと思います。単純計算で fp32 は int8 の4倍のメモリを消費するという感じですね。
またビットの振られ方が違うということは、当然のことながら扱える値の範囲も異なってきます。
例えば、int8 で扱える範囲は(\( 2^7=128 \) なので、符号ビットと組み合わせて)-128 から 0 および127という感じになります。
これに対し、fp32 は int8 に対してより多くのビット数を割り振る(メモリ消費量を増やす)ことで、広範な値を扱えるようにしているというイメージを掴んで頂ければと思います。
この「扱える値の範囲が異なる」という部分が量子化の精度変化において重要な要素になります。こちらについて、もう少し解像度を上げてみたいと思います。
fp32 から int8 への量子化
まずは直感的な図解を示します。
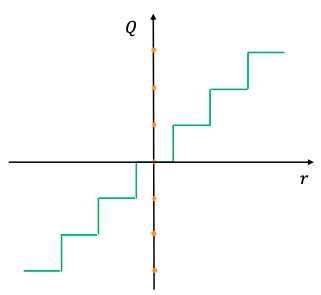
(https://arxiv.org/abs/2103.13630 より)
「連続値 r を離散化された値 Q に圧縮する」というのが、量子化における一番直感的な理解かと思います。(図は均一量子化と呼ばれるものになっています。気になる方は引用している論文を参照頂ければ幸いです。)
例えば \( r=2.345 \) みたいな値が \( Q=2 \) のように丸め込まれるイメージです。
扱える範囲を限定する(精度を落とす)代わりに、メモリ消費量を抑えて推論などの計算フローを高速化させているわけですね。
一方で先ほど、fp32 と int8 とではビットの割り振られ方、表現できる値の範囲が互いに大きく異なるということを見てきました。
したがって、上に示したような単純な丸め込みは何だか良くなさそうな雰囲気がします。
例えば、fp32 ではきちんと捉えられていた小さなロスが、int8 では全て0に丸め込まれてしまうなどの問題が起きてしまいそうですね。
では、Hugging Face ライブラリではどのような工夫がなされているか見てみようと思います!
Affine Quantization Scheme
Hugging Face のドキュメント(https://huggingface.co/docs/optimum/concept_guides/quantization#quantization-to-int8) を見てみるとどうやら Affine Quantization Scheme というテクニックを使って fp32 から int8 への量子化が実現されているようです。
処理の流れ
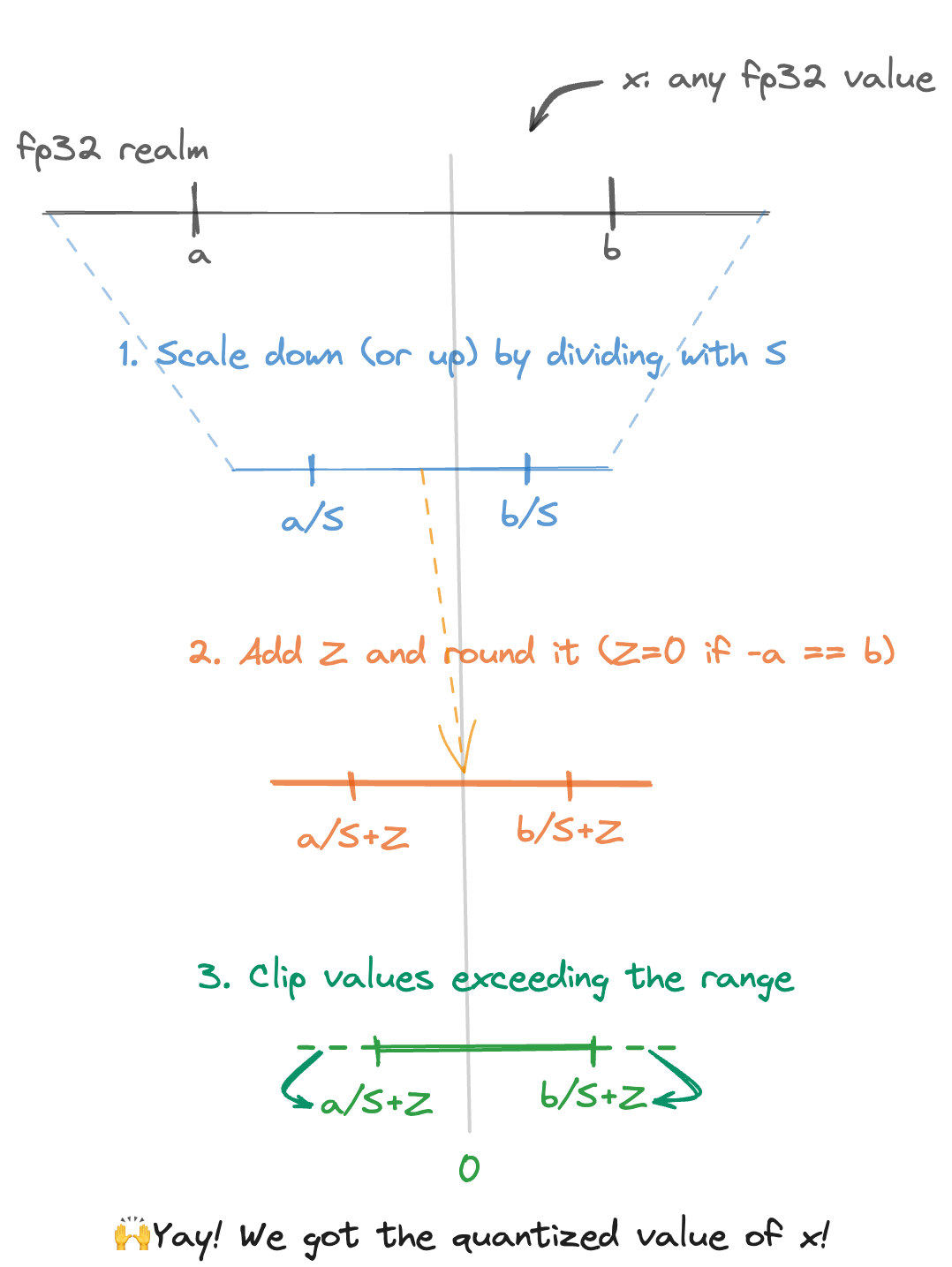
まずは int8 にうまく量子化できそうな fp32 の範囲 [a, b] での処理を考えてみましょう。
(下に処理の流れをまとめた図を掲載しているので、そちらも合わせて確認して見てください!)
ここでは fp32 のある値 \( x \) を int8 に量子化した \( x_q \) への変換を例にしてみます。
Affine quantization scheme では正の fp32 のある値 \( S \) と int8 のある値 \( Z \) を使って以下のような変形をします。
$$ x=S\times(x_q-Z) $$
“Affine” の名の通りの操作がされていそうですが、これだけでは何を意図しているか分かりにくいですね。まずは \( S \) と \( Z \) のそれぞれの役割を見てみましょう。ドキュメントでは以下のように説明されています。
\( S \) and \( Z \) are the quantization parameters
- \( S \) is the scale, and is a positive
float32- \( Z \) is called the zero-point, it is the
int8value corresponding to the value0in thefloat32realm. This is important to be able to represent exactly the value because it is used everywhere throughout machine learning models.
つまり \( S \) は桁数などのスケールを調整する役割で、\( Z \) はいわゆるオフセット(どれくらい値をシフトするかを決める変数)であることが分かります。
極端な例を考えるとすると、対象とする fp32 の範囲が正の値に偏った分布の場合、\( Z \) を負としてあげることで int8 での領域に効率的にマッピングが可能になります。(下図のステップ1から2への変換)
従って \( S \) や \( Z \) は扱う対象とする fp32 の範囲 [a, b] や量子化戦略次第で決定されるパラメータであることが分かりますね。
よって、最初の式を \( x_q \) について変形し、round で int 化してあげると以下のようになります。
$$ x_q=round(x/S+Z) $$
最後に、fp32 で対象としていた範囲 [a, b] から飛び出てしまったものをクリップしてあげて量子化(fp32 から int8 へのマッピング)が完了します。(下図のステップ2から3への変換)
ここでのクリップとは、単に上限(下限)を超えてしまったものは、上限(下限)の値として扱うという処理になります。
$$ x_q=clip(round(x/S+z), round(a/S+Z), round(b/S+Z)) $$
ここまでの流れを図示してみます。ここではスケールダウンさせる例を示してみましたが、機械学習などの小さな値を主として扱うような場合はスケールアップする形の運用となると考えられます。
ここでは fp32 から int8 への量子化を見ましたが、fp32 から fp16 への量子化はもっとシンプルに実施できます。気になる方は Hugging Face のドキュメント(https://huggingface.co/docs/optimum/concept_guides/quantization#quantization-to-float16) を参照してみてください!
実際の実装とメモリ消費量
それでは最後に(あるあるですが)実際にどれくらいメモリ消費量が変わるかを見てみようと思います。
「それでは Google Colab でモデルをロードして… 」と思いましたが、Hugging Face Accelerate のドキュメントにめちゃくちゃ便利そうなページが存在していたので、今回はそちらを使って算出してみようと思います。
https://huggingface.co/docs/accelerate/main/en/usage_guides/model_size_estimator
Gradio のデモとして計測可能なアプリケーションがページに埋め込まれているので、計測したいモデルの名前を入力し、メモリ消費量を知りたいデータ型を選択するだけで、それぞれの場合に応じた値を自動で算出してくれる便利ツールになっています。
今回は2023年の11月頃にリリースされた cyberagent/calm2-7b-chat を例に、メモリ消費量がどのようになるかを見てみることにします。
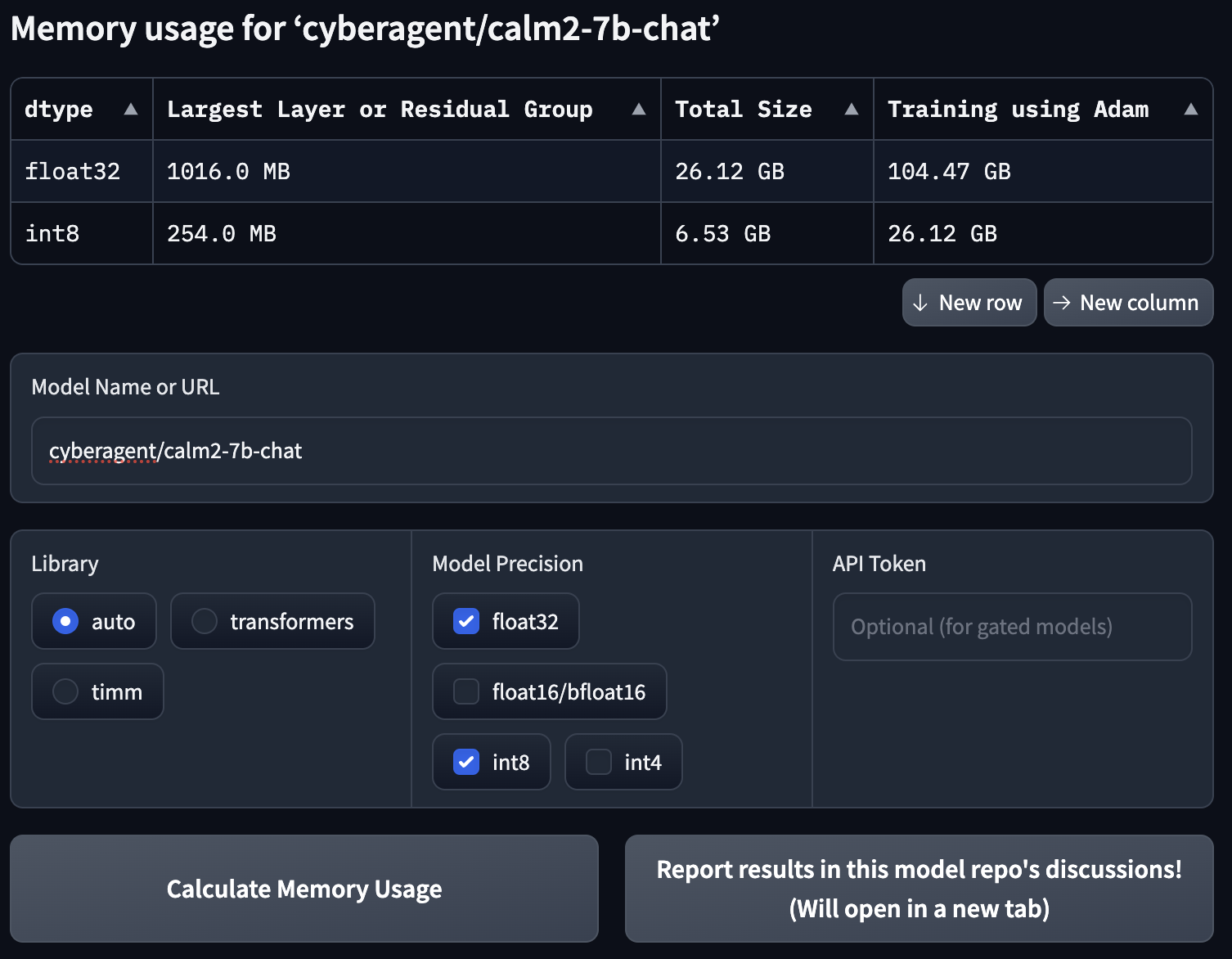
添付画像下側が入力フォーム、上側がその出力結果となっています。
モデルだけのメモリ消費量だけではなく、Adam で学習させる際のメモリ消費量まで計算されていることが分かります。
(学習でのメモリ消費量についてはおおよそモデルサイズの4倍という形で算出されているようです。この辺りは各種パラメータの設定で変わってしまうので、あくまで目安という形の提供かと思われます。)
結果から float32 ではモデルの消費メモリが 26.12GB であるのに対し、int8 では 6.53GB まで削減されていることが分かります!
従って \( 26.12\div6.53=4 \) ということで見事に 32bit → 8bit の削減分省メモリ化されていることが分かります。
さいごに
本記事では、fp32 から int8 への量子化について、図を交えながら解説してみました。
量子化は今後も重要なテクニックの1つとして使われていくものだと個人的には感じていますので、これから量子化に触れる方々を含め、多くの方の一助となれば幸いです!
AI Shiftではエンジニアの採用に力を入れています!
少しでも興味を持っていただけましたら、カジュアル面談でお話しませんか?
(オンライン・19時以降の面談も可能です!)
【面談フォームはこちら】




