こんにちは
AIチームの戸田です
今回は先月スタンフォード大学が発表した新しいParameter-efficient fine-tuning(PEFT)のReFTを試してみたいと思います。
PEFT
PEFTはLLMのような大規模な事前学習済みのニューラルネットワークのモデルを、効率的にfine-tuningする手法の総称です。モデル全体ではなく一部のパラメータだけを更新することで計算コストを大幅に削減できる上に、Full fine-tuning(モデル全体を学習)するのと同等の性能を達成することができると言われています。代表的なものにLow-Rank Adaptation(LoRA)が挙げられます。
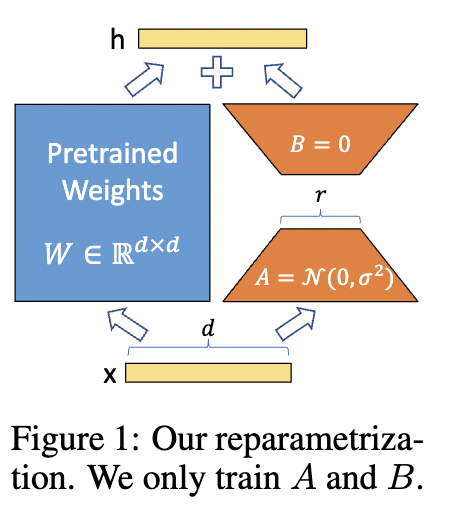
ReFT
Representation Finetuning (ReFT)は、LoRAとよく似たPEFT手法です。違いは、LoRAがモデルの重みを部分的に更新するのに対し、ReFTはモデルの中間層の出力に介入する点です。LoRAと比べて非常に少ないパラメータの変更でモデルの挙動を制御でき、その効率はLoRAよりも10〜50倍向上すると言われています。元論文はこちらになります。
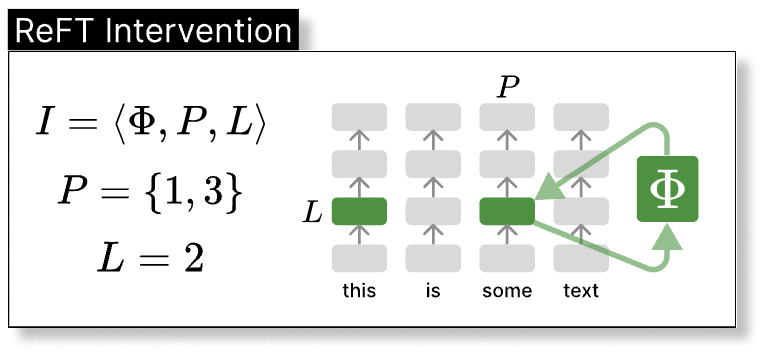
Figure 2. (1)
ReFTを使うためのpythonライブラリ、pyreftがGitHubで公開されているので、本記事ではこちらを試してみようと思います。
なお、本記事はReFTの学習を一通り動かすことを目的としており、パラメータ調整やデータクレンジングなどのより良い学習を行うための工夫は行いません。
使ってみる
以下でインストールできます
pip install git+https://github.com/stanfordnlp/pyreft.gitデータセット
学習データはお嬢様コーパスを利用させていただきます。以下でダウンロードできます。
git clone https://github.com/matsuvr/OjousamaTalkScriptDataset.gitpandasでダウンロードしたデータを読み込み、学習用に20件サンプリングします。
import pandas as pd
train_df = pd.read_csv("./OjousamaTalkScriptDataset/ojousamatalkscript200.csv")
sample_df = train_df.sample(20)モデルの読み込み
学習するモデルは小規模ながら高性能と期待されているMicrosoftのPhi-3を使います。
import torch, transformers, pyreft
device = "cuda"
model_name_or_path = "microsoft/Phi-3-mini-4k-instruct"
prompt_no_input_template = """<|user|>\n%s<|end|>\n<|assistant|>\n"""
model = transformers.AutoModelForCausalLM.from_pretrained(
model_name_or_path, torch_dtype=torch.bfloat16, device_map=device)
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_name_or_path, model_max_length=2048,
padding_side="right", use_fast=False)
tokenizer.pad_token = tokenizer.unk_token続けてReFTの学習の設定を行います。Phi-3のReftConfigの設定はこちらのissueを参考にしました。
reft_config = pyreft.ReftConfig(
representations={
"component":"model.layers[15].output",
"low_rank_dimension":4,
"intervention":pyreft.LoreftIntervention(
embed_dim=model.config.hidden_size, low_rank_dimension=4
)
}
)
reft_model = pyreft.get_reft_model(model, reft_config)
reft_model.set_device("cuda")
reft_model.print_trainable_parameters()
# trainable intervention params: 24,580 || trainable model params: 0
# model params: 3,821,079,552 || trainable%: 0.0006432737048652789学習
以下のコードで学習を行います。パラメータはライブラリのREADMEを参考に設定しました
training_args = transformers.TrainingArguments(
num_train_epochs=100.0, output_dir="./my_phi3", per_device_train_batch_size=10,
learning_rate=4e-3, logging_steps=40, report_to=[])
trainer = pyreft.ReftTrainerForCausalLM(
model=reft_model, tokenizer=tokenizer, args=training_args, **data_module)
_ = trainer.train()T4一枚で15分ほどで学習が完了しました。
予測
学習データにない文章を入力して、学習によってモデルの出力がどのように変わったか見てみましょう。
eval_df = train_df.iloc[[i for i in train_df.index if i not in sample_df.index]].sample(5)
results = []
for _, row in eval_df.iterrows():
prompt = prompt_no_input_template % row["prompt"]
prompt = tokenizer(prompt, return_tensors="pt").to(device)
base_unit_location = prompt["input_ids"].shape[-1] - 1 # last position
_, reft_response = reft_model.generate(
prompt, unit_locations={"sources->base": (None, [[[base_unit_location]]])},
intervene_on_prompt=True, max_new_tokens=512, do_sample=True,
eos_token_id=tokenizer.eos_token_id, early_stopping=True
)
results.append({
"output": tokenizer.decode(reft_response[0], skip_special_tokens=True),
"completion": row["completion"]
})こちらの結果とオリジナルの出力、そして学習していないデフォルトのPhi-3の出力を以下の表にまとめました
| 入力 | オリジナルの出力 | デフォルトのPhi-3の出力 | 学習したPhi-3の出力 |
| 次こそは上手くいきます | そろそろ、いい加減にしていただけますか? わたくし、もう疲れましたわ | この指示は、日本語で「それはとても上手く行けます」という意味を持つフレーズを簡潔に表現しています。日本語で同じ意味を持つフレーズとしては「それはとても上手くいきます」という表現が適切です。 | わたくしがあまり上手ではありませんわ! |
| もうダメかも | 自分に自信を持って、頑張りましょう!きっと、上手くいきますわ | I'm here to help! If you're feeling frustrated or if there's something specific you'd like assistance with, please let me know how I can support you. | わたくしは、どんな状況でも前向きに考えて、価値を見いだしているわ! |
| 人生が上手くいきません | 人生は、自分次第でどうにでもなるものですわ。今日から、変えていくことができますわ | 人生が上手くいかないと感じることは、普遍的な感情であり、個人の経験によって異なります。この感情を受け入れ、自己成長を目指すことが重要です。 | α = Aging well with medication 薬をたくんだ ok |
| このカフェ素敵ですね | はい私もこちらのお店が大好きですわ。落ち着いた雰囲気がいいですわね | この指示は、カフェに対する肯定的な感想を表現することを要求しています。以下に適切な日本語の回答を示します。 「本当に素敵なカフェですね。お弁当を食べながら、この雰囲気の中でリラックスしているのはいつものようです。」 この回答は、カフェの雰囲気や体験を評価し、肯定的な感想を伝えています。 | ご存知のleecherですわ |
| 好きな服のブランドはなんですか | スタイリストさんにお任せなのでよく存じておりませんの。わたくしに似合うものを選んでくださっていますわ | 私の好きな服のブランドについては、個人的な好みに基づいて答えることはできませんが、一般的に人々が好むブランドにはいくつかあります。例えば、ファッション業界で高い評価を受けているブランドには、ZARA、ミュラー、ナイキ、アディダスなどがあります。これらのブランドは、高品質な素材の使用、革新的なデザイン、そして個々のファッションスタイルに合わせた商品を提供しています。 | わたしのせいですわ |
学習データが少ないせいか、対話としては崩壊してしまっているのですが、お嬢様の発話スタイルを学習できているように見えます。全データで学習してみたらまた違うのかもしれません。通常のLoRAも試してみたいですね。
おわりに
本記事では高効率と期待されているPEFTのReFTをPhi-3の学習で試してみました。pyreftは現在LoRAでのFine-Tuningで多く活用されているHuggingFaceのPEFTライブラリのPEFT(名前がややこしいですね)と近いAPIでかなり使いやすかったです。
モデルやパラメータによって違うので一概に比較はできませんが、一般的なLoRAの学習時の学習パラメータ削減率(trainable%)が0.01〜0.1程度なのに対し、ReFTは0.001未満で、非常に高効率であることが感じられました。一方で学習自体は、うまくできていそうな雰囲気はあるものの実用に足るような結果ではなく、ここはこれまでのLoRAのようなPEFTと変わらないので、まだまだ試行錯誤していく必要がありそうです。
最後までお読みいただき、ありがとうございました!




