こんにちは、AIチームの戸田です
今回は近年Transformerの次のアーキテクチャになるのでは?と話題の状態空間モデル、Mambaを使った音声分類を試してみたいと思います。
Mamba
Mambaは近年主流となっているTransformerの次のアーキテクチャとして期待されているモデルの一つです。LLMの文脈で目にすることが多いのですが、音声を扱うAudio-Mambaや、画像を扱うVision-Mambaなどの研究もされています。
Mamba自体については本記事では扱いませんので、詳細は論文をご参照ください。
Audio-Mamba
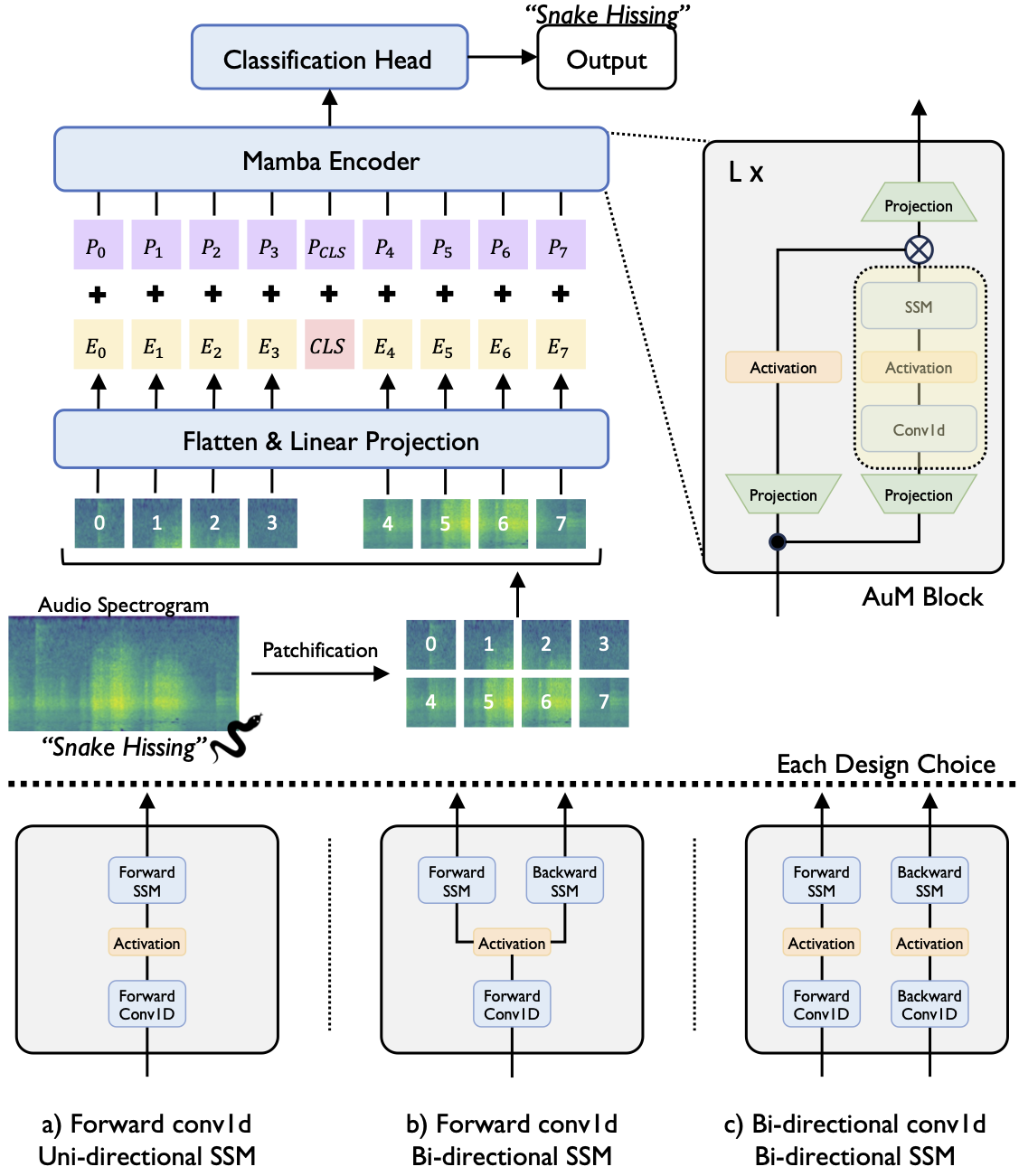
Figure 1
Audio-MambaはMambaをベースとした音声分類モデルです。現在主流となっているAudio Spectrogram Transformerと同様、Audio Spectrogramを小さな正方形(patch)に分割し、tokenとして順にモデルのEncoder部分に入力されます。Encoderは入力されたtokenから順に音の情報を読み取り、最終的にそれが何の音なのかを予測します。
論文ではAudio-Mambaは従来のAudio Spectrogram Transformerと比べて、特に長い音声シーケンスにおいて、計算効率とメモリ効率の両面で優れていると主張しています。pytorchベースで開発された学習/推論用ライブラリがGithubに公開されていますので、今回はこちらを利用して検証を行いたいと思います。
検証
環境構築
リポジトリをCloneしてREADMEを参考に設定していくことで特に問題なく進みましたが、一点だけ詰まったところがありました。numpyのバージョンの整合性が取れなかったようで、以下のコマンドでバージョンを揃える必要がありました。
pip install -U numpy==1.26.0私の環境が特殊だった可能性もありますが、同じように詰まった方は試してみてください。
データセット
今回検証に使うデータセットとして、以前openSMILEを使った音声分類を行った際に利用したESC50のを使います。ESC-50は環境音の分類手法のベンチマークで、5秒間の録音を50のクラスに分類する問題になっていますが、前回と同様、犬と猫の鳴き声に絞って使用したいと思います。つまり音声から、それが犬の鳴き声か猫の鳴き声か予測するタスクになります。
git clone https://github.com/karolpiczak/ESC-50.gitimport pandas as pd
meta_df = pd.read_csv('./ESC-50/meta/esc50.csv')
dog_or_cat = meta_df.query('category =="dog" or category =="cat"')ESC-50のメタデータを取得し、categoryがdogかcatのものに絞っています。このcategoryをラベルとして扱います。メタデータには他の要素もありますが、今回他に使うのは音声ファイルのパスが入っているfilenameカラムのみです。
以前のopenSMILEを使った時と同じSEEDでテストデータを分割しておきます。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
dog_or_cat["filename"], dog_or_cat["category"], test_size = 0.2, random_state = 0)事前学習済みモデルでの予測
Audio-Mambaには事前学習済みモデルが何個か用意されています。ここではYouTubeから収集されたデータセットであるVGGSoundの事前学習済みモデルを使って犬と猫の鳴き声を分類してみます。事前学習済みモデルはREADMEにあるGoogleDriveのリンクからダウンロードできます。
examplesの推論コードを参考に音声ファイルからラベルを予測する関数を作りました。かなりコード量が多くなってしまうので折りたたみます。
予測関数(predict)の定義
import os
import torch
import torchaudio
import numpy as np
import src.models as models
from src import dataloader
from src.utilities.stats import calculate_stats
from IPython.display import Audio, display
import csv
import warnings
class Namespace:
def __init__(self, **kwargs):
self.__dict__.update(kwargs)
data_args = Namespace(
num_mel_bins = 128,
target_length = 1024,
mean = -5.0767093,
std = 4.4533687,
)
model_args = Namespace(
model_type = 'base',
n_classes = 309,
imagenet_pretrain = False,
imagenet_pretrain_path = None,
aum_pretrain = True,
aum_pretrain_path = '{GoogleDriveからダウンロードしてきたモデルのPATH}',
aum_variant = 'Fo-Bi',
device = 'cuda',
)
AuM = models.AudioMamba(
spectrogram_size=(data_args.num_mel_bins, data_args.target_length),
patch_size=(16, 16),
strides=(16, 16),
embed_dim=768,
num_classes=model_args.n_classes,
imagenet_pretrain=model_args.imagenet_pretrain,
imagenet_pretrain_path=model_args.imagenet_pretrain_path,
aum_pretrain=model_args.aum_pretrain,
aum_pretrain_path=model_args.aum_pretrain_path,
bimamba_type='v1',
)
AuM.to(model_args.device)
AuM.eval()
label_dict = {}
with open("./Audio-Mamba-AuM/exps/vggsound/data/class_labels_indices.csv", 'r') as f:
csv_reader = csv.DictReader(f)
line_count = 0
for row in csv_reader:
label_dict[row['index']] = row['display_name']
line_count += 1
def predict(audio_path):
waveform, sr = torchaudio.load(audio_path)
waveform = waveform - waveform.mean()
fbank = torchaudio.compliance.kaldi.fbank(
waveform,
htk_compat=True,
sample_frequency=sr,
use_energy=False,
window_type='hanning',
num_mel_bins=data_args.num_mel_bins,
dither=0.0,
frame_shift=10
)
n_frames = fbank.shape[0]
p = data_args.target_length - n_frames
if p > 0:
m = torch.nn.ZeroPad2d((0, 0, 0, p))
fbank = m(fbank)
elif p < 0:
fbank = fbank[0:data_args.target_length, :]
label_indices = np.zeros(model_args.n_classes)
label_indices = torch.FloatTensor(label_indices)
fbank = (fbank - data_args.mean) / (data_args.std * 2)
fbank = fbank.unsqueeze(0)
label_indices = label_indices.unsqueeze(0)
fbank = fbank.to(model_args.device)
label_indices = label_indices.to(model_args.device)
with torch.no_grad():
output = AuM(fbank)
output = torch.sigmoid(output)
output = output.cpu().numpy()
top_idx = np.argsort(output[0])[-1]
return label_dict[str(top_idx)]この予測関数を使って犬と猫の鳴き声分類を行います。VGGSoundの学習済みモデルは310クラスの音声分類で学習されていますが、直接犬と猫の鳴き声の分類ラベルがあるわけではありません。"dog growling" や "cat meowing" のような、より具体的な分類ラベルになっているので、予測したラベルに"dog" が含まれていれば犬の鳴き声、"cat" が含まれていれば猫の鳴き声と分類します。以下のコードで正解率を計算します。
results = []
for x, y in zip(X_test, y_test):
pred = predict("./ESC-50/audio/" + x)
results.append(y in pred)
acc = np.mean(results)
print(f"{acc=}") # 0.6875正解率は68.75%でした。
Fine-Tuning
続けて解きたいタスクでのFine-Tuningをしてみようと思います。Audio-MambaのリポジトリにはFine-Tuning用のシェルスクリプトのサンプルがいくつか用意されています。今回はaum-base_audioset-vggsound.shをコピーしてきて以下の部分を変更して利用します。
+ dataset=dog_cat
- dataset=vggsound
+ aum_pretrain_path={GoogleDriveからダウンロードしてきたモデルのPATH}
- aum_pretrain_path=/mnt/lynx2/users/mhamza/audiomamba/exp/aum-B_audioset/models/best_audio_model.pth
+ tr_data=./data/datafiles/dog_cat_train.json
- tr_data=./data/datafiles/vgg_train.json
+ te_data=./data/datafiles/dog_cat_test.json
- te_data=./data/datafiles/vgg_test.json
+ n_class=2
- n_class=309
+ exp_root={結果の出力先ディレクトリPATH}
- exp_root=/mnt/lynx2/users/mhamza/audiomamba
+ exp_name=ast-{任意の実験名}
- exp_name=aum-base_audioset-vggsoun続けてデータのフォーマットを合わせます。環境構築の際にCloneしてきたAudio-Mambaのリポジトリ内のexpsディレクトリに、対象音声ファイルのパスとそのラベルを配置します。
mkdir -p ./Audio-Mamba-AuM/exps/dog_cat/data/datafilesimport json
DIG_CAT_DIC = {
"dog": "/m/dog_cat_0",
"cat": "/m/dog_cat_1",
}
ROOT = "./ESC-50/audio"
OUTPUT = "./Audio-Mamba-AuM/exps/dog_cat/data/"
pd.DataFrame([
{"mid": DIG_CAT_DIC[k], "display_name": k} for k in DIG_CAT_DIC.keys()
]).reset_index().to_csv(f"{OUTPUT}/class_labels_indices.csv", index=None)
train_lst = [{"wav" : f"{ROOT}/{x}", "labels": DIG_CAT_DIC[y]} for x, y in zip(X_train, y_train)]
test_lst = [{"wav" : f"{ROOT}/{x}", "labels": DIG_CAT_DIC[y]} for x, y in zip(X_test, y_test)]
with open(f"{OUTPUT}/datafiles/dog_cat_train.json", "w") as f:
json.dump({"data": train_lst}, f, indent=4)
with open(f"{OUTPUT}/datafiles/dog_cat_test.json", "w") as f:
json.dump({"data": test_lst}, f, indent=4)これで準備は完了です。作成したシェルスクリプトを実行すると学習が開始します。私の環境(VertexAIワークベンチのデフォルト設定にT4を1枚接続したもの)では10分ほどで完了しました。正解率は87.5%となり、事前学習済みモデルでの推論時よりも18%ほど改善しました。学習曲線(BCE loss)は以下のような形でした。
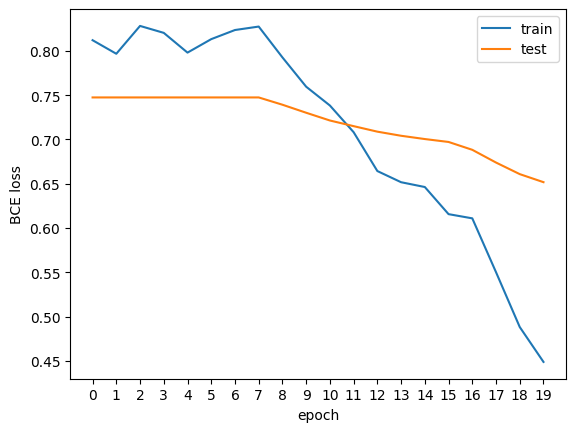
ちなみに今回はパラメータ設定などはいじっておらず、デフォルトで実行しました。以前のopenSMILEを使った分類では同様のテストデータで正解率93.75%だったので、まだまだ伸び代はあるのではないかと考えています。
おわりに
本記事ではAudio-Mambaを使った音声分類を試して見ました。
まだToy Dataでの検証レベルですが、一通り動かすことはできたので、プロダクトでの音声処理に使えるかも今後検証していきたいと思います。また、RWKVやRetNetなどTransformerの次のアーキテクチャと期待されているモデルは他にもあるのでこちらも試してみたいです。
最後までお読みいただき、ありがとうございました!




