はじめに
こんにちは、AIチームの大竹です。
現在、AI Shiftではコールセンター業務自動化を目的とした自動音声対話システム、AI Messenger Voicebotを運用しています。
今回は、音声対話システムがカスタマーの意図を理解するための入り口として最も重要な技術である音声認識にフォーカスしたいと思います。音声認識の誤りが多くなると、後段の言語処理や対話管理に悪い影響を与えるため、音声認識誤りをいかに回避するかは極めて重要です。そして、音声認識の性能は収音環境やカスタマーの話し方の特徴など、様々な要因で左右されます。これは最先端の音声認識モデルを用いても容易に解決できない問題です。
そこで環境要因を排除するための方法として音声品質に着目したいと思います。音声認識が失敗しそうな場合、カスタマーに周辺環境の良い場所に移動してもらうなどの問いかけをすることで問題が部分的に解決できるのではないかと考えています。
今回の記事では、その前段階として、音声認識の誤り傾向と音声の品質との間にどれくらい関係があるかを分析したいと思います。
検証
方法
社内で作成したエンティティ認識用のデータセットに対して、音声認識をしてエンティティ認識の精度を測定します。別途、音声品質も測定しておきます。測定したエンティティ認識の精度と音声品質の間に関係があるかどうかを分析します。
データセットについて
名前、電話番号、郵便番号、生年月日などVoicebotでよく発話されるエンティティを27種類選定し、ランダムに作成した各エンティティに対し弊社メンバーで音声を読み上げデータを作成しました。各発話はエンティティのみを発話しており、フィラーなどは含まれません。
これらのエンティティタイプごとに99件の発話を用意し、全体の発話数は27x99=2673となっています。また、データセットに含まれる音声は電話回線を通して録音したものなので、電話音声品質になっています。
評価指標
エンティティ認識
音声認識結果が正解エンティティと完全一致しているかを判定します。
ただし、音声認識結果と正解テキストを比較する前に以下のテキスト処理を実行します。
- 数値表現を統一するため、漢数字やカンマなどの特殊文字を除去したり、漢数字をアラビア数字に変換したりする。
- 電話番号や郵便番号などの形式を統一するため、ハイフンや「の」などの区切り文字を除去する。
- 日付形式を標準化し、一貫した比較ができるようにする
音声品質
- STOI (Short-Time Objective Intelligibility)
- 音声の可聴性を評価する指標です。STOIは0から1までの範囲でスコアを付け、1に近いほど音声が明瞭であることを示します。
- STOI値が高いほど、発言内容を聞き取りやすいことを意味します。
- PESQ (Perceptual Evaluation of Speech Quality)
- 知覚品質を評価する指標です。PESQは音声品質評価の標準的な指標で、-0.5から4.5の範囲でスコアを付けます。スコアが高いほど音声品質が高く、リスナーにとって心地良い音声となります。
- SI-SDR(Scale-Invariant Signal-to-Distortion Ratio)
- 音声の歪みやノイズの度合いを評価する指標です。
- SI-SDRの値が低いほど、ノイズや歪みが多いことを示します。
今回の検証では、torchaudio-squimを用いて、前述したデータセットの音声に対して、上記の音声品質を推定します。torchaudio-squimを用いることで、参照音声が不要かつlightweightに音声品質の推定が可能です。
音声認識モデル
今回の検証ではGoogle Cloudの音声認識APIを用います。用いるモデルは以下の5種類です。
- default
- command_and_search
- phone_call
- latest_short
- latest_long
各モデルの詳細についてはこちらをご参照ください。
分析方法
今回の検証では次の2つの方法を用いて、音声認識の精度と音声品質との間の関係を分析します。
- 相関分析
点双列相関係数を使用し、音声品質とエンティティ認識が正解か否かの間にどれくらいの関係があるかを定量化します。ただし、点双列相関係数は連続変数と2値変数との間の線形関係を測定するものであるため、非線形の関係を捉えられないことに注意が必要です。 - 統計的検定
エンティティ認識が正解している場合と正解していない場合のデータを比較して、両者のグループの音声品質に統計的に有意な差があるかどうかを検定します。検定手法として、今回の検証では、データに正規分布を仮定しないMann-Whitney U検定を使用します。
結果
相関分析
以下にエンティティの予測が正解か否かと音声品質の各指標との相関係数を示します。
| Model | STOI | PESQ | SI-SDR |
|---|---|---|---|
| default | -0.0305 | -0.0511* | -0.0806* |
| command_and_search | -0.0768* | -0.0652* | -0.1324* |
| phone_call | -0.0103 | -0.0402* | -0.0100 |
| latest_long | -0.0115 | -0.0237 | -0.0349 |
| latest_short | -0.0444* | -0.0699* | -0.0467* |
(注): *は p < 0.05 で統計的に有意な差があることを示します。
いずれのモデルでもエンティティの予測が正解しているかどうかと、音声品質の指標との間の相関係数の絶対値が小さいので、両者に何らかの関係があるとは言えなさそうです。
統計的検定
分布の可視化
検定を行う前にエンティティ認識が正解している場合と正解していない場合で、各指標がどのように分布しているかをプロットしてみます。
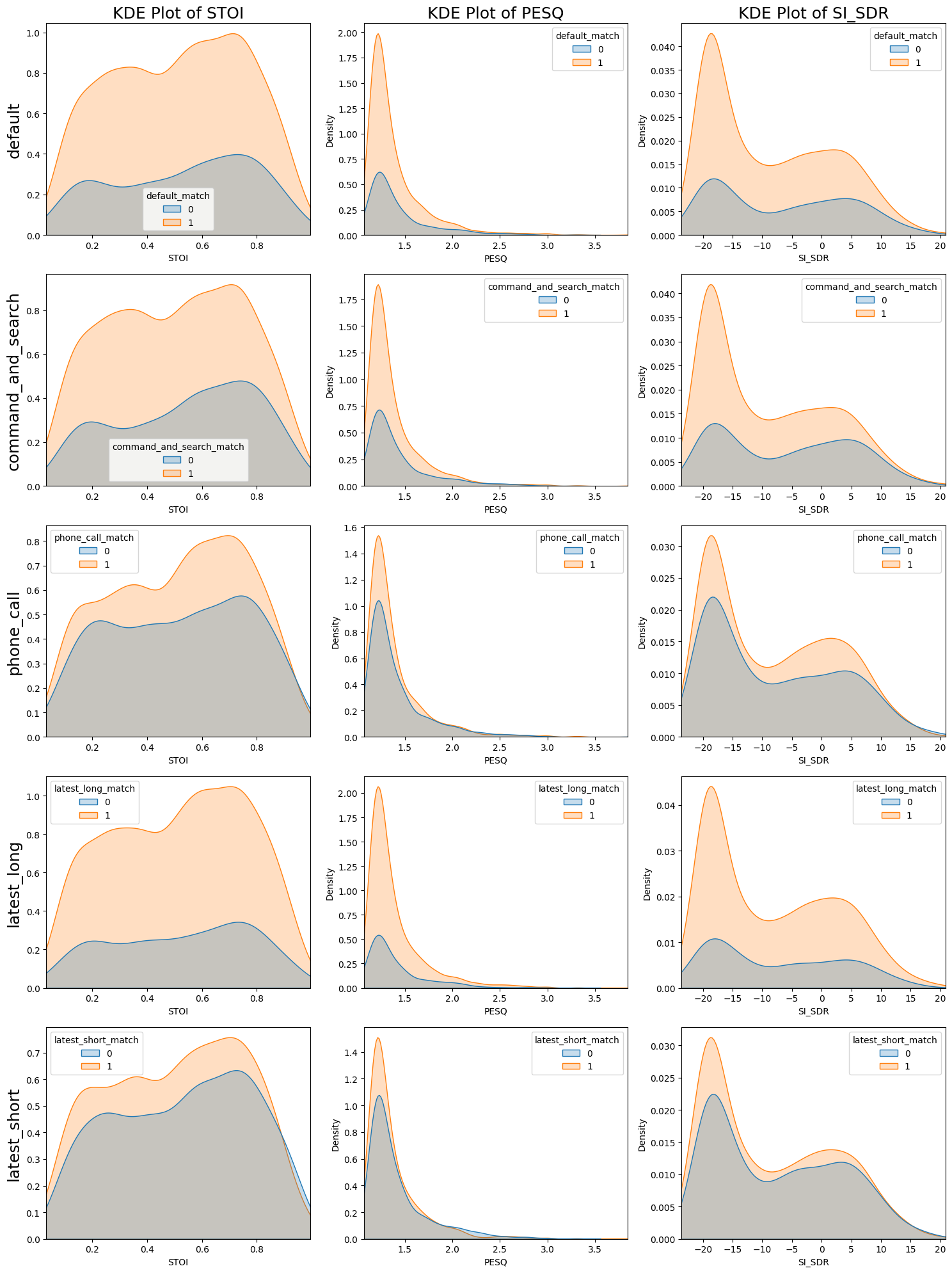
いずれの分布も非対称な分布で、複数のピークを持つ分布もあります。エンティティ認識が正解しているグループ(match=1)と正解していないグループ(match=0)の分布を見比べると、密度の絶対値に差異はありますが、分布の形状の違いがあるかどうかはパッと見ただけではよく分かりません。
全体のデータに対する検定結果
音声品質の指標ごとに検定結果を示します。
正規化U統計量はエンティティ認識が正解している場合と正解していない場合のデータ群に対してどれだけの差があるかを示しています。この値が0.5から離れているほど差が大きいと言えます。
(注): *は p < 0.05 で統計的に有意な差があることを示します。
STOI
| Model | 正規化U統計量 | p値 |
|---|---|---|
| default | 0.478 | 0.086 |
| command_and_search | 0.451 | 0.000* |
| phone_call | 0.493 | 0.554 |
| latest_long | 0.491 | 0.495 |
| latest_short | 0.474 | 0.021* |
PESQ
| Model | 正規化U統計量 | p値 |
|---|---|---|
| default | 0.463 | 0.003* |
| command_and_search | 0.462 | 0.001* |
| phone_call | 0.480 | 0.081 |
| latest_long | 0.488 | 0.359 |
| latest_short | 0.458 | 0.000* |
SI-SDR
| Model | 正規化U統計量 | p値 |
|---|---|---|
| default | 0.451 | 0.000* |
| command_and_search | 0.417 | 0.000* |
| phone_call | 0.495 | 0.667 |
| latest_long | 0.474 | 0.049* |
| latest_short | 0.470 | 0.007* |
これらの表から、統計的に有意な差がありかつ、その差が大きいのはcommand_and_sarchのSTOI, SI-SDRあたりでしょうか。しかし、いずれの場合も差はそれほど大きくなさそうです。
このように、全データに対して分析してみた結果、それほど大きな差が見られなかったので、エンティティタイプごとの傾向を調べてみました。
エンティティタイプごとの検定結果
以下の画像は、STOI, PESQ, SI-SDRに関して、0.5と正規化U統計量の差の絶対値をヒートマップとしてプロットしたものです。米印(*)がついているものはp値が0.05未満のもので統計的に有意差が見られるものです。ヒートマップの色が濃いほどエンティティ認識が正解しているグループと正解していないグループの差が大きいことを示しています。
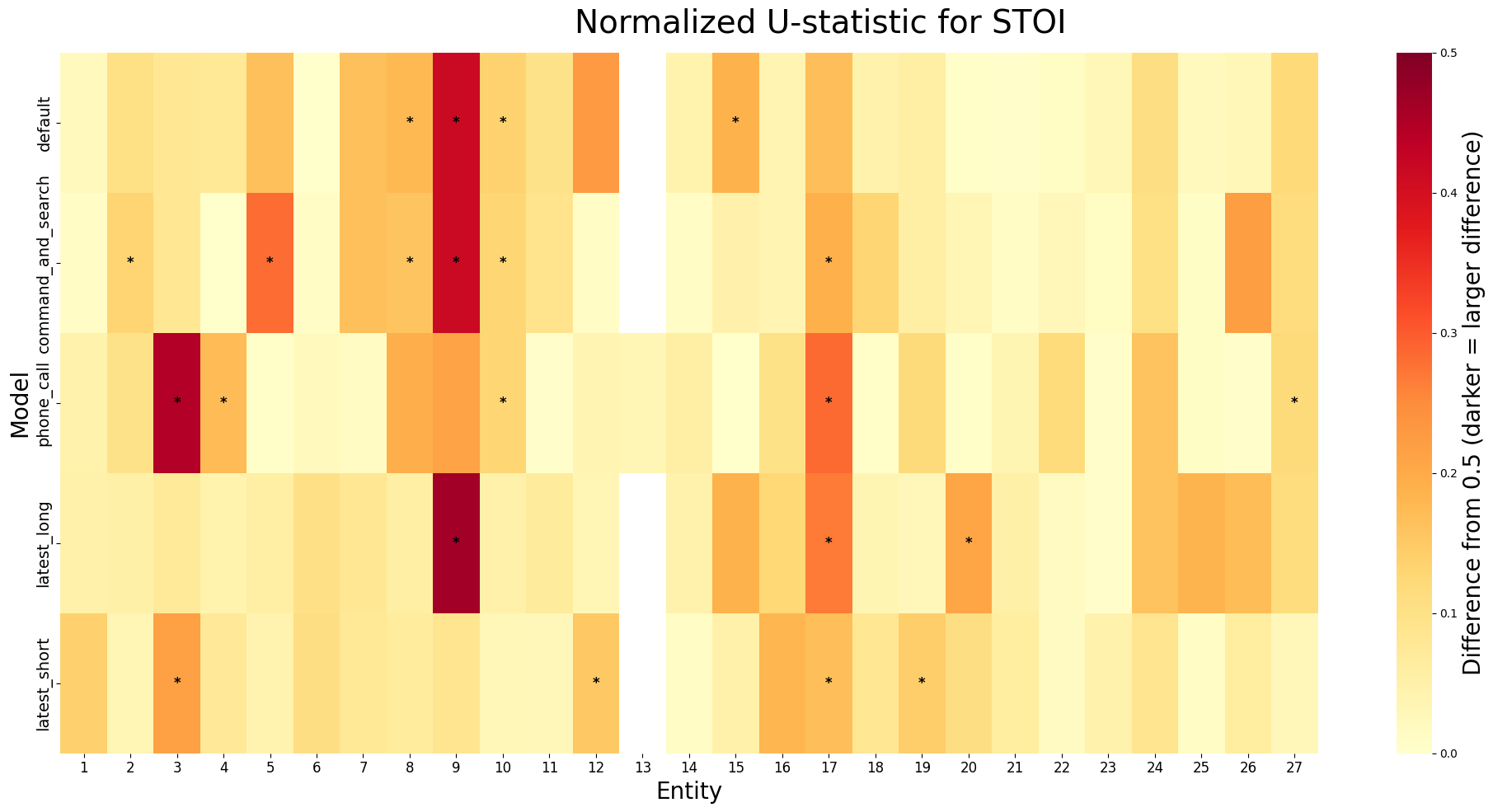
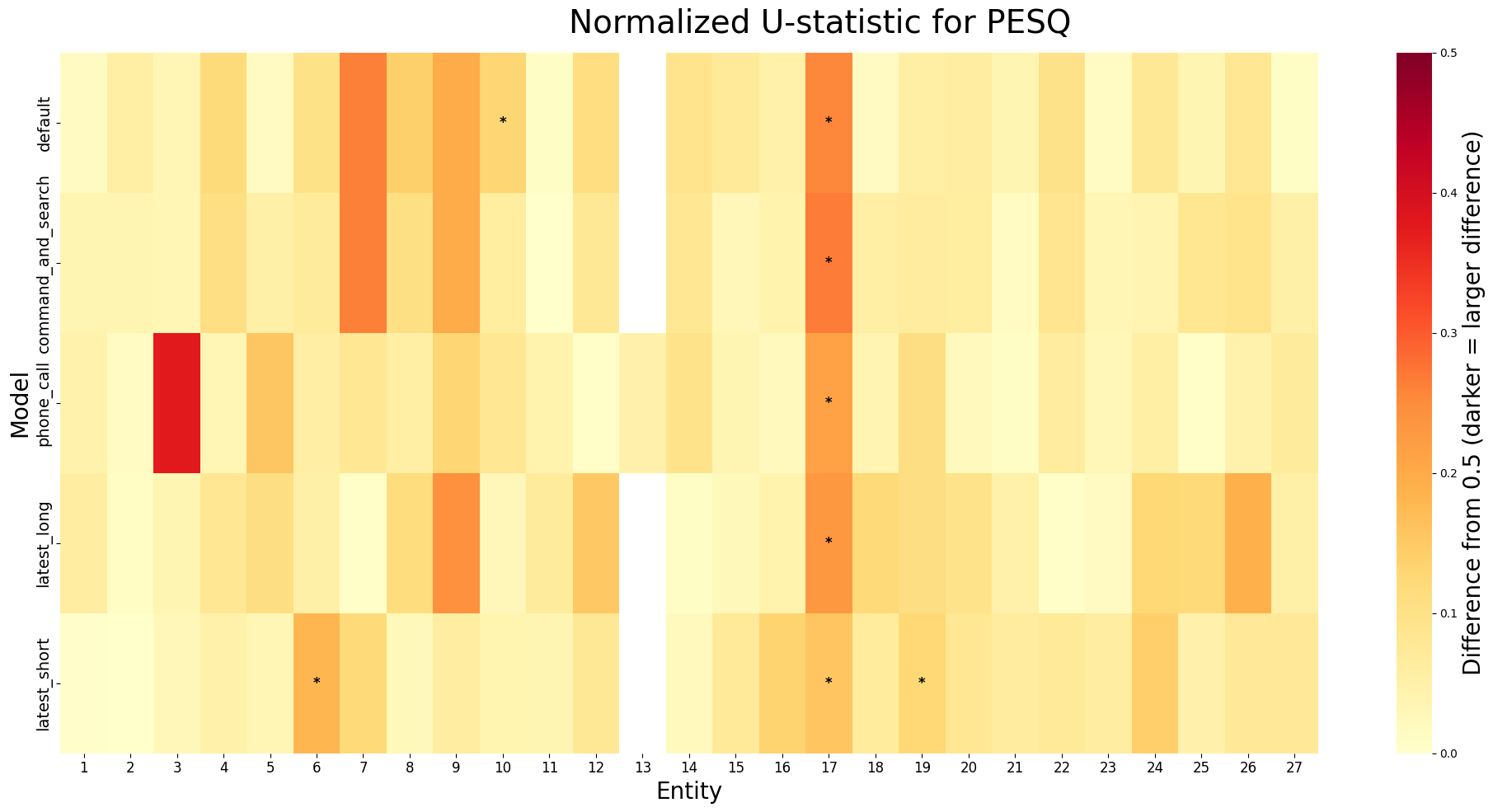
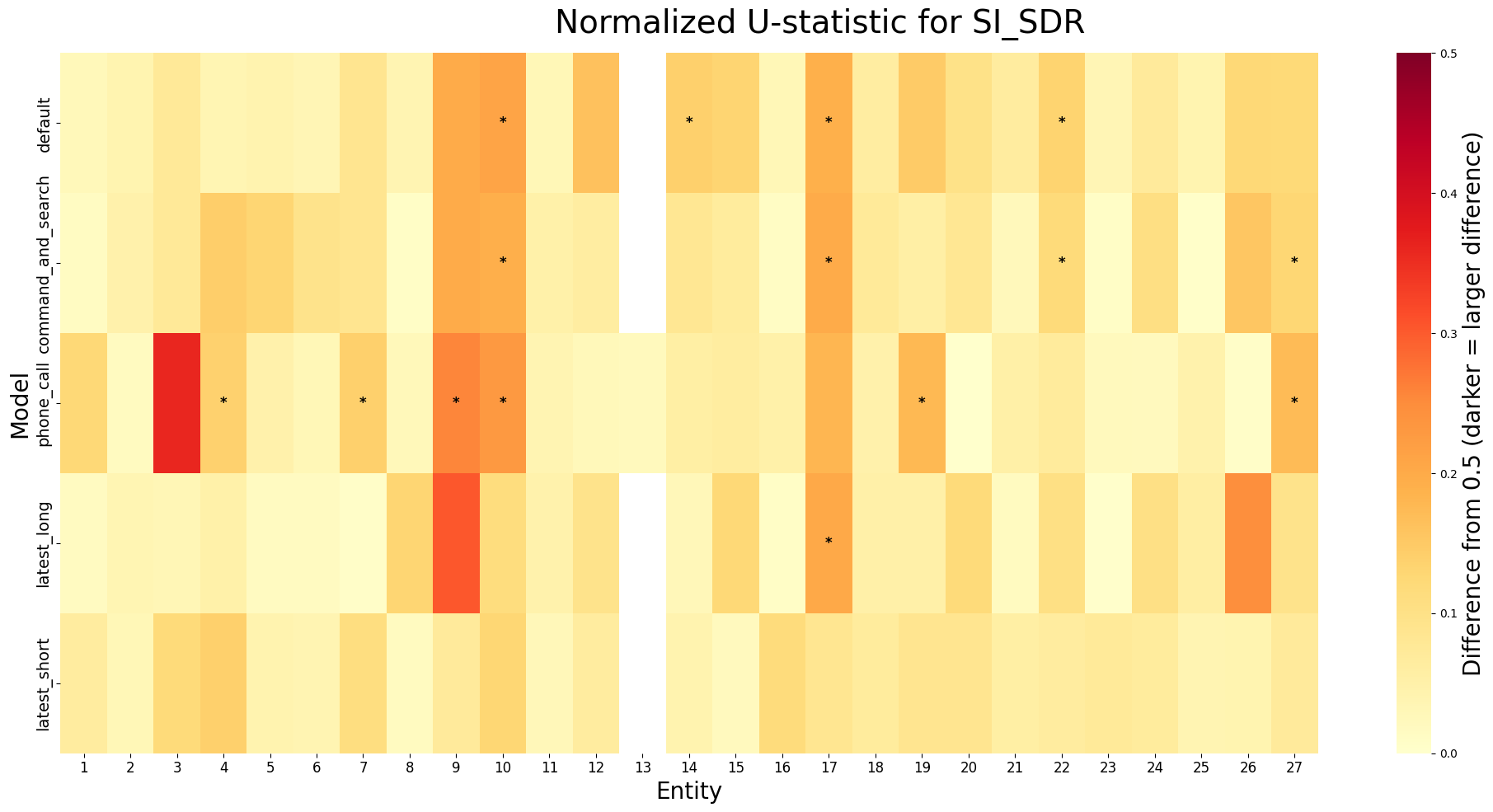
この結果から、どうやらエンティティタイプごとに傾向があるようで、エンティティ番号9(「もう一度」と発話), エンティティ番号17(日付を発話)などは一部のモデルで、STOI, SI-SDRの差が大きいようです。また、phone_callにおいて、エンティティ番号3(名前を発話)の差が大きくなっています。これは、エンティティタイプとモデルの相性で音声品質が音声認識に与える影響の大きさが変化するからだと考えられます。
結論
今回は、音声認識の誤り傾向と音声の品質がどれくらい関係があるかを相関分析や統計的検定を用いた定量的に分析しました。
その結果、全体的には音声品質と音声認識の誤り傾向には関係がないと考えられるものの、特定のエンティティに対しては何らかの関係が見られそうだということがわかりました。
今回用いたデータセットは社内で作成した理想的な環境における比較的音声品質の良いデータでした。そのため、特筆すべき傾向が現れにくかったという可能性があります。次回は背景ノイズを付加したり、音量を調節したりして、実際の音声品質を模倣した場合にどのような傾向が見られるかというのを分析したいと思います。




