はじめまして!東北大学修士1年の林崎 由(@u_hyszk)と申します!大学では音声信号処理や自然言語処理に関する研究を行っています。
9/6〜9/30の15日間、株式会社AI Shiftで内定者アルバイトとして就業しました。テーマは「モノラル音声での話者ダイアライゼーション」であり、技術選定から実際のプロダクトへのリリースまで一貫してやり切ることができました。
本記事では、内定者アルバイトとして取り組んだ内容や検証内容の一部をご紹介いたします。
タスクの背景
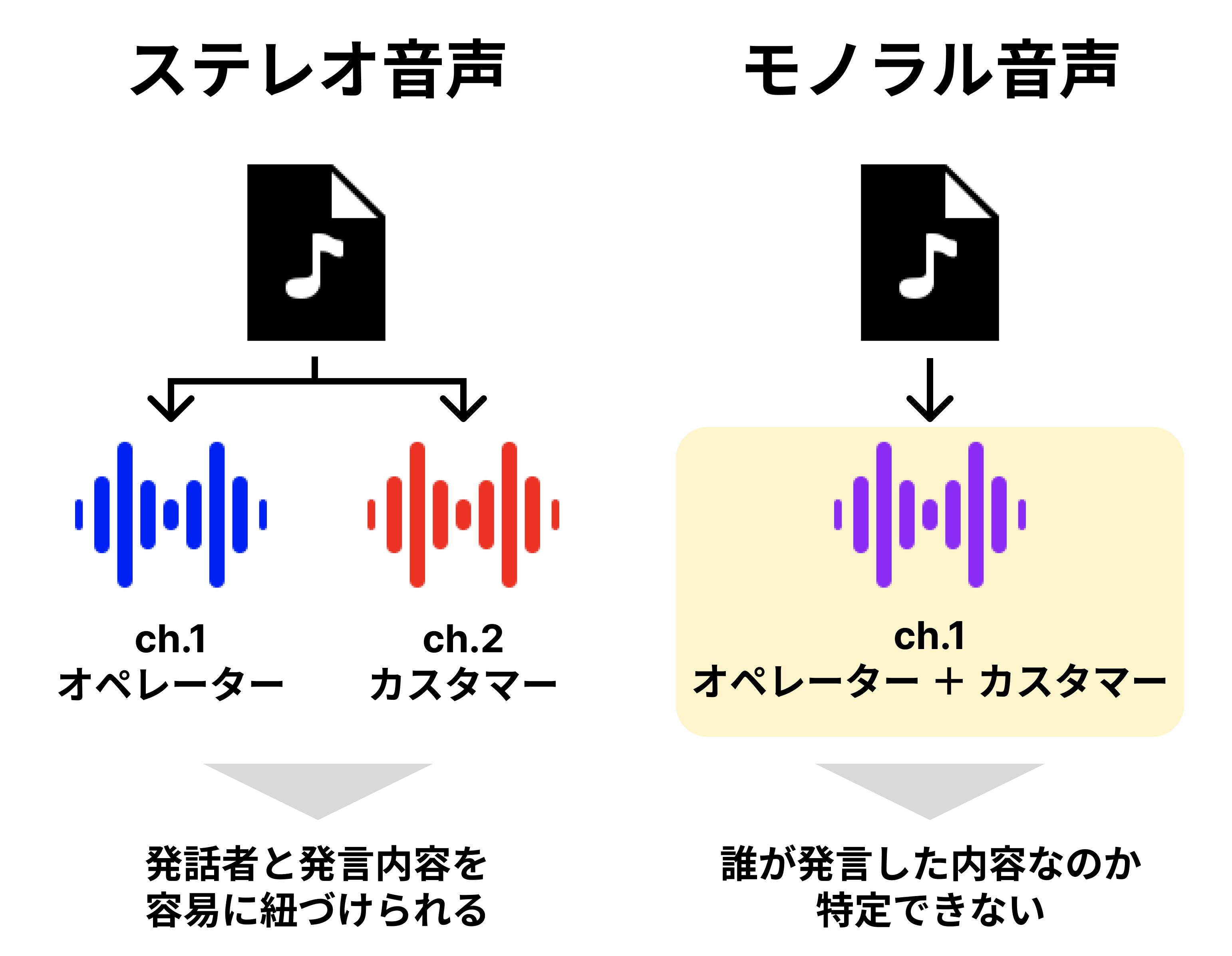
AI Shiftが扱うコールセンターの音声には、ステレオ音声とモノラル音声のものがあります。
ステレオ音声では、オペレーターとカスタマーの音声がそれぞれ異なるオーディオチャンネルに格納されています。各チャンネルの音声に対して音声認識を実行することで、オペレーターとカスタマーのどちらが何を話したのか容易に特定することができます。
一方、モノラル音声は、2人の音声が単一のオーディオチャンネルに格納されているため、このままの形式では発話者と発言内容を紐づけることができません。「誰が、何を話したのか」を考慮した高度な分析を提供するには、モノラル音声中の2人のの発言を識別し、区別する必要があります。
今回のタスクではこの課題を解決するために、話者ダイアライゼーション機能の導入を行いました。
話者ダイアライゼーションとは
話者ダイアライゼーション(Speaker Diarization)とは、複数話者の音声から「だれが、いつ話したか」を推定するタスクのことを指します。大きく分けて、(1)段階的に処理を行うクラスタリングベースの手法と、(2)単一のEnd-to-Endモデルを使用して一気に処理を行うアプローチ(3)音源分離を用いる手法があります。今回はクラスタリングベースの手法についてご紹介します。
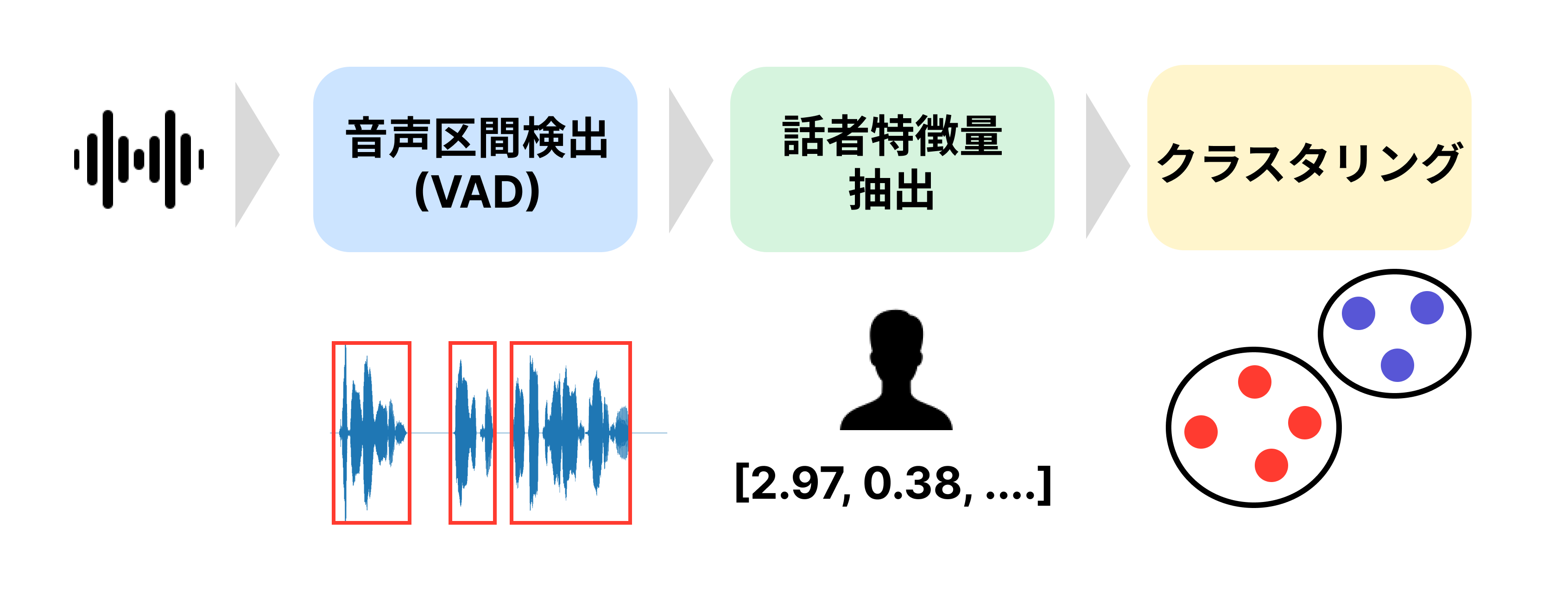
クラスタリングベースの手法では音声区間検出(VAD)・話者特徴量抽出・クラスタリングを段階的に行います。
- 音声区間検出(VAD): 音声から発話区間(セグメント)を抽出する処理です。この時点では発話した時間のみを推定し、どちらの話者がどの区間で発話したのかは特定できません。
- 話者特徴量抽出: 各セグメントから、声の高さやイントネーションなどの「音声に含まれる話者の特徴」を定量化した話者特徴量を抽出します。x-vectorと呼ばれる事前学習済みのニューラルモデルから得られる特徴量を使用することが一般的です。
- クラスタリング: 抽出された話者特徴量を使用して、教師なし学習のクラスタリングを行います。この処理により、どちらの話者がどのセグメントを発話したのか特定できます。
クラスタリングベースの手法は、End-to-Endモデルを使用するアプローチと比較して、処理が軽量・高速であることが多いというメリットがある一方で、複数話者の発話が重複するデータの処理が難しいというデメリットがあります。しかし、コールセンターの音声は
- 発話区間の重複が少ない
- 話者が2人(オペレーター・カスタマー)のみであることが多い
という特徴があり、発話区間の重複を考慮する・話者がより多い一般的な話者ダイアライゼーションと比較して単純なため、クラスタリングベースの手法でも十分に精度を出すことができる可能性があると考えられます。
クラスタリングベースの手法においてボトルネックとなる処理は発話区間検出(VAD)と話者特徴量抽出です。今回はさらなる高速化のために、この2つの処理に対して工夫を加えます。
MFCC(メル周波数ケプストラム係数)による高速化
MFCC(メル周波数ケプストラム係数)とは、人の聴覚特性を考慮した音響特徴量の一つで、音声認識や話者識別などのタスクでよく使用されます。ケプストラムは人の声道特性を捉える音響特徴量ですが、メル周波数ケプストラム係数(MFCC)はここにメル尺度という人の聴覚感度に基づく尺度を取り入れて変換した特徴量です。MFCCの計算はx-vectorなどのように複雑なモデルを使用したものと比べて単純になっているため、高速化が見込まれます。
今回は話者特徴量として、x-vectorの代わりに使用することで処理の高速化を図ります。
ONNXによる高速化
ONNX(Open Neural Network eXchange)とは、機械学習モデルを表現するためのオープンソースのフォーマットです。ONNXモデルで推論を行う際には、同じくオープンソースであるONNX Runtimeを使用することで、様々な最適化が施されるため、推論が高速化される可能性があります。
今回は、VADモデルをONNXに変換することで推論の高速化を狙います。
性能・速度検証
先ほど紹介したクラスタリングベースの手法について、話者ダイアライゼーションの性能と速度を検証します。また、(1)話者特徴量をMFCCに変えた場合(2)VADモデルをONNXに変換した場合についても同様に検証を行います。なお、今回の検証はVertex AIのCPU環境(n1-standard-2)で行いいます。
使用技術
話者ダイアライゼーションを行うことができる代表的なライブラリ・API・ツールなどは以下の通りです。
| 名称 | 実行環境 | 料金 | Github Star(執筆時) | ライセンス |
| pyannote-audio | CPU / GPU | 無料 | 6k | MIT licence |
| Cloud Speech-to-Text | API | Google Cloud | - | - |
| Amazon Transcribe | API | Amazon Web Services | - | - |
| Azure Conversation Transcription API | API | Microsoft Azure | - | - |
| SpeechBrain | CPU / GPU | 無料 | 8.6k | Apache-2.0 |
| pyAudioAnalysis | CPU | 無料 | 5.8k | Apache-2.0 |
今回はこれらのうち、既存システムとの相性が良いpyannote-audioを使用して検証を行います。使用するモデルや手法は以下の通りです。
- VAD: pyannote/segmentation@Interspeech2021
- 話者特徴: pyannote/wespeaker-voxceleb-resnet34-LMまたはMFCC
- クラスタリング: 凝集的クラスタリング(AgglomerativeClustering)
評価データ
評価データとしてCALLHOME日本語データセットのテストデータを使用します。CALLHOME日本語データセットには、合計120件の電話での雑談対話音声とその書き起こしが含まれており、そのうち20件がテストデータセットとして指定されています。今回はこのテストデータを使用して話者ダイアライゼーションの性能を評価します。
評価指標
評価指標にはDiarization Error Rate(DER)を使用します。DERは以下の式で計算することができ、低ければ低いほど性能が高いと評価されます。
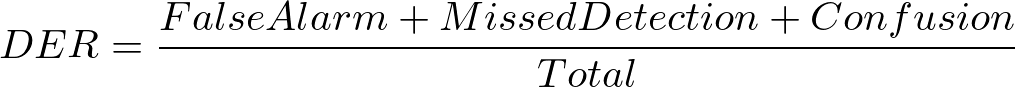
- False Alarm: モデルが発話区間であると推定したが、正解ラベルは非発話区間である時間の長さ
- Missed Detection: モデルが非発話区間であると推定したが、正解ラベルは発話区間である時間の長さ
- Confusion: モデルが推定した話者と正解ラベルの話者が異なる時間の長さ
- Total: 音声の長さ
実行速度の評価にはReal Time Factor(RTF)を使用します。RTFは実行時間÷音声の長さで計算することができます。
結果
結果は以下の表の通りです。VADモデルをONNXに変換すると、性能を低下させずにVAD単体で1.33〜1.43倍の速度向上が見られます。また、話者特徴量の抽出をMFCCに変更すると、DERが0.079低下するものの、従来モデルから約120倍速くなっています。全体ではRTF 0.058まで実行速度を向上させることができました。
実行環境上では数値が変動しますが、検証環境上ではVADモデルのONNX化・話者特徴量の変更の両者の有効性が確認できる結果となりました。
| VADモデルのONNX | 話者特徴量 | DER | RTF - VAD | RTF - 話者特徴量抽出 | RTF - クラスタリング | RTF - 合計 |
| × | MFCC | 0.453 | 0.0773 | 0.0006 | 0.0000 | 0.077 |
| × | wespeaker-voxceleb-resnet34-LM | 0.374 | 0.0849 | 0.0732 | 0.0000 | 0.158 |
| ⚪︎ | MFCC | 0.453 | 0.0581 | 0.0006 | 0.0000 | 0.058 |
| ⚪︎ | wespeaker-voxceleb-resnet34-LM | 0.374 | 0.0592 | 0.0738 | 0.0000 | 0.133 |
プロダクトへの組み込み
本記事では検証内容の一部を紹介しましたが、内定者アルバイトでは追加の検証でノイズへの頑健性や実データでの性能を確認した上で、技術選定を行っています。また、プロダクトへの組み込み・リリースまでやり切ることができました。
学んだこと
今回のタスクでは、計15日間という短期間で技術選定からリリースまでを一貫して行いました。タスクを取り巻く背景情報は無数にあるのですが、判断材料を集め、集めた情報を元に考える時間すらも「コスト」になることを強く意識させられたところが、普段の研究とのギャップを大きく感じた点でした。限られた情報の中から判断するスピードと質を両方追求していきたいと思いました。
また、今回の内定者アルバイトを通して最も苦戦したのが既存ツール・ライブラリへの理解でした。自分の研究領域から近い領域にもベストプラクティスと呼ばれる手法を素早く展開できるよう、自分が技術選定する立場になって考える、実際に手を動かしてみるなど、キャッチアップの質を向上させることが重要であると改めて感じました。
最後に
本記事では、自分が内定者アルバイトで取り組んだ内容や検証内容の一部をご紹介しました。AI Shiftや親会社のサイバーエージェントでのインターンシップ・内定者アルバイトを検討している方の参考になれば幸いです。
AI Shiftはとても活力がある会社です。社員さんも優しくて頼もしい方ばかりで、ソフトスキル・ハードスキルともに学ぶことが非常に多かったと感じています。
最後にトレーナーの大竹さん、メンターの干飯さん、期間中に関わっていただいたすべての皆様、本当にありがとうございました!




