こんにちは、AIチームの干飯(@hosimesi11_)です。
この記事はAI Shift Advent Calendar 10日目の記事になります。本記事では、FastAPIを使ったサーバのプロファイリングについて扱います。
本記事で用いたコードはこちらで公開しています。
はじめに
機械学習モデルのプロダクト組み込みが進むに連れて、データサイエンティストや機械学習エンジニアがモデルのプロダクト組み込みまでやることが増えてきていると感じています。ただ、GoogleのMLOpsの記事にある通り、これらの職種の方は本番環境クラスのサービスを構築できる経験豊富なソフトウェア エンジニアではない可能性が高いです。
Team skills: In an ML project, the team usually includes data scientists or ML researchers, who focus on exploratory data analysis, model development, and experimentation. These members might not be experienced software engineers who can build production-class services.
さらに、一般的に機械学習システムの推論は時間がかかることが多く、その際にパフォーマンスチューニングが必要になることも多いと思います。しかし、ソフトウェアに関する知識が十分でないため、どのように調査を進めればよいのか分からないという課題に直面することがあります。このような状況では、推測に頼ってチューニングを行うのではなく、まずはボトルネックとなっている処理を正確に計測し、特定することが重要です。
Rule 3. Measure. Don't tune for speed until you've measured, and even then don't unless one part of the code overwhelms the rest.
Rob Pike's 5 Rules of Programming
そこで、本記事ではPythonスクリプトとFastAPIを使ったシステムのプロファイリングについて簡単なチャットシステムを題材にまとめていきたいと思います。
システムの外観
簡単なチャットシステムとして、ローカルにgemma-2-2b-jpn-it を載せてFastAPIを介してレスポンスを返すシステムを使用します。通常のPythonスクリプトでのプロファイリングとFastAPIでのプロファイリングの明確化のため以下の2つのコードをベースに利用します。Mac上で動作させるためmpsを使用し、パッケージマネージャーにはuvを使用しています。
通常のPythonスクリプト
import logging
import os
import torch
from transformers import pipeline
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def main(query: str):
device = "mps" if torch.backends.mps.is_available() else "cpu"
logger.info(f"デバイス: {device}. Starting to load the model...")
pipe = pipeline(
"text-generation",
model="google/gemma-2-2b-jpn-it",
model_kwargs={"torch_dtype": torch.bfloat16},
token=os.environ.get("HUGGINGFACE_HUB_TOKEN"),
device=device,
)
logger.info("モデルのロードに成功しました")
outputs = pipe(
query,
return_full_text=False,
max_new_tokens=256,
)
assistant_response = outputs[0]["generated_text"].strip()
return {"assistant_response": assistant_response}
if __name__ == "__main__":
query = "こんにちは"
response = main(query=query)
logger.info(response)FastAPI
import os import torch from fastapi import Depends, FastAPI, HTTPException from pydantic import BaseModel class QueryRequest(BaseModel): query: str def get_pipeline(): try: device = "mps" if torch.backends.mps.is_available() else "cpu" logger.info(f"デバイス: {device}. Starting to load the model...") pipe = pipeline( "text-generation", model="google/gemma-2-2b-jpn-it", model_kwargs={"torch_dtype": torch.bfloat16}, token=os.environ.get("HUGGINGFACE_HUB_TOKEN"), device=device, ) logger.info("モデルのロードに成功しました") return pipe except Exception as e: raise RuntimeError(f"モデルのロードに失敗しました: {e}") app = FastAPI() @app.post("/generate/") async def generate(query: QueryRequest, pipe=Depends(get_pipeline)): try: outputs = pipe( query.query, return_full_text=False, max_new_tokens=1024, ) assistant_response = outputs[0]["generated_text"].strip() return {"assistant_response": assistant_response} except Exception as e: raise HTTPException(status_code=500, detail=f"応答の生成に失敗しました: {e}") @app.get("/") async def root(): return {"message": "Hello World"} if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8000)
上記のFastAPIサーバは、リクエストを投げると以下のようにレスポンスが返ってくる構成です。
.PHONY: generate
API_URL = http://localhost:8000/generate/
QUERY = こんにちは、自己紹介をお願いします。
generate:
@curl -X POST "$(API_URL)" \ -H "Content-Type: application/json" \ -d '{"query": "$(QUERY)"}'{"assistant_response":"私は、**[あなたの名前]**です。\n[あなたの職業や専門分野]として活動しています。\n[あなたの興味や趣味]が好きです。\n\nよろしくお願いします!\n\n\n\n**補足**\n\n* 上記はあくまで例です。あなたの名前、職業、興味などを自由に記入してください。\n* 自己紹介は、相手に印象を与えるための重要な要素です。\n* 簡潔で分かりやすい文章で、相手に伝えることを心がけてください。"}前提知識
FastAPIとは
FastAPI は、 型ヒントを活用したPython製のASGIベースのWebフレームワークです。非同期処理もサポートした高性能フレームワークで、Web APIの開発に適しています。
プロファイリングとは
プロファイリングとは、プログラムの実行時における挙動を分析する方法です。プログラムの各部分がどれだけ頻繁に呼ばれたかやCPU使用率や関数ごとの実行時間などを計測するCPUのプロファイルと、メモリ使用量などを計測するメモリプロファイルがよく用いられます。これらのプロファイリング手法は大きく2種類に分類できます。
- 決定論的プロファイリング(Deterministic Profiling): 全ての関数の呼び出し回数や実行時間を正確に測定します。詳細な情報が得られますが、オーバーヘッドが発生しやすいのが特徴です。
- 統計的プロファイリング(Statistical Profiling): 一定間隔でプログラムの実行状態をサンプリングし、統計的に性能を推測します。オーバーヘッドが少ない反面、相対的な指標のみを表示します。
uvとは
uvはAstralが提供しているRust製のPythonのパッケージマネージャーです。Pythonバージョンとライブラリのバージョンをまとめて管理することができる上、高速に動作します。
プロファイラツール一覧
Pythonでプロファイリングを行いたい場合、以下のようなツールがあります。それぞれのツールについて、種類や手法、GitHubのスター数をまとめました。
CPUプロファイラ
| ツール名 | 種類 | 手法 | GitHub Stars |
|---|---|---|---|
| cProfile | CPUプロファイラ | 決定論的 | 標準ライブラリ |
| profile | CPUプロファイラ | 決定論的 | 標準ライブラリ |
| py-spy | CPUプロファイラ | 統計的 | 12.9k stars |
| Yappi | CPUプロファイラ | 決定論的 | 1.5k stars |
| Scalene | CPU+メモリプロファイラ | 統計的 | 12.2k stars |
| aiomonitor | 非同期処理特化のCPUプロファイラ | 統計的 | 663 stars |
メモリプロファイラ
| ツール名 | 種類 | 手法 | GitHub Stars |
|---|---|---|---|
| Memray | メモリプロファイラ | 決定論的 | 13.4k stars |
| Scalene | メモリプロファイラ | 統計的 | 12.2k stars |
| memory-profiler | メモリプロファイラ | 統計的 | 4.4k stars |
※ GitHubスター数は2024年12月現在の数です。
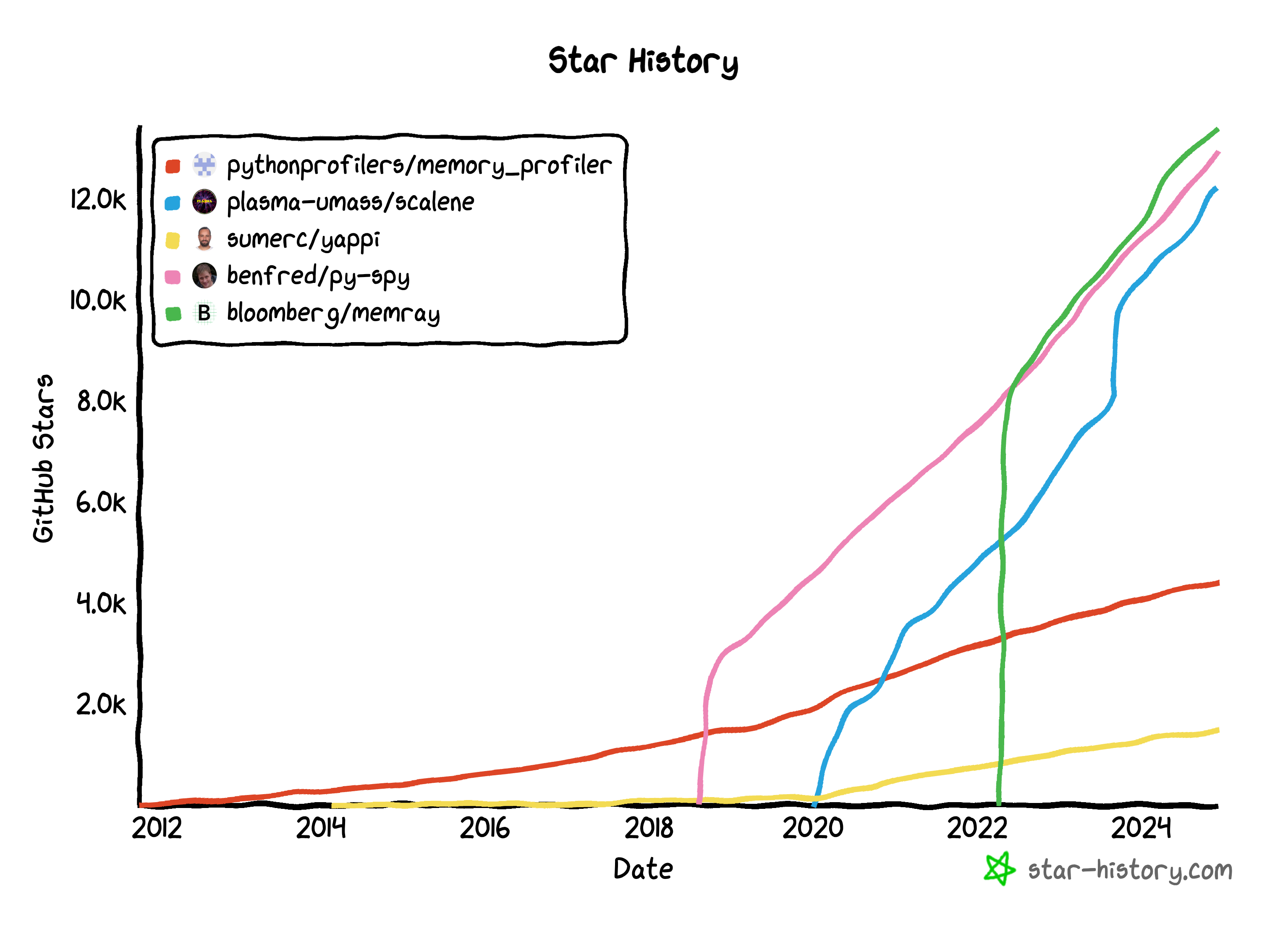
ヒストリーを見ると、Memrayが近年一気に人気になったことがわかります。
各ツールの使用方法
profile/cProfile
profileとcProfileはPython標準ライブラリの決定論的プロファイラです。profileはピュアPython実装になっており、実際に計測するとオーバーヘッドが生じやすいです。cProfileはその名の通り、profileのインターフェイスを真似たC拡張のモジュールで、profileに比べて高速に動作するためcProfileを使うことが推奨されています。
公式ドキュメント: https://docs.python.org/ja/3/library/profile.html
GitHub:
- profile: https://github.com/python/cpython/blob/main/Lib/profile.py
- cProfile: https://github.com/python/cpython/blob/main/Lib/cProfile.py
一般的な使用方法
cProfileでプロファイルしたい場合、アプリケーションの中でcProfileを呼び出す方法と、モジュールとして実行する方法の2種類があります。アプリケーションの中で呼び出す際は、以下のようにcProfileで測りたい関数をwrapして実行することで計測することができます。
import cProfile
response = cProfile.run("main(query=query)")
モジュールとして実行したい場合はコマンドにモジュールを指定します。
uv run python -m cProfile -o output.pstats src/script.pyこれにより、スクリプトがプロファイルされ、output.pstatsに出力されます。これをgprof2dotを使用して可視化し、pngとして保存することでより詳細な情報を見ることができます。
gprof2dot -f pstats output.pstats | dot -Tpng -o output.png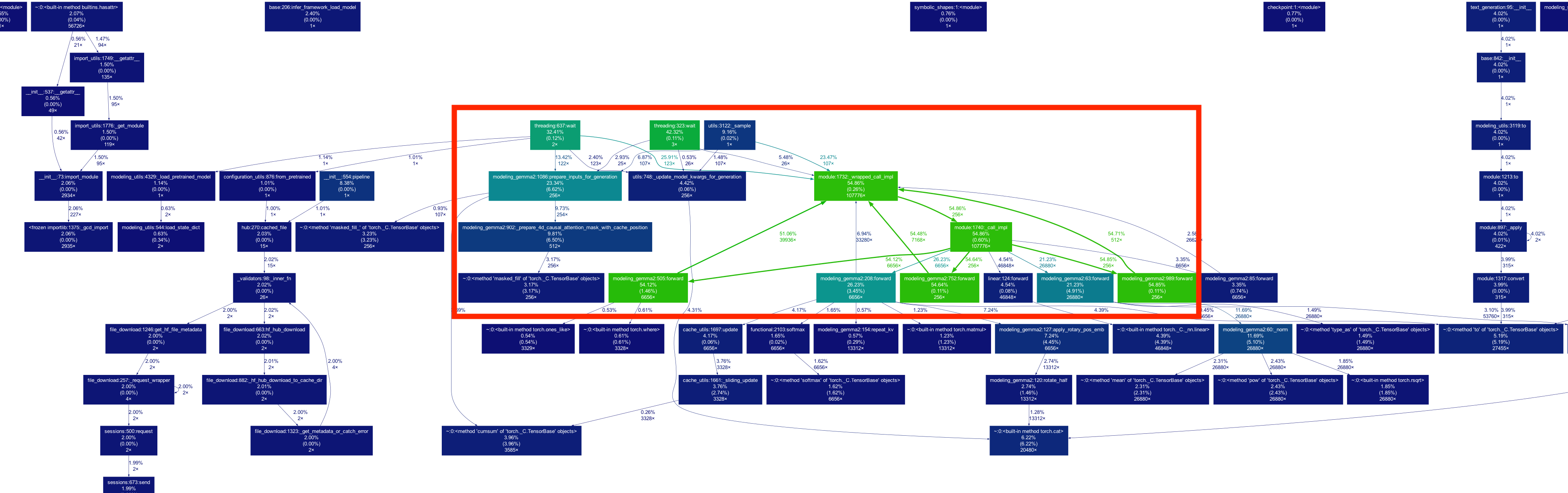
この図は関数呼び出しごとにどこに何%かかっているかがノードとエッジからわかるようになっています。青系は比較的軽い処理になっており、緑や赤になるにつれて時間がかかっている処理になります。
今回の例だとforwardを含めたmodule::1732::_wrapped_call_implとそれに紐づく一連の関数呼び出し(module::740::_call_impl、modeling_gemm::752::forward、linear::forward、modeling_gemm::208::forward)が全体の計54.86%の時間を消費しています。その中でスレッドの待機時間も約42.1%を占めているため、スレッドの非同期化などの最適化が検討できそうです。
FastAPIでの使用方法
FastAPIで使いたい場合はrouterの中でcProfile.runを呼び出したり、モジュールとして呼び出してもいいですが、ミドルウェアを自作することも可能です。
公式ドキュメントによると、FastAPIのミドルウェアには以下の特徴があります。
- ミドルウェアはアプリケーションに届いたそれぞれのリクエストを受け取る
- リクエストに対して必要なコードを実行可能
- 実行後、アプリケーションの残りの部分にリクエストを渡して処理させる
- ミドルウェアはアプリケーションによって生成されたレスポンスを受け取る
- レスポンスに対して必要なコードを実行可能
- レスポンスを返却
つまり、以下のような順序で処理が行われます。
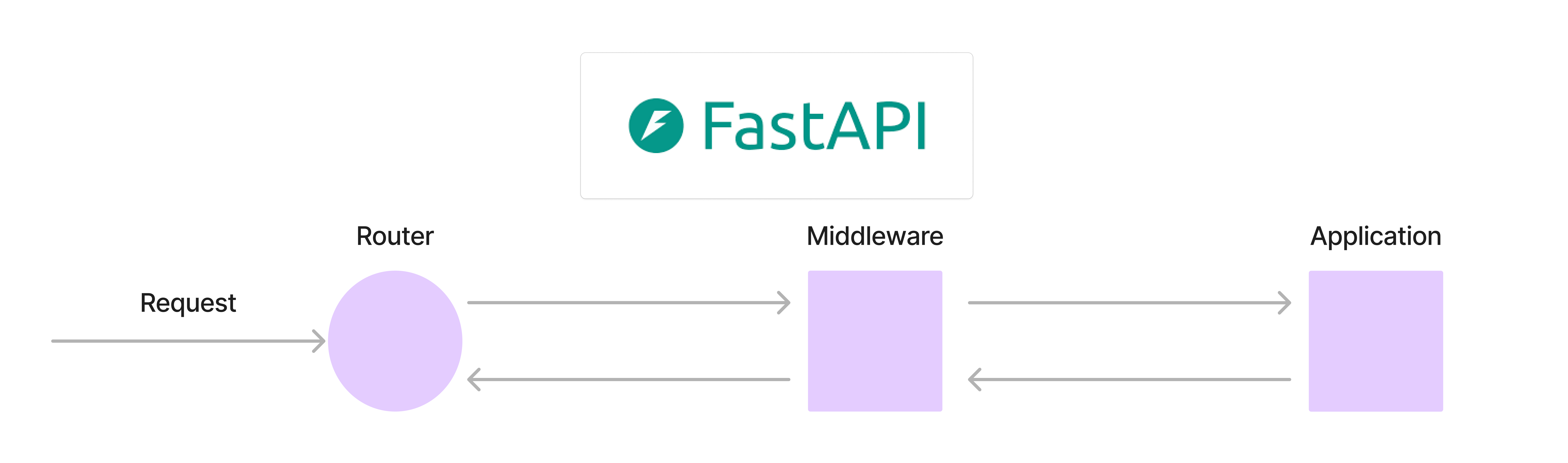
このミドルウェアを自作してみます。/generate/に来たリクエストにのみrequest_idを生成して、プロファイラを実行した後にf"profile_{request_id}.pstats" という名前で保存します。これによってリクエストごとに詳細なプロファイリングが可能になります。
@app.middleware("http")
async def cprofile_middleware(request: Request, call_next):
profile_target_paths = ["/generate/"]
if request.url.path in profile_target_paths:
request_id = uuid.uuid4()
profile_filename = f"profile_{request_id}.pstats"
profiler = cProfile.Profile()
profiler.enable()
response = await call_next(request)
profiler.disable()
profiler.dump_stats(profile_filename)
return response
else:
response = await call_next(request)
return responseあとは通常のPythonスクリプトと同様にgprof2dotで描画します。実際に描画した結果は以下のようになります。

py-spy
py-spy は、2019年7月に公開されたRustで書かれた統計的プロファイラです。2024年12月現在、v0.4.0がリリースされており、Python 3.13にも対応しています。
GitHub: https://github.com/benfred/py-spy
まず、ライブラリをインストールします。
$ uv add py-spy一般的な使用方法
$ uv run py-spy top --pid <PID>py-spy経由で実行し、プロファイル結果をSVG形式で保存することもできます。$ uv run py-spy record -o profile.svg -- python src/script.pyprofile.svgをブラウザで開くと、フレームグラフとして視覚化されたプロファイル情報が確認できます。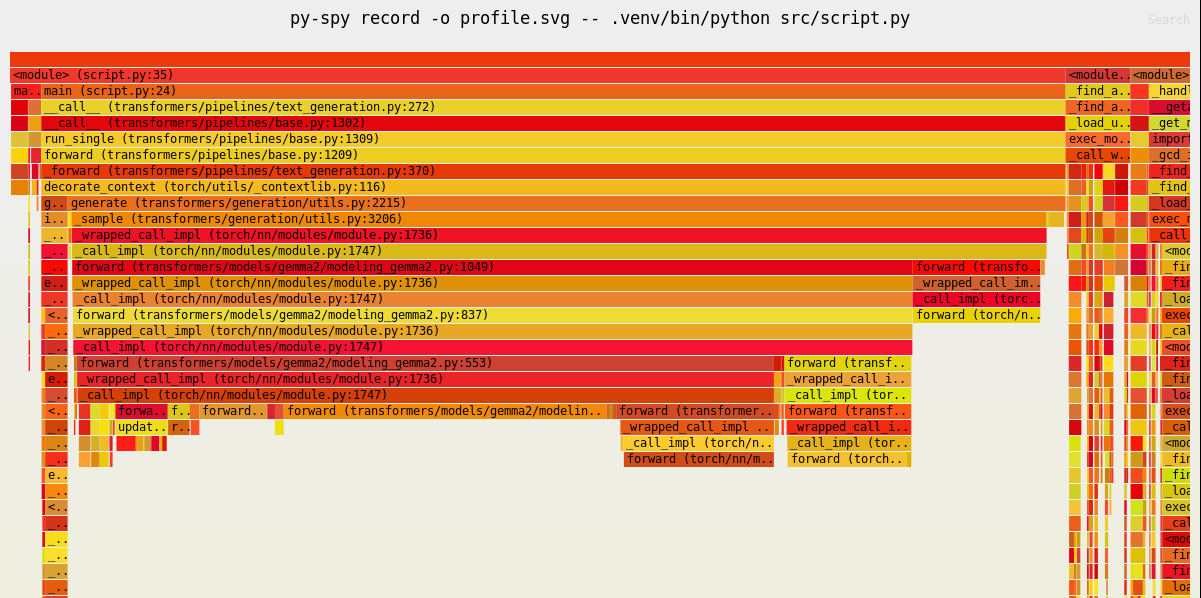
FastAPIでの使用方法
py-spyではそのままFastAPIを立ち上げ、別のプロセスから以下のようにプロファイルすることができます。
ps aux | grep uvicornpy-spy record -o fastapi_profile.svg --pid <PID>ただし、毎回uvicornのプロセスを指定するのは大変です。その場合、通常のスクリプトと同じようにuvicornもpythonモジュールとpy-spy経由で実行することができます。生成されるファイルも通常のスクリプトと同じになります。
py-spy record -o profile.svg -- python -m uvicorn src.main:app --host 0.0.0.0 --port 8000Yappi
![]()
Yappiは2022年8月に公開されたマルチスレッド、asyncio、geventに対応した決定論的プロファイラです。近年のPythonに搭載されている非同期プログラミングの機能を網羅的に扱っているプロファイラです。
GitHub: https://github.com/sumerc/yappi
READMEではYappiの特徴を以下のように記述しています。
- 高速: 完全に C で書かれており、高速
- ユニーク: マルチスレッド、asyncio、geventプロファイリングをサポート
- 直感的: プロファイラはいつでも、どのスレッドからでも開始/停止でき、結果を取得可能
- 標準準拠: 結果はcallgrind または pstat 形式で保存可能
- 豊富な機能セット: 実際のCPU 時間が表示され、さまざまなセッションから集計・並べ替え可能
- 堅牢性: プロジェクトが成熟
まず、ライブラリをインストールします。
$ uv add yappi
Scalene
![]()
Scaleneは2021年3月に公開されたCPU、GPU、メモリ全てを含んだオールインワンのプロファイラです。さらにAIを標準で組み込んでおり、AI を活用した最適化の提案を組み込んでいるのも特徴的です。行もしくは関数ごとにプロファイルを行います。
GitHub: https://github.com/plasma-umass/scalene
まず、ライブラリをインストールします。
$ uv add scalene一般的な使用方法
scaleneコマンドで実行します。uv run scalene src/scalene_script.py

FastAPIでの使用方法
.venv/bin/python -m scalene --html --outfile scalene.html -m uvicorn src.main:app --host 0.0.0.0 --port 8000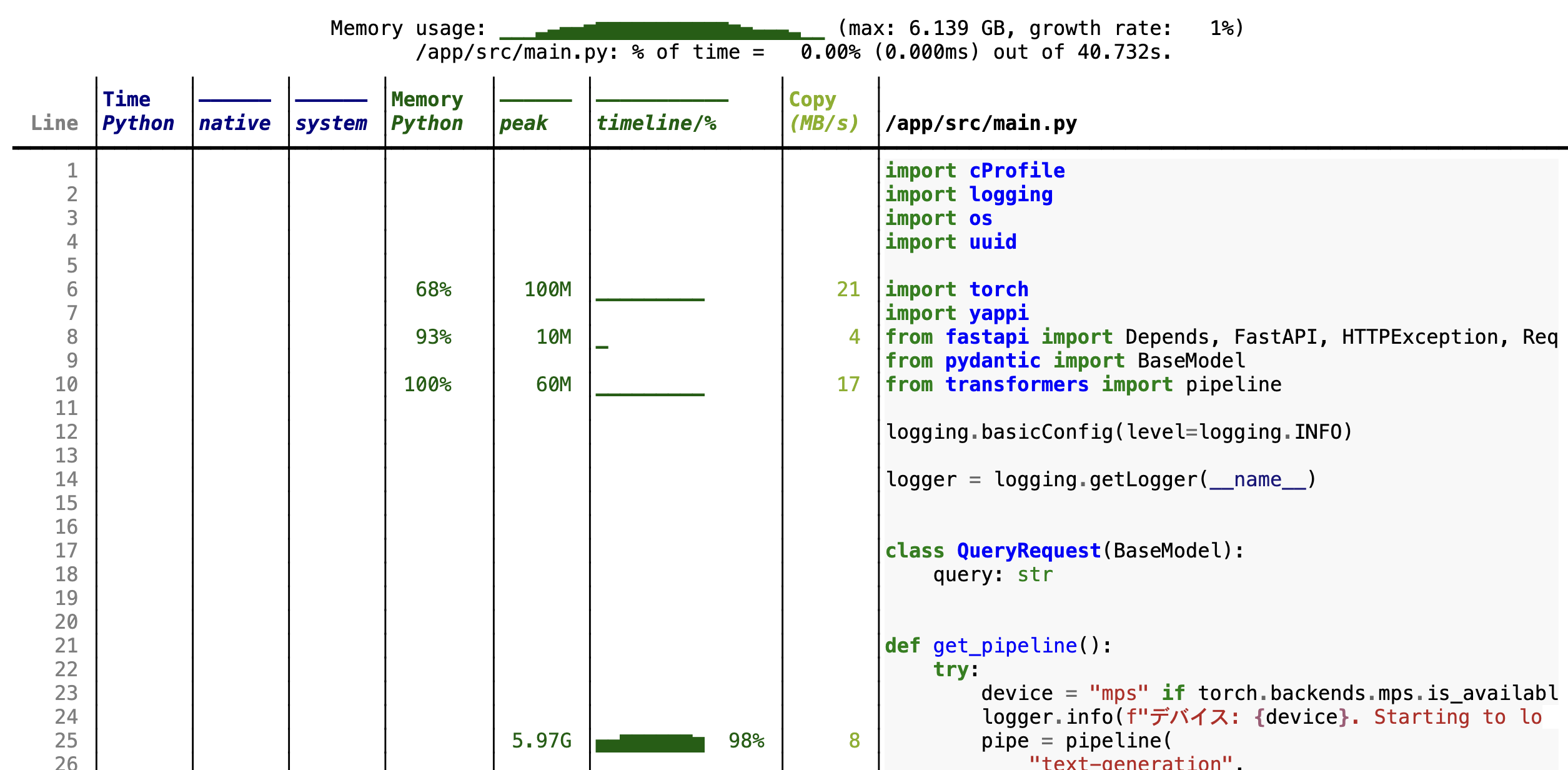
Memray
![]()
Memrayは2022年4月にBloombergが公開したPythonのメモリプロファイラです。
公式ドキュメント:https://bloomberg.github.io/memray/
GitHub: https://github.com/bloomberg/memray
公式ドキュメントではMemrayの特徴を以下のように記述しています。
- 高速に動作
- 収集されたメモリ使用量データに関するフレームグラフなどのさまざまなレポートを生成可能
- ネイティブ スレッドで動作
まず、ライブラリをインストールします。
$ uv add memray一般的な使用方法
memray runコマンドで実行し、メモリプロファイルを取得します。uv run memray run --output memray.bin src/memray_script.pyuv run memray flamegraph memray.binmemray-flamegraph.htmlをブラウザで開くと、メモリ割り当てのフレームグラフが確認できます。他にもsummaryやlive、statsなど複数コマンドがあり、CLI上でリアルタイムに結果が確認できるので自身の使いやすいものを選びながらメモリ使用量の多い箇所を特定していくプロセスが良いと思います。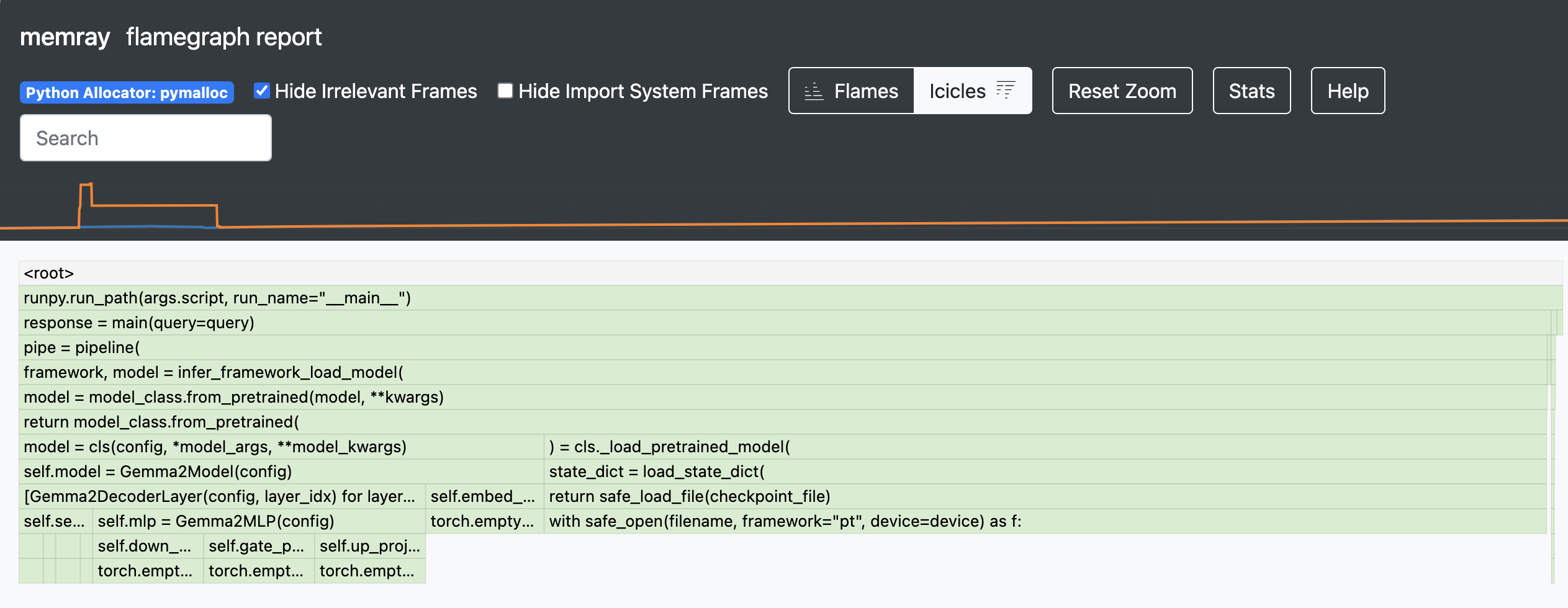
FastAPIでの使用方法
memray.Trackerを使用するか、Memray経由でuvicornを起動します。memray.Trackerを使いたい場合、メモリをプロファイルしたい処理をwithブロックで囲みます。from memray import Tracker
@app.post("/generate/")
async def generate(query: QueryRequest, pipe=Depends(get_pipeline)):
try:
with Tracker("memray.bin")
outputs = pipe(
query.query,
return_full_text=False,
max_new_tokens=256,
)
assistant_response = outputs[0]["generated_text"].strip()
return {"assistant_response": assistant_response}
except Exception as e:
raise HTTPException(status_code=500, detail=f"応答の生成に失敗しました: {e}")withブロック内のメモリ割り当てが追跡され、memray.binとして保存されます。その後は先ほどと同様にコマンドラインでフレームグラフを生成します。ただ、基本的にこちらも以下のようにモジュール経由で呼び出す方がコードの変更も少なくお手軽かと思います。.venv/bin/python -m memray run --live -m uvicorn src.main:app --host 0.0.0.0 --port 8000.venv/bin/python -m memray run --live -m uvicorn src.main:app --host 0.0.0.0 --port 8000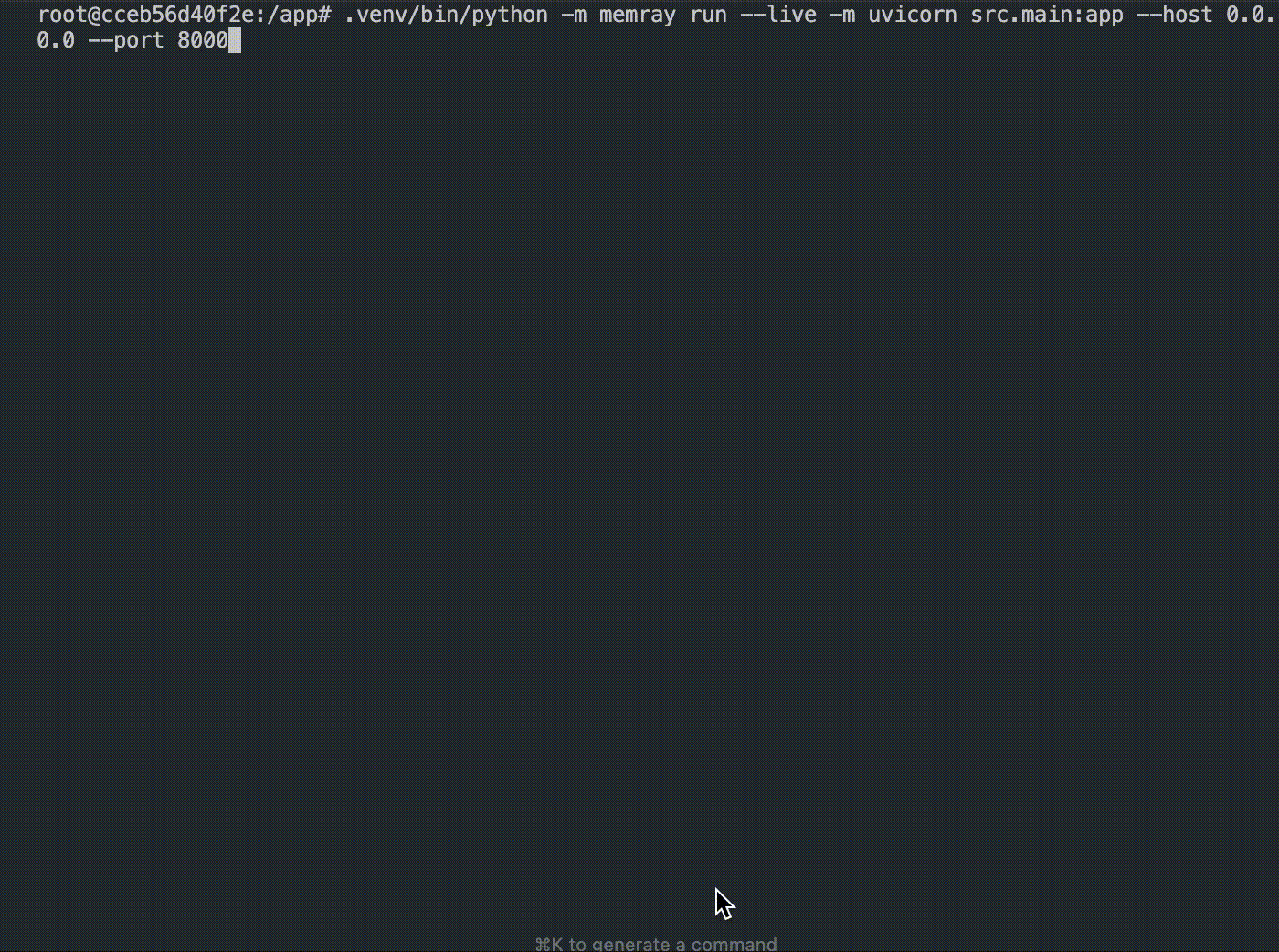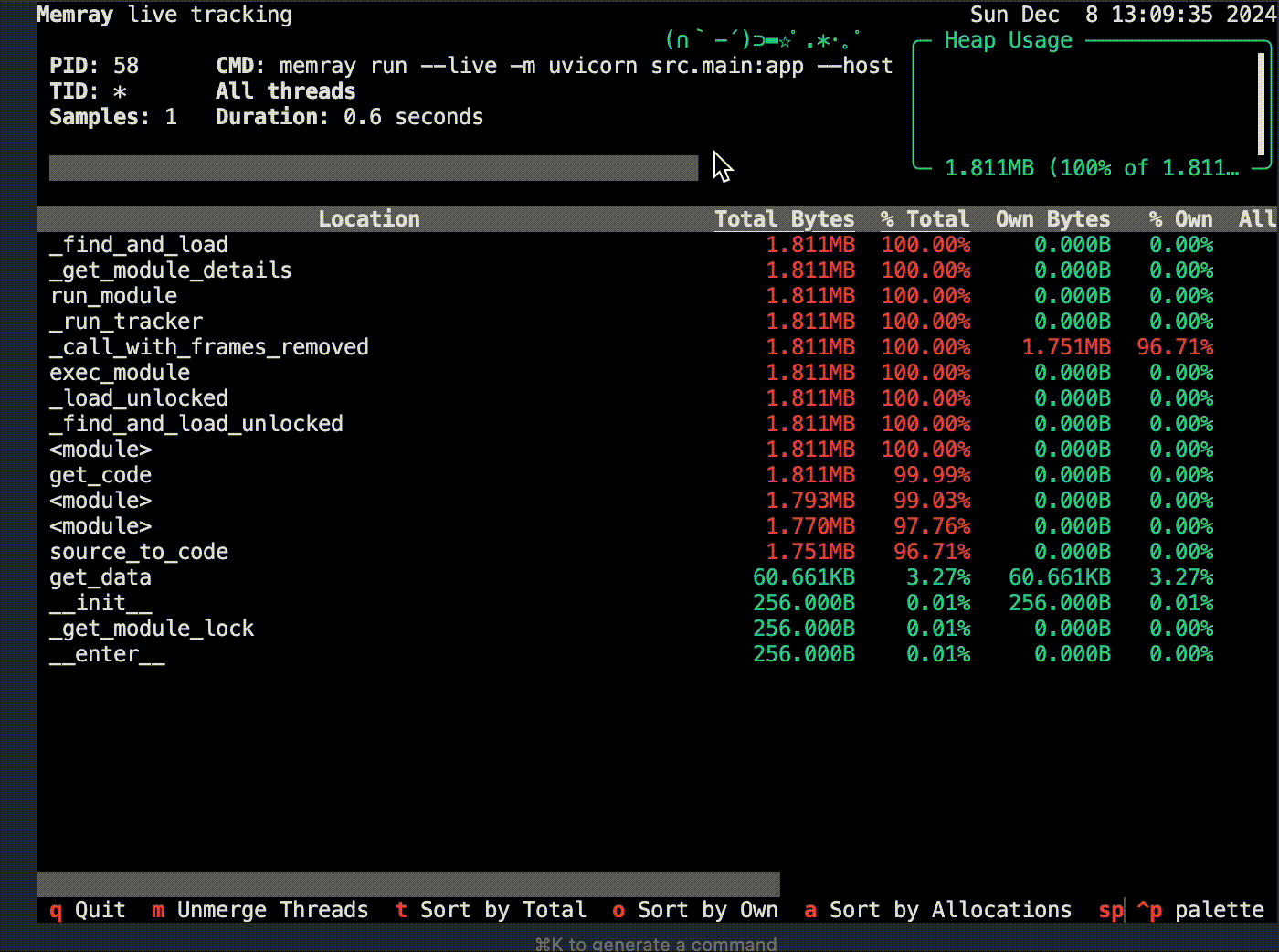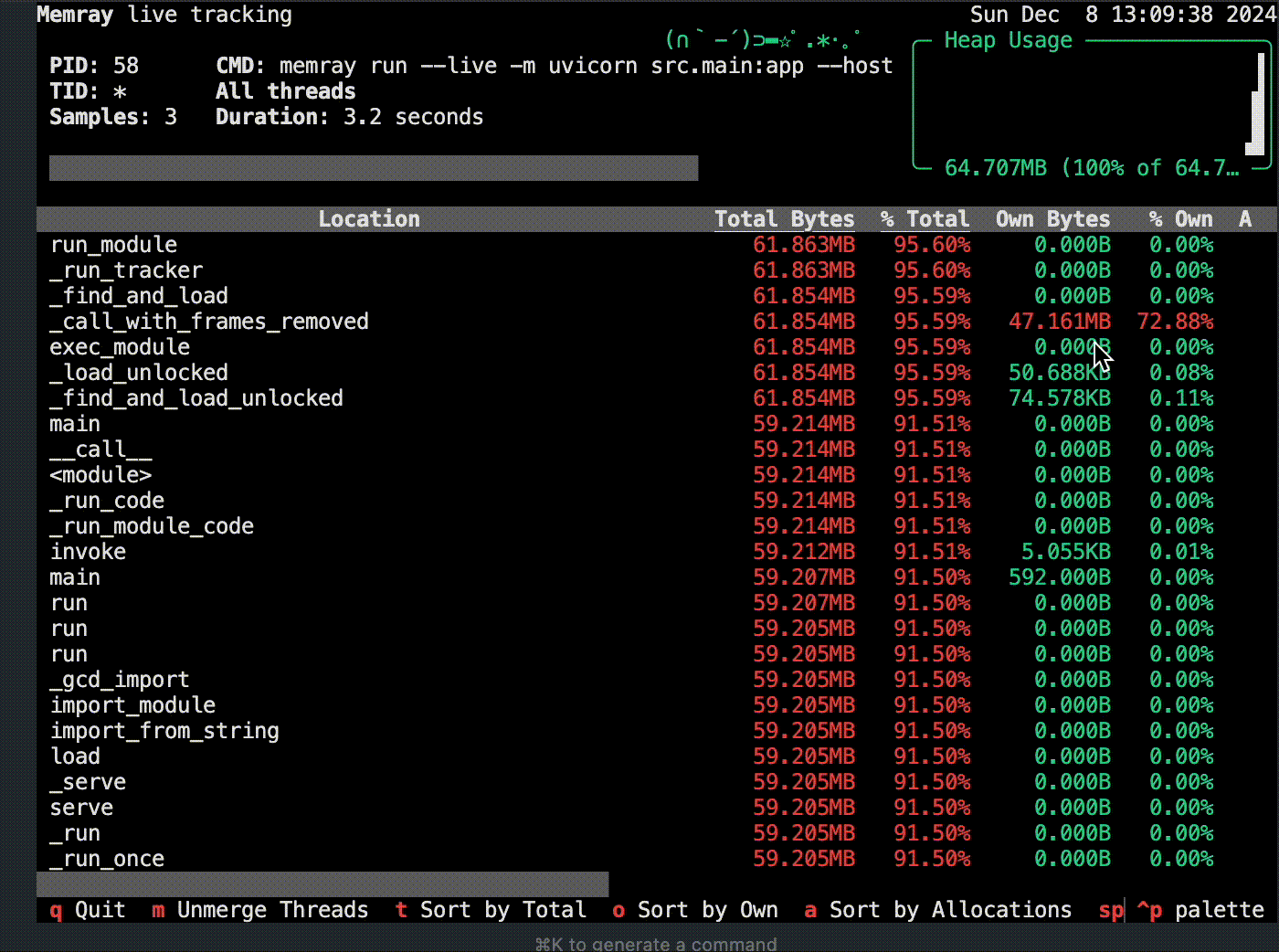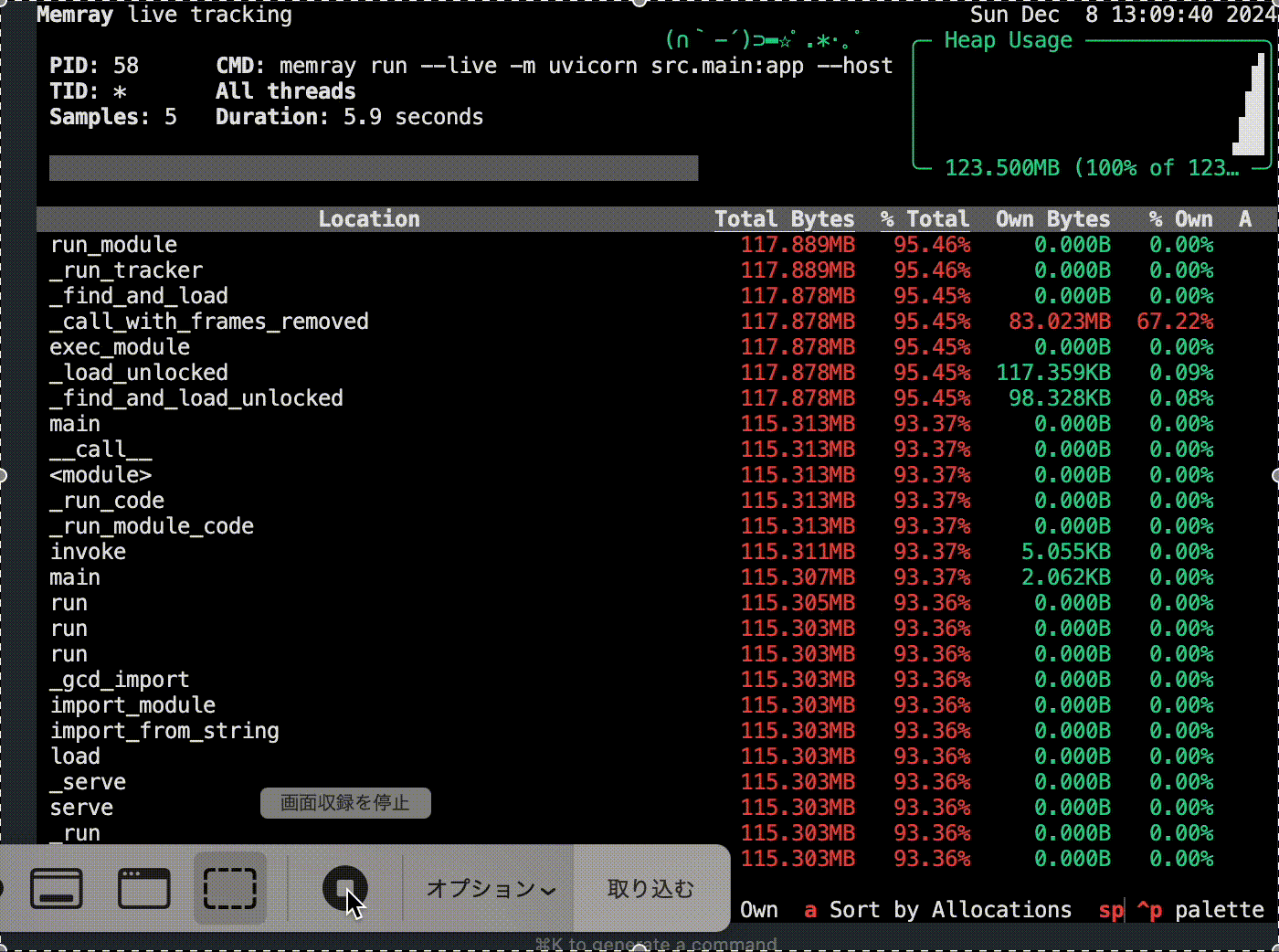
memory-profiler
GitHub:https://github.com/pythonprofilers/memory_profiler
まず、ライブラリをインストールします。
$ uv add memory-profiler一般的な使用方法
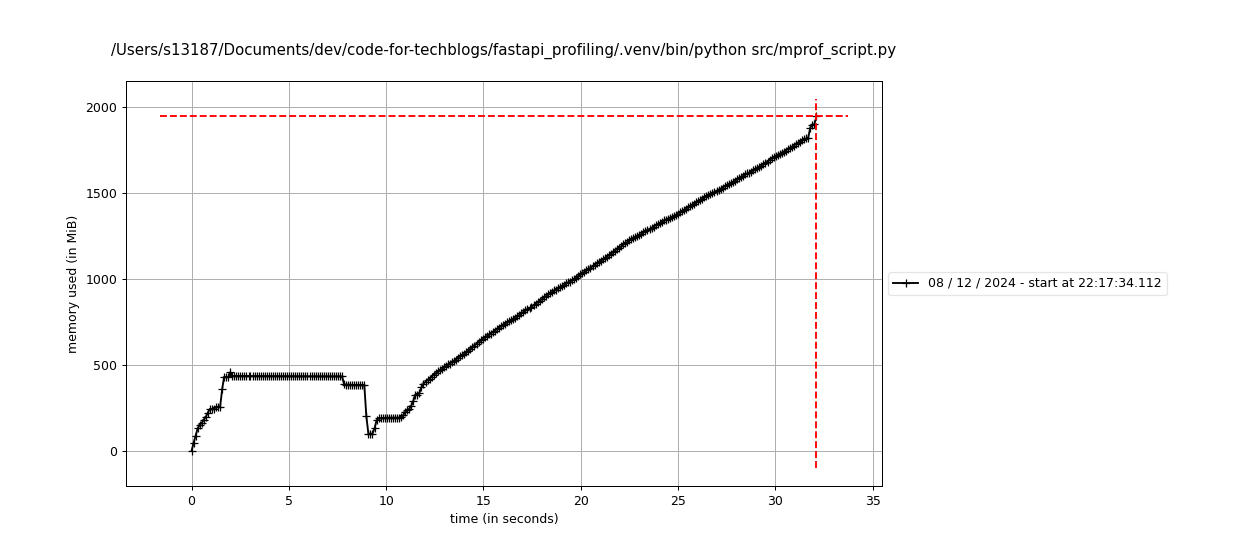
$ uv run mprof run src/mprof_script.py$ uv run mprof plotそうすると時間ごとのメモリ使用量が描画されるのでメモリがどのように使用されているかが確認できます。
FastAPIでの使用方法
@profileデコレータを使用します。以下のようにmemory_profilerからprofileをimportし、FastAPIのrouterと同じようにデコレータとしてつけます。先ほどと同様にdataファイルが吐き出されるので適切に描画することで、メモリの使われ方が確認できます。from memory_profiler import profile
@profile
@app.post("/generate/")
def generate(query: QueryRequest, pipe=Depends(get_pipeline)):
try:
outputs = pipe(
query.query,
return_full_text=False,
max_new_tokens=256,
)
assistant_response = outputs[0]["generated_text"].strip()
return {"assistant_response": assistant_response}
except Exception as e:
raise HTTPException(status_code=500, detail=f"応答の生成に失敗しました: {e}")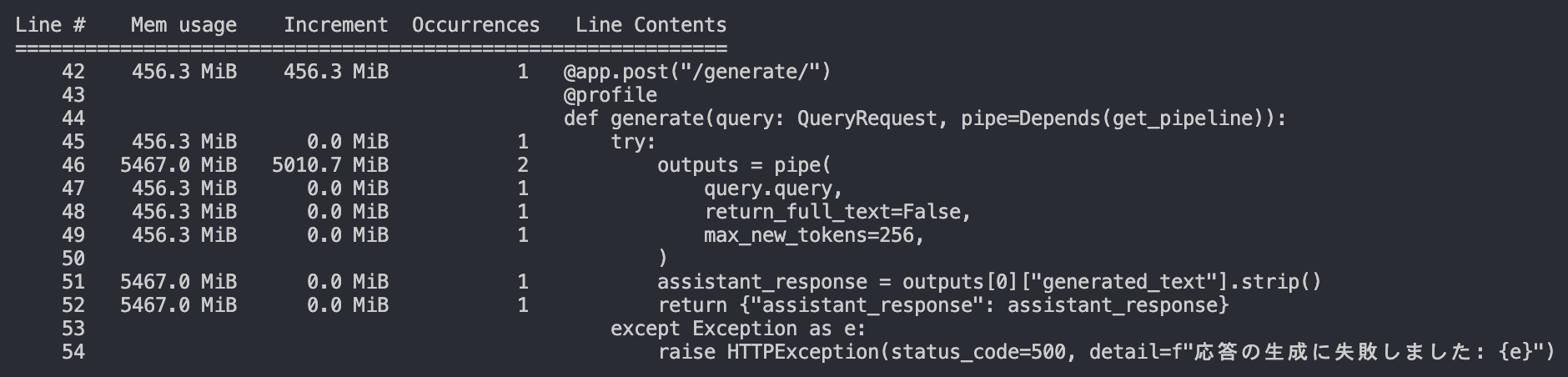
memory-profilerはオーバーヘッドが大きいので、開発環境での使用を推奨します。また、モジュール経由でも呼び出すことができるので、そちらの使い方もおすすめです。おわりに
今回はPython(特にFastAPI)でプロファイリングする方法を紹介しました。他にもfastapi_profilerというツールも存在しますが、これらのツールを使うことでサーバのボトルネックを特定し、効率的なパフォーマンスチューニングが可能になります。パフォーマンスチューニングしたい場合は、まずプロファイラを入れて計測してみることをお勧めします。個人的には、非同期処理などを使っておらず、ざっくり処理のボトルネックを追いたい場合はcProfile、メモリリークなどメモリをプロファイリングしたい場合はMemrayを使うのがいいのかなと思います。また、Scaleneもコミュニティが活発なので、今後のアップデートをウォッチしたいです。
明日のAdvent Calendar 11日目の記事は、同じチームの大竹による VAD・VAPを用いた発話終了検知 の記事の予定です。こちらもよろしくお願いいたします。




