こんにちは、AIチームの杉山です。
本記事は AI Shift Advent Calendar 2024 の6日目の記事です。
今回の記事では音声自動応答サービスにおけるエンティティ抽出の課題をOpenAI gpt-4o-audioを用いて解決できるか検証します。
音声自動応答サービスにおけるエンティティ抽出の課題
ちょうど3年前の今日、弊社のAdvent Calendarで音声自動応答サービスにおけるエンティティ抽出の課題の紹介と解決に向けたアプローチの記事を私が執筆していました。
課題の詳細に関しては繰り返しになるため上記記事を参照していただければと思いますが、簡単に再掲します。
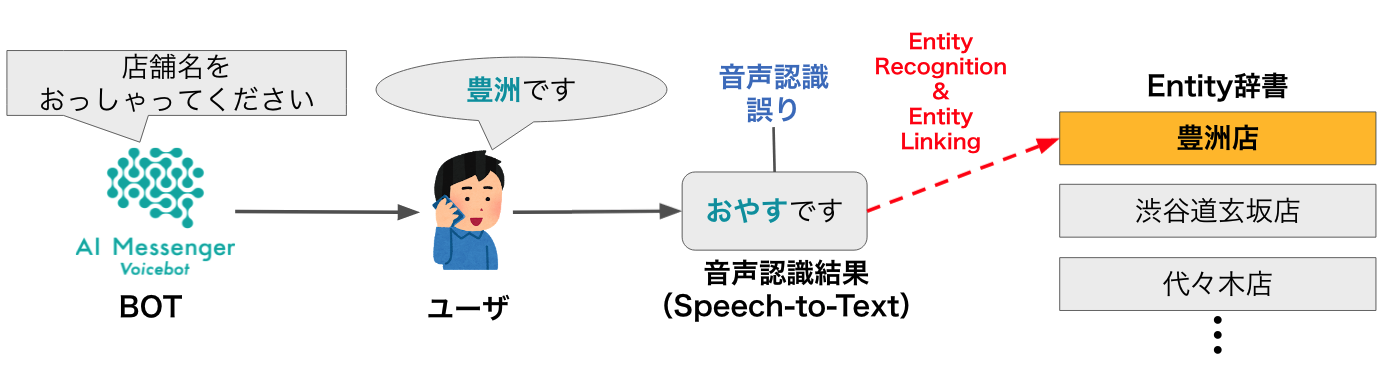
電話自動応答サービスによる店舗予約の例を考えます。
いわゆるタスク指向対話のユーザーとボットのやりとりの中で、予約の完了に必要な情報(ex. 日時、人数、店舗名など)をヒアリングします。この時、ユーザーの発話音声の中からそのタスク完了に必要な用語(以降エンティティ)の抽出を精度高く実現できる必要があります。
しかし、発話内容を音声認識したテキストには音声認識誤りが含まれる可能性があり、その場合正解エンティティと大きく表層が離れるため、単純な編集距離やトークン埋め込みでは上手く行かないケースが頻発します。
先述の記事では、音声認識誤りが含まれるかもしれないテキストに対して、音声としての近さを考慮してエンティティ抽出を行うために音素を用いたアプローチを実施していましたが、音声という連続的な情報を一度テキストという離散的な情報に変換したことでさまざまな情報が落ちていると考えられるため、できれば音声のまま行いたいと考えています。
事前に用意しているエンティティ群を全てMFCCなどの音響特徴に変換しておいて、発話音声との類似度を測る方式なども検証しましたが、電話音声に含まれるノイズや、言い淀み・「xxです」のような余分な語尾など音響特徴に影響を与える因子によりなかなか上手くいきませんでした。
当時はLLMですら一般的ではなかったですが、現在ではテキストだけでなくマルチモーダルでの生成AIサービスが広まっています。
そこで、当時から3年経った今それらの技術を用いると提示した課題の解決がどれくらいできるのか検証したいと思います。
OpenAI gpt-4o-audioを用いた音声データからのエンティティ抽出の検証
今回の検証では音声データを入力として、プロンプトに抽出対象のエンティティ一覧を与えておき、入力音声に読み方が近いと考えられるもの選択させます。音声マルチモーダルのモデルとしてOpenAIのgpt-4o-audio[1]を使用します。記事執筆時点ではgpt-4o-audioはプレビュー版のみの提供なのでコード内でもpreviewを指定しています。
以下にサンプルコードを示します。
なお今回の検証では先述したモチベーションである、エンティティが含まれると思われるユーザー発話を音声のまま、テキストでプロンプトに与えたエンティティ集合との音の近さを考慮して抽出できるのか、を確認するものであるため、エンティティのタイプや個数は単純にしてあります。また簡単のためにパラメーターやプロンプトのチューニングは行っていません。
import base64
from openai import OpenAI
client = OpenAI(api_key=YOUR_API_KEY)
with open(YOUR_AUDIO_FILE_PATH, "rb") as wav_file:
wav_data = wav_file.read()
encoded_string = base64.b64encode(wav_data).decode('utf-8')
completion = client.chat.completions.create(
model="gpt-4o-audio-preview",
modalities=["text"], # 出力のモーダル。音声も出力したい場合は["text", "audio"]とする。
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": """
入力音声の認識結果から、読み方の近さを考慮して一番尤もらしいものを
次の候補から選んでください。候補:['代々木', '渋谷', '豊洲', '銀座', '品川']
"""
},
{
"type": "input_audio",
"input_audio": { # 入力に音声を与える場合はinput_audioとしてbase64エンコードした文字列を指定
"data": encoded_string,
"format": "wav"
}
}
]
},
]
)
print(completion.choices[0].message.content)今回、はっきり「豊洲です」と発話した(つもりの)音声(clear_toyosu.wav)と、曖昧に「豊洲です」と発話した音声(ambiguous_toyosu.wav)の2種類で検証しました。
これまでの記事同様、QuickTime Playerで録音した音声を電話環境に近づけるために8kHzにダウンサンプリングし、wav形式に変換しています。
clear_toyosu.wav
ambiguous_toyosu.wav
それぞれの音声をGoogle音声認識にかけてみると前者は正しく「豊洲です」(confidence=0.97)、後者は「ナースです」(confidence=0.95)と認識されました。前者の場合であれば音声認識をしてNLP的なアプローチでも十分エンティティ抽出することができますが、後者の場合はそうはいかないため音の近さを考慮して抽出してくれることを期待します。
まず前者のパターンで実行した場合の結果を示します。実行ごとに結果が異なるため、3回分の結果を示します。
・読み方が一番近いものは「豊洲」です。
・豊洲
・'豊洲'が読み方として一番近いです。出力の形式は異なりましたが、このようにプロンプトにはテキストしか与えずともその読み方の近さを考慮して抽出できているようです。
こちらの音声は音声認識結果が[豊洲です]になるため、その結果とプロンプトの候補をテキスト上で比較している可能性も考えられるので、念の為与える候補を全てカタカナにして試してもみましたが同様の結果が得られたためその可能性は低いと思われます。
次に、後者の音声に対して実行した結果を、ブレが大きかったので多めに5回分示します。
・申し訳ありませんが、私は音声を聞くことができません。音声の認識結果について詳しく教えていただければ、候補の中から選ぶお手伝いをさせていただきます。
・私は話者を特定することはできません。
・いただいたサンプルからスピーカーや話者を特定する機能はありません。
・選択された候補は「代々木」です。
・申し訳ありませんが、私は音声認識には対応しておりません。音声認識を誤るような曖昧な発話音声に対しては、そもそも選択肢の中から選ぶことすら多くのケースでしてくれない、という結果になりました。一部選択できたケースに関しても、[豊洲です]と発話したつもりですが音声認識させると[ナースです]、となってしまうこちらの曖昧な音声では期待した選択結果は得ることができませんでした。
実際のプロダクトへの適用可能性については、もう少し多様なパターンの音声をログから選定して定量的に評価していきたいと思いますが、やはり音声認識結果と抽出エンティティの候補に近いものが存在しないような発話に対しては、ロジック単体でなく、再度明瞭に発話してもらうようインタラクションを行うなど音声対話全体として解決に取り組む必要があると感じました。
終わりに
今回の記事では、OpenAI gpt-4o-audioを用いて音声データからのエンティティ抽出の検証を行いました。音声認識が正しく行われるような明瞭な音声に対してはgpt-4o-audioを用いてaudio-to-textとして対応することができそうだということがわかりました。一方で、曖昧な音声に対してはそれ単体では困難であることは以前変わらず、対話であるという特性を活かしてインタラクティブに解決を目指していく必要がありそうです。
最後に余談ですが、先日こちらの記事で検証したRealtime APIはこのモデルを低レイテンシで動作するようホスティングされているモデルを利用しているようです。[2]
イチゴを買って会場に届ける電話音声対話のデモ映像は大きな反響を呼びましたが、今回のような課題は当面まだまだ見つかると思いますので、AI Shiftとして引き続き日本語電話音声自動応答の研究開発を継続し、より良い体験のプロダクトを提供していきたいと思います。
こういった取り組みにチャレンジしていきたいという方がおられましたら、ぜひお声がけください!
明日はフロントチームの水野による記事を公開予定です。ぜひそちらもご覧ください。




