こんにちは、AI Shift AIチームの大竹です。
本記事は AI Shift Advent Calendar 2024 の11日目の記事です。
今回の記事では弊社のAI Messenger Voicebotをはじめとした音声対話システムにおける主要な課題である発話終了検知について扱います。
発話終了検知とは
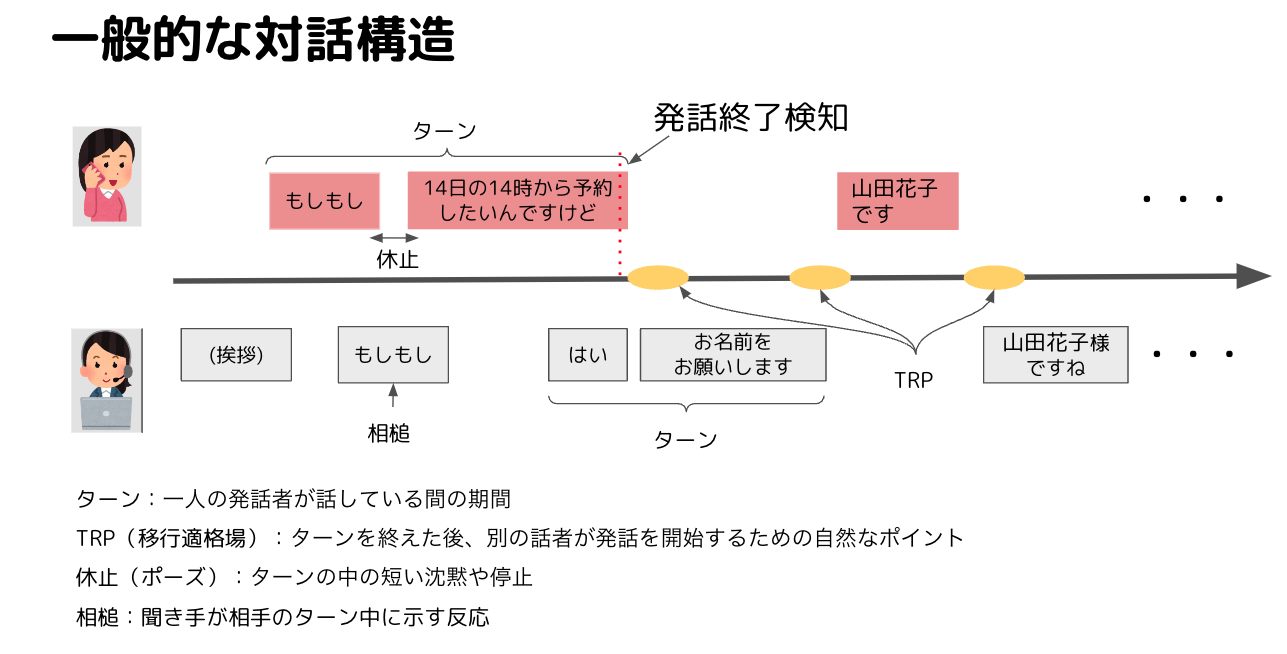
発話終了検知は、音声対話システムにおいて2つの重要な役割を担っています。
まず、スムーズなターンテイキングの実現に不可欠です。対話というのは話者がターンを取り合いながら進行していきます。1ターンの中に休止があったり、聞き手の相槌が含まれていたりします。ターンを取ることをターンテイキングと言って、このターンテイキングを実行するために相手の発話が終了したことを検知する発話終了検知というロジックが重要になります。
また、適切なタイミングでの発話終了検知はユーザの意図を正確に理解するために重要です。高速なターンテイキングの実現に特化しようとして、早めに発話終了検知をしてしまうと発話が途切れてしまい、意図理解に失敗してしまいます。
このように発話終了検知はシステムがユーザとの対話を円滑に進めるために重要なタスクですが、話し手の発話が終了したかどうかをどのように判定しているかを言語化することは難しく、人間でも何となく話し終わっただろうという推論をもとにターンテイキングを行っている気がします。このように単純なルールでは書くことが難しい部分は機械学習的なアプローチを採用していい感じにできたら嬉しいです。
VADとVAP
発話終了検知の処理を実装するために重要になるのがVAP(Voice Activity Projection)、VAD(Voice Acitivity Detection)というタスクです。
VADは、与えられた音声データに対して、発話している区間を特定するタスクであり、内部では音声信号が有声音か無声音かを判定しています。
一方、VAPは、発話のターンテイキング、つまり話者交替のタイミングを予測するタスクで、対話における発話の切れ目や次に話し始めるタイミングを推測することに焦点を当てています。
本記事では、VADモデルやVAPモデルを用いてスムーズで頑健な発話終了検知がどの程度実現可能かを検証します。VAPモデルは商用利用可能のライセンスで公開されているモデルが存在しないので、モデルの作成も検証の範囲内とします。VADモデルは公開モデルで商用利用可能なものがあるので、モデルの作成は検証のスコープ外とします。
したがって、本記事で扱う内容は以下のものとします。
- VAPモデルの作成
- VAPを用いた発話終了検知
- VADを用いた発話終了検知
VAPモデルの作成
使用したコード
VAP-Realtime リポジトリに含まれるコードをそのまま使用しました。
使用したデータ
日本語日常会話コーパス(CEJC)
CEJCは、日常生活における自然な会話を収録した200時間規模のコーパスです。40名の協力者による「個人密着法」と、不足分を補う「特定場面法」で収集されています。映像・音声データから形態論情報まで、多様なデータを含む日本語会話のデータベースです。
訓練データの準備
CEJCのディレクトリ構造は以下のようになっています。dataディレクトリ内に各セッションの音声データとそのアノテーションが含まれています。
CEJC/
├── 00readme.html
├── data
├── metaInfo
├── rdb
└── tool
CEJC/data/C001/C001_001
├── C001_001-luu.TextGrid
├── C001_001-luu.csv
├── C001_001-luu.eaf
├── C001_001-morphLUW.csv
├── C001_001-morphSUW.csv
├── C001_001-transUnit.TextGrid
├── C001_001-transUnit.csv
├── C001_001-transUnit.eaf
├── C001_001_IC01.wav
├── C001_001_IC02.wav
├── C001_001_IC03.wav
├── C001_001_IC04.wav
├── C001_001_IC05.wav
└── C001_001_IC0A.wav*-luu.csvには長発話単位(Long Utterance Unit)に関する以下のようなアノテーションが含まれています。
| luuID | startTime | endTime | speakerID | text |
| 1 | 11.563 | 12.444 | IC01_杉田 | (R けん)ちゃん寝るんだ。@店に出入りの人が店先のベンチで昼寝 |
| 2 | 12.668 | 12.817 | IC02_中沢 | あ。 |
| 3 | 12.937 | 13.866 | IC01_杉田 | (L) |
| 4 | 12.96 | 13.275 | IC02_中沢 | 寝る。 |
startTimeとendTimeは発話に対する音声区間のアノテーションです。
このアノテーション情報をVAPの訓練に用いるために、以下のような形式のCSVファイルに変換します。
| audio_path | start | end | vad_list | session | dataset |
|---|---|---|---|---|---|
| CEJC/data/K002/K002_003/K002_003b_IC0A.wav | 0 | 20.0 | [[[11.563, 12.444], [12.937, 13.866], [17.948, 18.595]], [[13.71, 14.782], [19.773, 20.273], [20.75, 22.44]]] | K002_003a-luu | CEJC |
| CEJC/data/K002/K002_003/K002_003b_IC0A.wav | 20 | 40.0 | [[[0.75, 2.44], [4.437, 5.087], [11.687, 12.319], [12.645, 13.775], [18.575, 24.443]], [[6.892, 7.883], [10.078, 11.033], [12.904, 13.423]]] | K002_003a-luu | CEJC |
| CEJC/data/K002/K002_003/K002_003b_IC0A.wav | 40 | 60.0 | [[[11.722, 12.475], [15.938, 23.122]], [[6.315, 8.495], [8.916, 13.78], [14.314, 15.324], [15.949, 16.579]]] | K002_003a-luu | CEJC |
会話音声ファイルから20秒間のセグメントごとに有声区間を抽出し、vad_listにまとめます。vad_listは有声区間のリストのリストで、各話者ごとに有声区間がまとめられています。
上記のCSVファイルを訓練用、検証用、テスト用に8:1:1の割合で分割し、それぞれtrain.csv、valid.csv、test.csvとして保存します。
モデルの訓練
以下のスクリプトを用いて訓練を実行しました。他のハイパーパラメータはデフォルトのものを使用しています。訓練は、Vertex AIのT4 GPUを4枚搭載したインスタンスで行いました。
python train.py \
--data_train_path train.csv \
--data_val_path valid.csv \
--data_test_path test.csv \
--vap_encoder_type cpc \
--vap_cpc_model_pt ../asset/cpc/60k_epoch4-d0f474de.pt \
--vap_freeze_encoder 1 \
--vap_channel_layers 1 \
--vap_cross_layers 3 \
--vap_context_limit -1 \
--vap_context_limit_cpc_sec -1 \
--vap_frame_hz 5 \
--event_frame_hz 5 \
--opt_early_stopping 0 \
--opt_save_top_k 5 \
--opt_max_epochs 25 \
--opt_saved_dir ./trained_model/ \
--data_batch_size 8 \
--devices "0,1,2,3" \
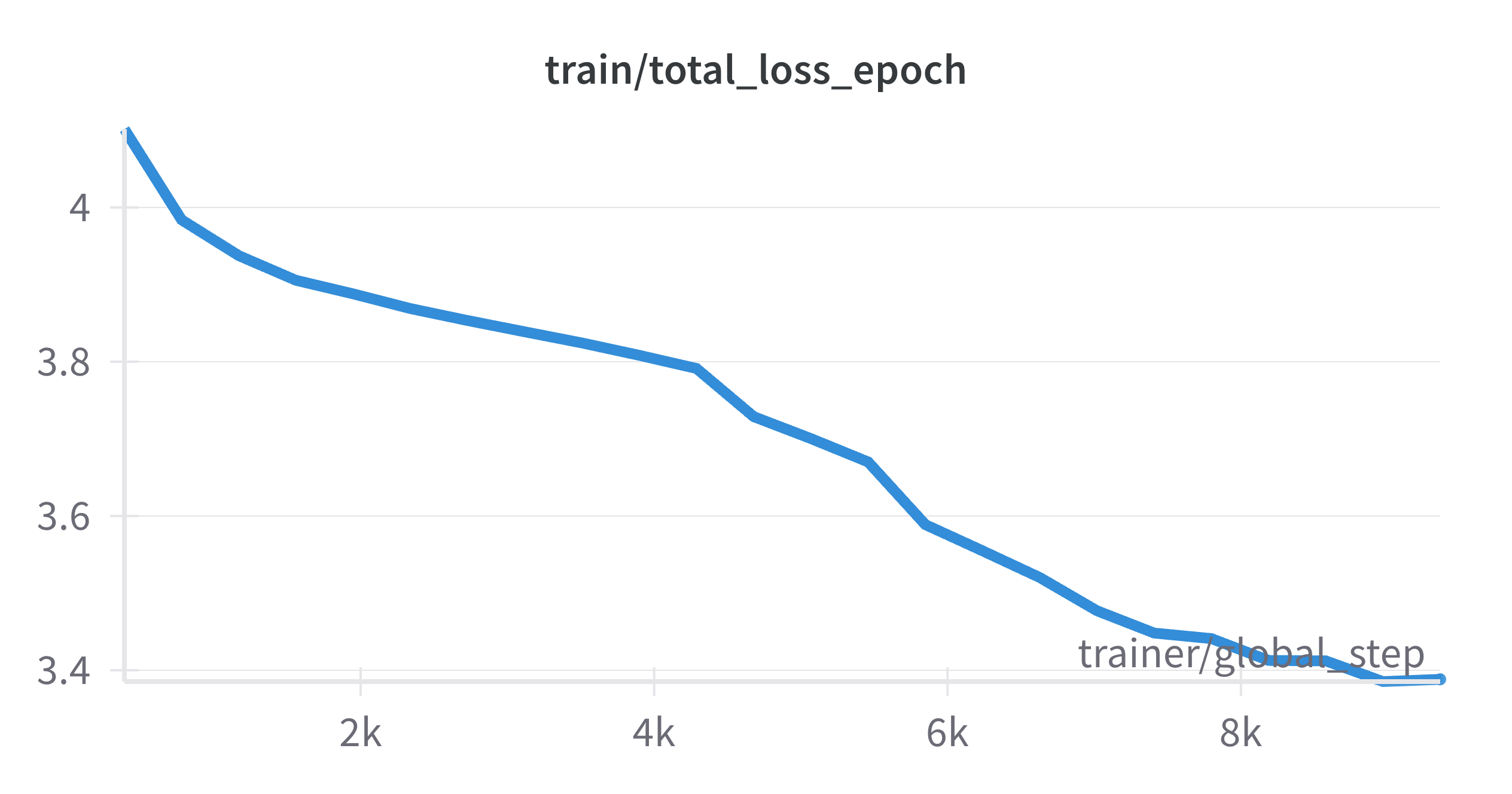
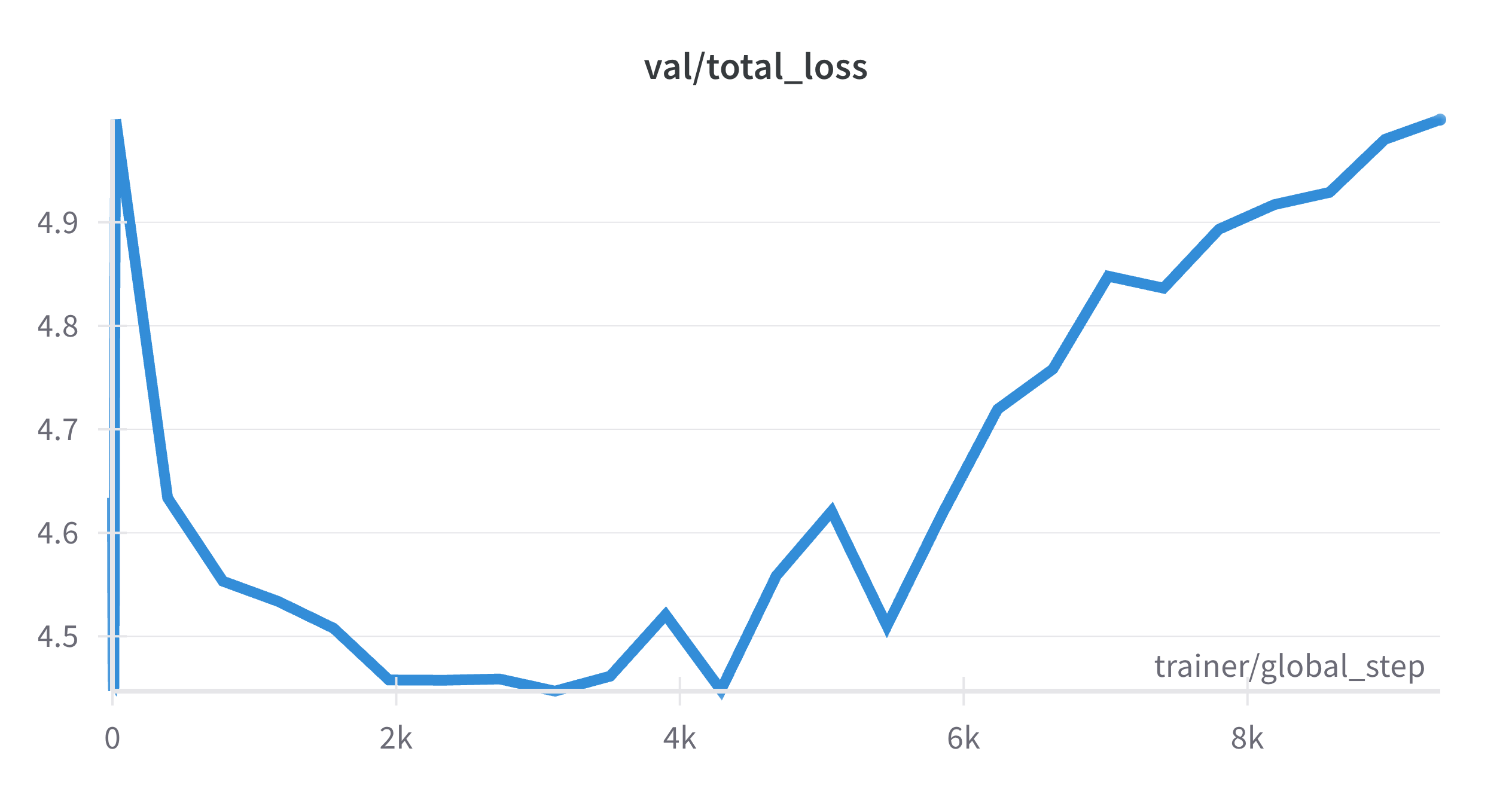
--seed 0訓練の結果、11エポック目以降でトレーニングデータに対する損失は減少していきましたが、検証データに対する損失が増加し始め、過学習の傾向が見られました。以下はTrainとValidationの損失関数の推移です。
発話終了検知の性能検証
VAPおよびVADを用いて、発話終了検知の性能を比較・検証しました。
評価時の推論はVAP、VADともにM2 macのCPUで行いました。
方法
検証データ
「えっと、来週の水曜日の午後5時に5人で予約できますか?」という発話内容で音響条件を変えて2種類の音声データを用意して使用しました。
audio_48kHz:スマートフォンで録音した48kHzの音声を16kHzにダウンサンプリング
audio_8kHz:電話音声として録音された8kHzの音声を16kHzにアップサンプリング
(注)2つの音声は完全に個別のものであるため、音声長が異なっています。
評価
以下の指標をプロットして3段組みのグラフを作成し、モデルの性能を視覚的に評価しました。
- 音声波形(Amplitude)
- 音声活動(Voice Activity)
- ターン判定(User/Bot Turn)
VAPを用いた発話終了検知
VAPはマルチチャネルの音声ストリームを入力として受け取り、それぞれの音響特徴量を抽出します。この特徴量を基に、現在話している話者が引き続き発話を続ける確率(p_now)と、近い将来の話者確率(p_future)を出力します。用いた推論コードは以下の通りです。推論コードを動かすにはVAPのリポジトリをクローンしておく必要があります。
from rvap.vap_main.vap_main import VAPRealTime
from pathlib import Path
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
import soundfile as sf
import numpy as np
def process_audio_file_with_plot(single_channel_audio_path, score_threshold=0.5):
device = 'cpu'
vap = VAPRealTime(vap_model, cpc_model, device, frame_rate, context_len_sec)
# 音声データの読み込み
audio_data, sample_rate = sf.read(single_channel_audio_path)
print(audio_data.shape, audio_data.ndim)
if audio_data.ndim == 2 and audio_data.shape[1] != 1:
import librosa
audio_data = librosa.to_mono(audio_data.T)
assert sample_rate == 16000, "The sample rate of the input audio file must be 16kHz."
x1 = audio_data
x2 = np.zeros_like(x1)
# 結果を格納するリスト
p_now_list = []
p_future_list = []
turn_now_list = [] # p_nowに基づくターン
turn_future_list = [] # p_futureに基づくターン
frame_indices = []
vap_processor = VAPRealTime(vap_model, cpc_model, device, frame_rate, context_len_sec)
current_x1 = np.zeros(vap_processor.frame_contxt_padding)
current_x2 = np.zeros(vap_processor.frame_contxt_padding)
FRAME_SIZE_INPUT = 160
# プロット用のfigureを作成
fig = plt.figure(figsize=(15, 10))
gs = GridSpec(3, 1, height_ratios=[1, 1, 0.5])
# 波形プロット用のサブプロット
ax1 = fig.add_subplot(gs[0])
ax1.grid(True) # グリッドを表示
# VAP結果プロット用のサブプロット
ax2 = fig.add_subplot(gs[1])
ax2.grid(True) # グリッドを表示
# ターン表示用のサブプロット
ax3 = fig.add_subplot(gs[2])
ax3.grid(True) # グリッドを表示
for i in range(0, len(x1), FRAME_SIZE_INPUT):
x1_frame = x1[i:i + FRAME_SIZE_INPUT]
x2_frame = x2[i:i + FRAME_SIZE_INPUT]
if len(x1_frame) < FRAME_SIZE_INPUT:
break
current_x1 = np.concatenate([current_x1, x1_frame])
current_x2 = np.concatenate([current_x2, x2_frame])
if len(current_x1) < vap_processor.audio_frame_size:
continue
vap_processor.process_vap(current_x1, current_x2)
# 結果を保存
frame_indices.append(i / sample_rate) # 時間(秒)に変換
p_now_list.append(vap_processor.result_p_now[0])
p_future_list.append(vap_processor.result_p_future[0])
# ターン情報を決定 (閾値を0.5とする)
turn_now = 1 if vap_processor.result_p_now[0] > score_threshold else 0
turn_future = 1 if vap_processor.result_p_future[0] > score_threshold else 0
turn_now_list.append(turn_now)
turn_future_list.append(turn_future)
current_x1 = current_x1[-vap_processor.frame_contxt_padding:]
current_x2 = current_x2[-vap_processor.frame_contxt_padding:]
# 波形のプロット
time = np.arange(len(x1)) / sample_rate
ax1.plot(time, x1)
ax1.set_title('Audio Waveform')
ax1.set_ylabel('Amplitude')
ax1.set_xticklabels([]) # x軸のラベルを非表示
# VAP結果のプロット
ax2.plot(frame_indices, p_now_list, label='p_now', color='blue')
ax2.plot(frame_indices, p_future_list, label='p_future', color='red')
ax2.set_title('Voice Activity Projection (VAP) Result')
ax2.set_ylabel('Probability')
ax2.legend()
ax2.grid(True)
ax2.set_ylim(0, 1)
ax2.set_xticklabels([]) # x軸のラベルを非表示
# ターンの表示
ax3.plot(frame_indices, turn_now_list, label='Turn (p_now)', color='blue')
ax3.plot(frame_indices, turn_future_list, label='Turn (p_future)', color='red', linestyle='--')
ax3.set_ylim(-0.5, 1.5)
ax3.set_yticks([0, 1])
ax3.set_yticklabels(['Bot', 'User'])
ax3.set_title('Turn State (Score Threshold: {})'.format(score_threshold))
ax3.set_xlabel('Time (s)')
ax3.legend()
ax3.grid(True)
# x軸の範囲を統一
xlim = (0, time[-1])
ax1.set_xlim(xlim)
ax2.set_xlim(xlim)
ax3.set_xlim(xlim)
plt.tight_layout()
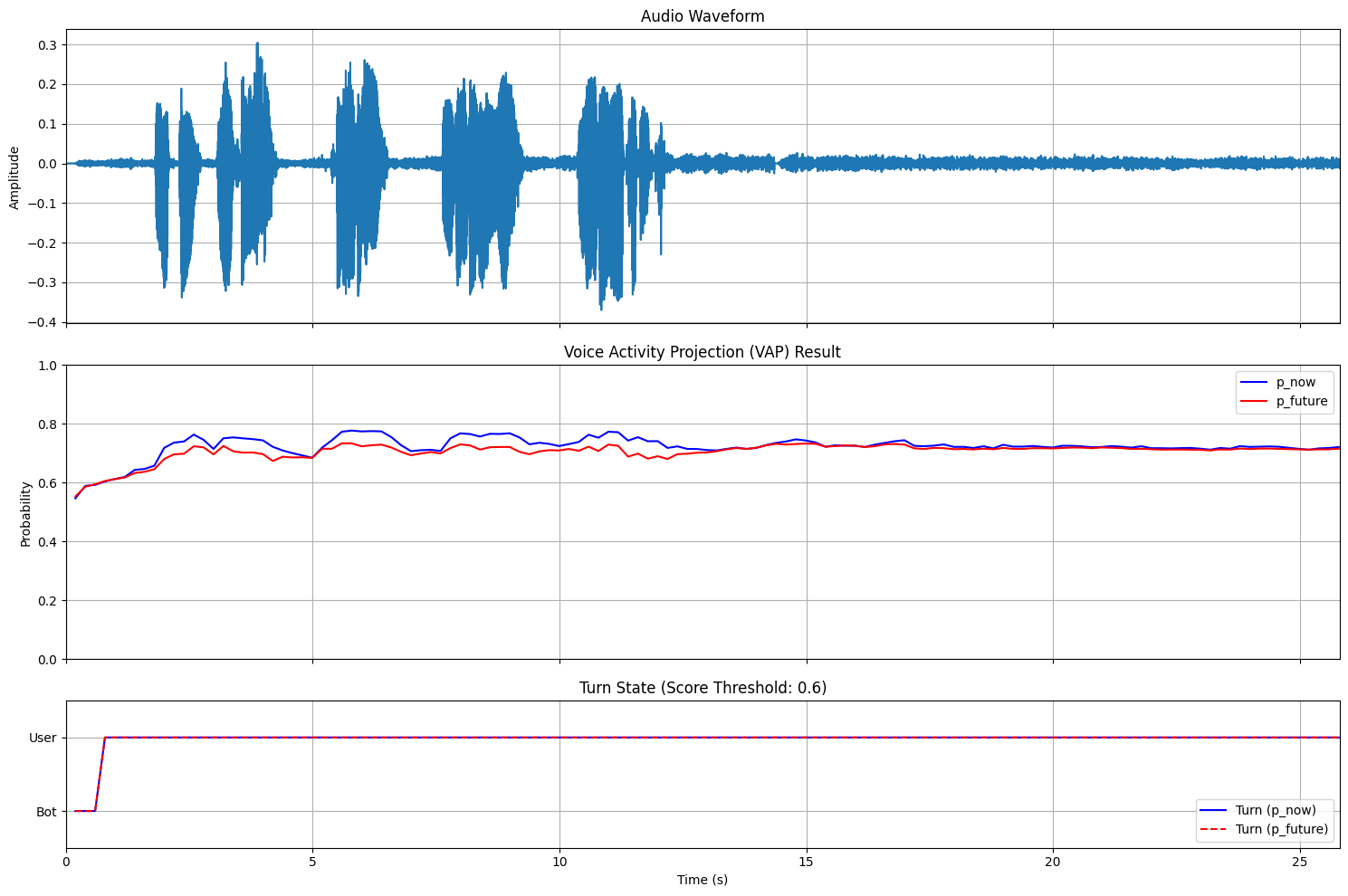
plt.show()audio_48kHz
audio_8kHz
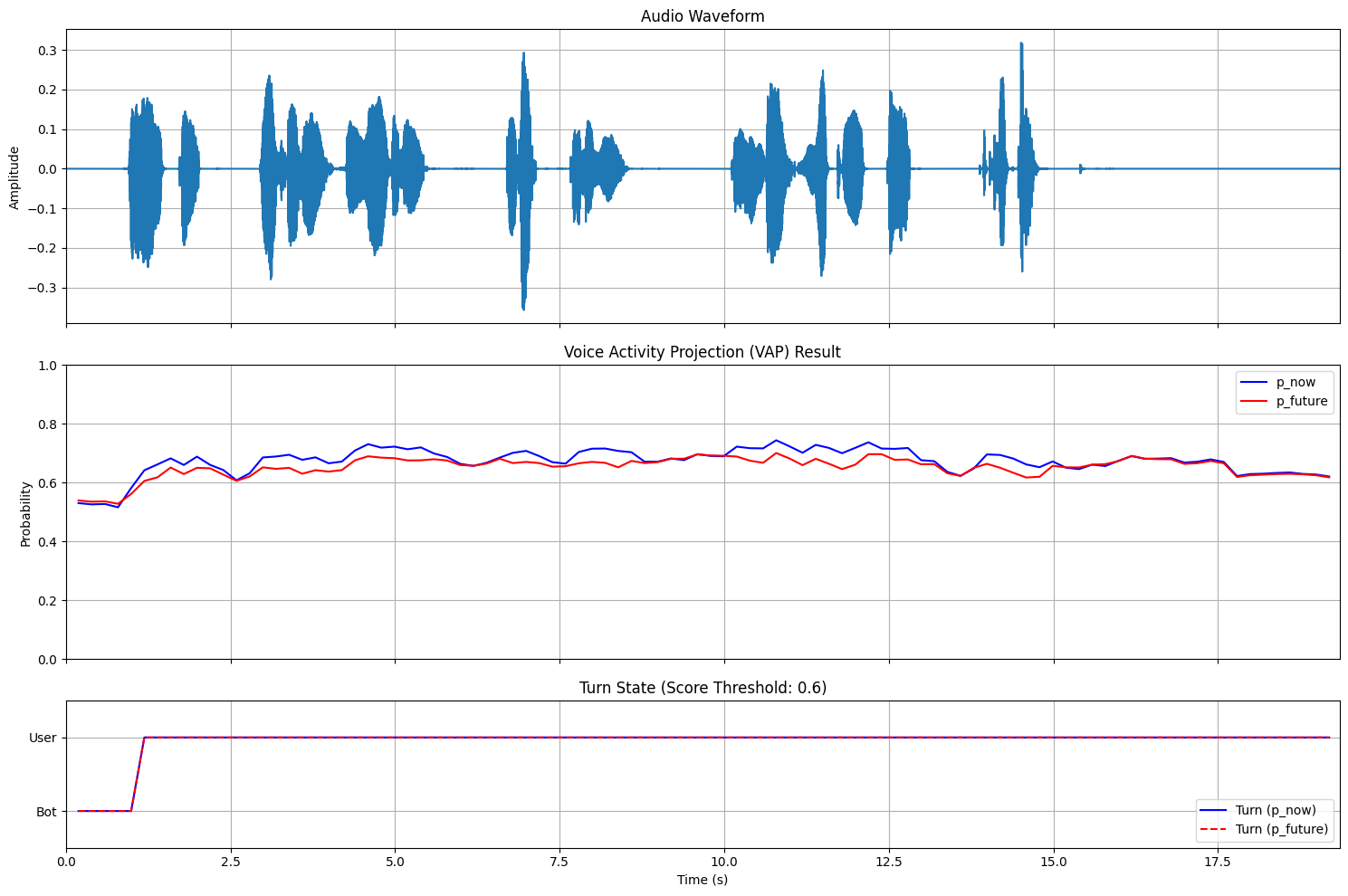
audio_48kHzとaudio_8kHzともにVAPの出力確率が高止まりしてしまっています。これはユーザが常にターンをとっていると予測していることを示しています。本来であれば、ユーザの発話が終わって無音が続くタイミングで確率が低くなってほしいです。 これは、おそらくCEJCのデータは日常会話であり、予約対話のようなタスク指向対話とはドメインが違うことにより本来の性能が発揮できていないことによるものだと思われます。また、VAPモデルの訓練時に過学習傾向が見られたため、訓練がうまくいっていない可能性があります。
VADを用いた発話終了検知
今回の検証ではVADを行うモデルとしてsilero-VADを用います。
silero-VADは、入力された音声チャンクに対して有声か無声かを判定するモデルです。このモデルを用いて、20msごとの音声チャンクを連続的に処理し、各チャンクの有声判定を行います。この有声判定結果を基にして、一定時間以上の無声区間を検知したら発話終了検知を行うというルールで発話終了検知を行います。用いた推論コードは以下の通りです。
from silero_vad import load_silero_vad
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
import numpy as np
import soundfile as sf
import torch
class AudioBuffer:
def __init__(self, window_size_samples, sample_rate):
self.window_size_samples = window_size_samples
self.buffer = torch.zeros(window_size_samples)
self.sample_rate = sample_rate
def update(self, new_chunk):
# バッファを左にシフトして新しいチャンクを追加
shift_size = len(new_chunk)
self.buffer = torch.cat([self.buffer[shift_size:], new_chunk])
return self.buffer
def plot_realtime_vad_analysis(wav_path,
threshold=0.5,
chunk_size_ms=20,
silence_threshold_ms=500):
# モデルのロード
model = load_silero_vad()
# 音声データの読み込み
audio_data, sample_rate = sf.read(wav_path)
wav = torch.from_numpy(audio_data).float()
# パラメータ設定
window_size_samples = 512 if sample_rate == 16000 else 256
chunk_size_samples = int(chunk_size_ms * sample_rate / 1000)
silence_threshold_samples = int(silence_threshold_ms * sample_rate / 1000)
# バッファの初期化
buffer = AudioBuffer(window_size_samples, sample_rate)
# 結果格納用の配列
vad_results = np.zeros(len(audio_data))
turn_states = np.zeros(len(audio_data))
# 状態の追跡用変数
is_speaking = False
silence_counter = 0
current_turn = 0
# chunk_size_samplesごとの処理
for i in range(0, len(audio_data), chunk_size_samples):
# 現在のチャンクを取得
chunk_end = min(i + chunk_size_samples, len(audio_data))
current_chunk = wav[i:chunk_end]
# チャンクが小さい場合はパディング
if len(current_chunk) < chunk_size_samples:
padding = torch.zeros(chunk_size_samples - len(current_chunk))
current_chunk = torch.cat([current_chunk, padding])
# バッファを更新
current_window = buffer.update(current_chunk)
# VADの判定
speech_prob = model(current_window, sample_rate).item()
is_speech = speech_prob >= threshold
# VAD結果の保存
vad_results[i:chunk_end] = 1 if is_speech else 0
# ターン状態の更新
if is_speech:
is_speaking = True
silence_counter = 0
current_turn = 1
else:
if is_speaking:
silence_counter += chunk_size_samples
if silence_counter >= silence_threshold_samples:
is_speaking = False
current_turn = 0
# ターン状態の保存
turn_states[i:chunk_end] = current_turn
# プロット
fig = plt.figure(figsize=(15, 10))
gs = GridSpec(3, 1, height_ratios=[1, 1, 0.5])
# 波形プロット
ax1 = fig.add_subplot(gs[0])
time = np.arange(len(audio_data)) / sample_rate
ax1.plot(time, audio_data)
ax1.set_title('Audio Waveform')
ax1.set_ylabel('Amplitude')
ax1.set_xticklabels([])
ax1.grid(True)
# VAD結果プロット
ax2 = fig.add_subplot(gs[1])
ax2.plot(time, vad_results)
ax2.set_ylim(-0.5, 1.5)
ax2.set_yticks([0, 1])
ax2.set_title(f'Voice Activity Detection (VAD) Result')
ax2.set_yticklabels(['Silent', 'Speech'])
ax2.grid(True)
# ターン状態プロット
ax3 = fig.add_subplot(gs[2])
ax3.plot(time, turn_states, 'r-', label='Turn')
ax3.set_ylim(-0.5, 1.5)
ax3.set_yticks([0, 1])
ax3.set_title(f'Turn State (Silence Threshold: {silence_threshold_ms}ms)')
ax3.set_yticklabels(['Bot', 'User'])
ax3.set_xlabel('Time (s)')
ax3.grid(True)
ax3.legend()
# x軸の範囲を統一
xlim = (0, time[-1])
ax1.set_xlim(xlim)
ax2.set_xlim(xlim)
ax3.set_xlim(xlim)
plt.tight_layout()
plt.show()audio_48kHz
audio_8kHz
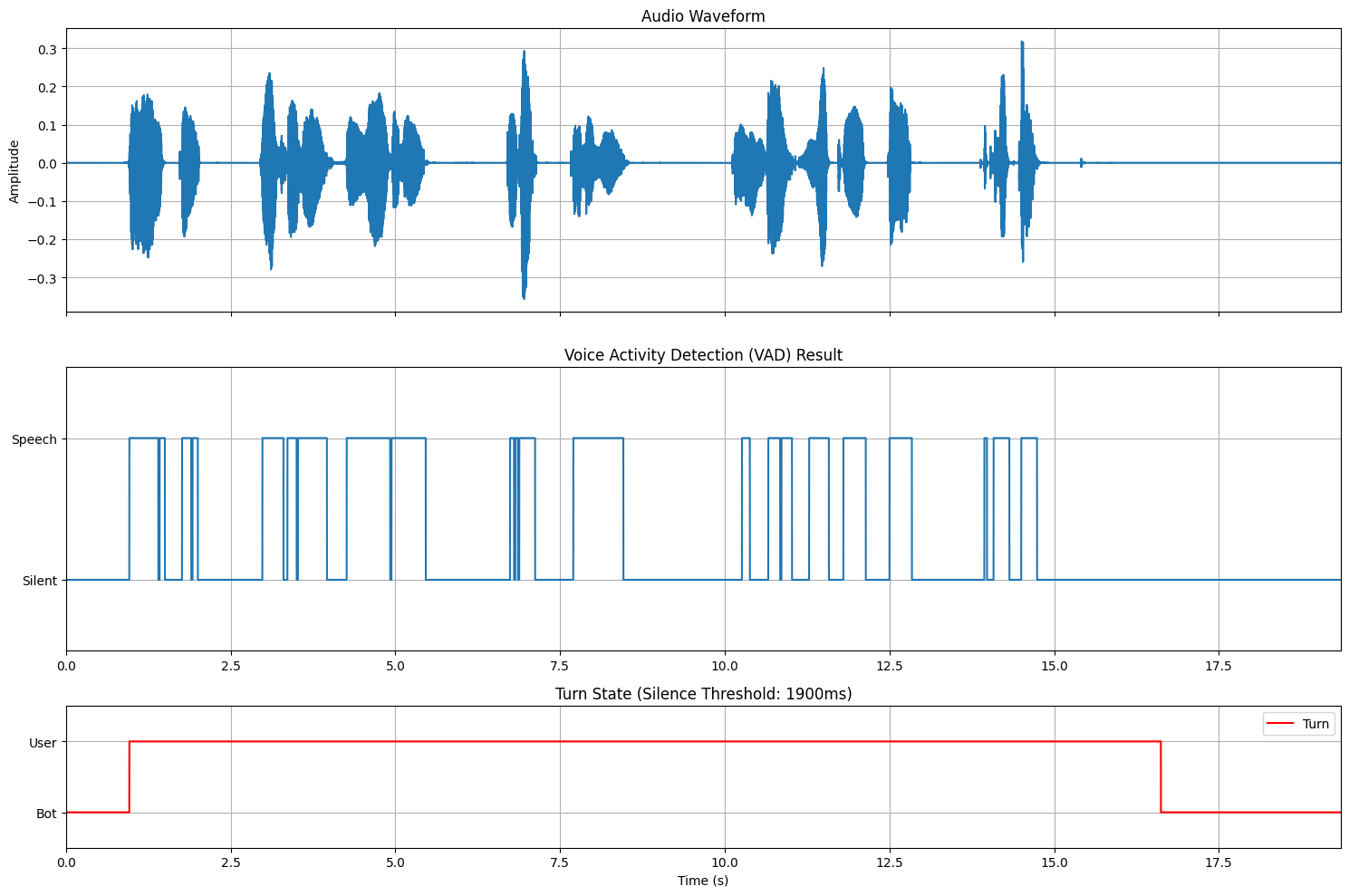
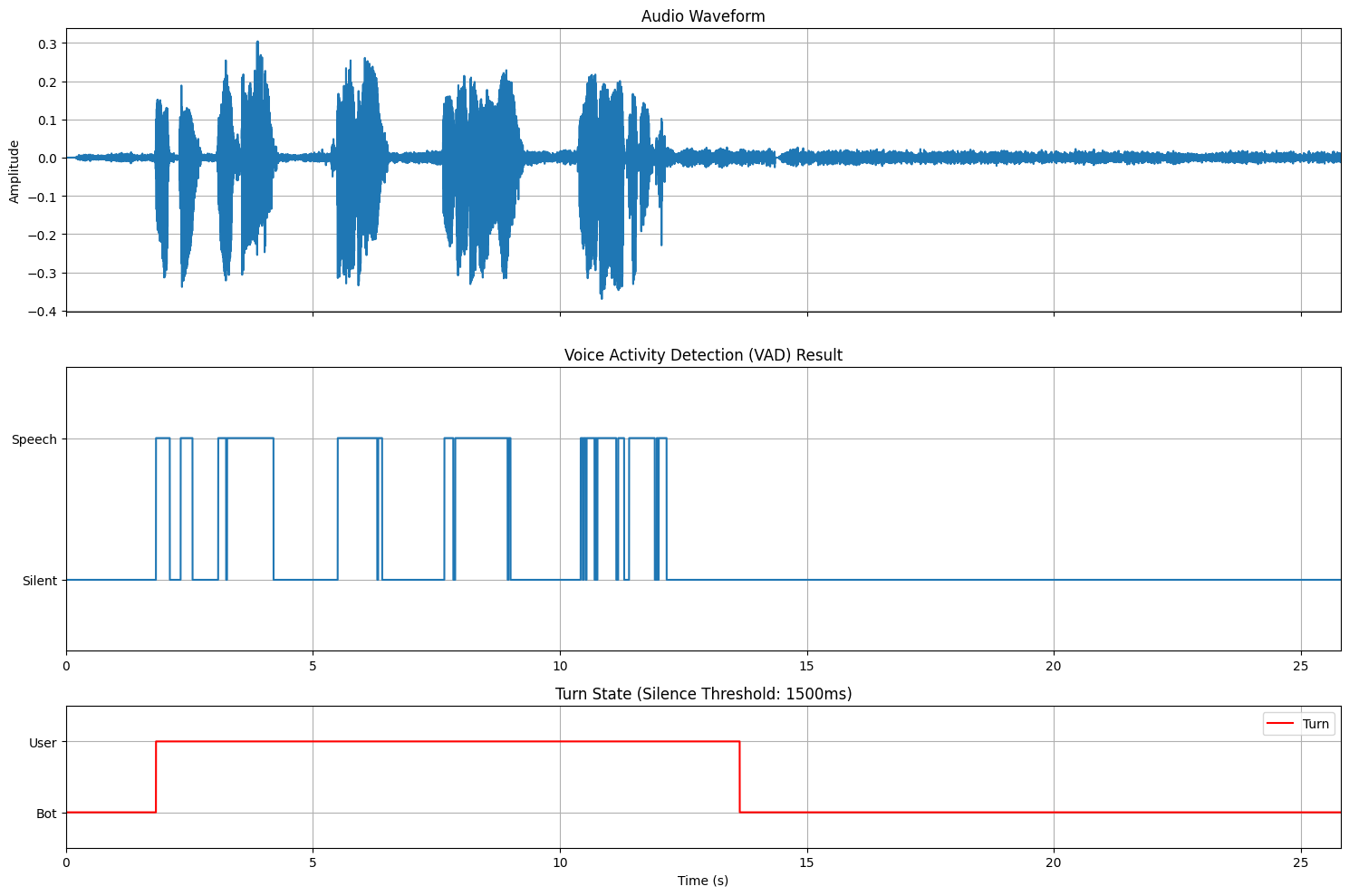
VADを用いた発話終了検知はルールベースなので制御性が高いです。上記の例では無音継続長の閾値を調整することで、検知は遅れてしまうものの、途中の言い淀みにも頑健に処理できています。運用する際には、言い淀みに対する頑健さと検知の遅延とのトレードオフが最適になるように閾値を調整する必要がありそうです。
まとめ
本記事では、VAPやVADを用いた発話終了検知について扱いました。
VAPは柔軟な発話終了検知を行うための有望なアプローチだと思いますが、今回の検証ではそもそも学習がうまくいかず期待するような結果とはなりませんでした。また、学習がうまくいったとしても音響条件によって性能が左右されやすいので、性能面で改善の余地がまだまだ残されているなと感じました。
一方で、VADを用いた方法は、一定程度の発話終了検知の遅延が避けられないため、柔軟なターンテイキングを実現する方法としてベストな方法ではなさそうですが、制御性の面で機械学習的なアプローチよりも優れているため、システムには導入しやすいと思います。また、ハイパーパラメータを最適化することで、ある程度柔軟なターンテイキングに近づくのではないかと感じました。
今後、音声対話において会話の「間」というのは顧客体験を向上させるために、ますます重要になってくると思います。弊社AIチームとしても引き続きこの分野の動向を注視し、プロダクトへの応用可能性を探っていきたいと考えています。
明日は、インフラチームの大長から記事が上がる予定です。
ご精読ありがとうございました。




