こんにちは。AIチームの杉山です。
弊社は東京都立大学の小町研究室とチャットオペレーター支援に関する共同研究をさせていただいているのですが、今回はそちらの取り組みについて紹介いたします。
モチベーション
弊社が運営するチャットボットサービスAI Messengerでは、チャットボットだけでは解決できなかった問い合わせに対して、有人オペレーターに繋いで解決まで導く仕組みを持っています。また、そのオペレーターをグループ内で運用しており、その採用や教育にも力を入れています。しかし、CS系オペレーター業界全般の傾向として離職率の高さやそれに伴う教育コストの肥大化といった課題があります。そこで、経験の浅いオペレーターが円滑に業務を行うことができるように自然言語処理の技術を使って支援することができないかと考えました。実際に現場のオペレーターにヒアリングをしたところ、以下の2点が主に難しい・時間がかかる作業であることがわかりました。
- カスタマーからの問い合わせ内容をチャットボットへの入力から汲み取ることが難しい。ナレッジのどれに該当するのか判別できない。
- ナレッジから回答を見つけることができても、どのように伝えれば良いのか、適切な文章を作成するのが難しい
そこで、これらの課題解決をテーマとして2つの実験・検証を行いました。
発話内容のカテゴリ予測
まず1つめのテーマとしてボットとカスタマーの対話履歴から、問い合わせがナレッジのどのカテゴリに関するものであるかを予測するタスクを行いました。ボットでの自動応答からオペレーターに対応が移る際、オペレーターはボットとカスタマーの対話履歴を見てどのような問い合わせか確認してから対応します。
そこで、ボットからオペレータへの切り替え時にカテゴリが予測できれば、ナレッジからの検索がしやすくなったり、何を追加で質問すればいいかが分かったりします。
実験
このテーマはいわゆるテキスト分類にあたるため、分類問題でよく用いられるランダムフォレスト(RF)を用いたカテゴリ予測と、BERT を回帰モデルとして再学習させてカテゴリを予測する実験を行いました。カテゴリにはゲーム関連、解約関連などの大カテゴリと、各大カテゴリの下にある中カテゴリがありますが実用性を考えて中カテゴリの予測を行います。
データ
オペレーターとの対話に移行する前にカテゴリを予測できることが望ましいため、ボットとカスタマーの対話のみを用います。カテゴリは対話の流れには依存しないと仮定し、1つの対話を繋げて1文書として扱います。各カテゴリで対話数の多いカテゴリもあれば少ないカテゴリもあるため、対話数が20以下のカテゴリは省いています。 全部で18の中カテゴリ(6つの各大カテゴリに対し中カテゴリが3つずつ)がついた654対話を使用します。実際はもっと大量のデータがあるのですが、共同研究先へデータを提供するために個人情報のマスキングを行ったものに限った結果心許ない数になってしまいましたが、これについては考察で述べることにします。
ランダムフォレスト
素性としては、以下の2つを用いました。
- Bag of Words (BoW)
- word2vecの平均
- 学習済みの日本語Wikpediaエンティティベクトルを使用
BERTの再学習
事前学習済みモデルとして、 Yohei Kikutaさんのbertjapaneseを使用しました。
ボットとカスタマーの会話の単語数の分布を調べたところ、多くがこのモデルの最大入力トークン数の512を超えていたため、 ボットの回答は含めずカスタマーの発言のみを用いるようにしました。
評価
5分割交差検証で評価を行い、 各カテゴリの Precision, Recall, F1値およびそれぞれのマクロ平均を評価します。
結果
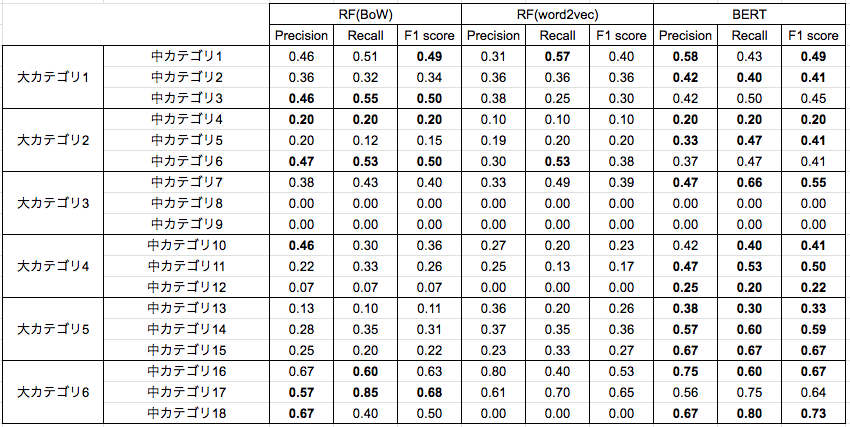
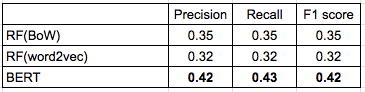
実データを用いているため、カテゴリ名は伏せて結果を示します。
考察
- 中カテゴリごとに見ると、カテゴリ16や18のように比較的当てることができるカテゴリもあれば、中カテゴリ8や9のように全く当てられていない中カテゴリも存在します。 比較的当てることができているカテゴリの会話ではそのカテゴリ固有の単語がよく出てくる傾向があり、 BoWでもある程度の精度が出たのではないかと考えられます。
- BERTを用いた手法が、他の手法に比べると比較的高いスコアとなっていますが、数値だけでみると実用的な精度とは言えない結果となりました。 これに関しては、学習データが少なすぎることがまず考えられたため、弊社の方で個人情報をマスクしていない全件データ(654対話->8480対話)で試しましたが、それほど結果が変わらなかったためデータ量の問題だけでなくデータの性質上難しいタスクであったと考えられます。
まとめ
ボットとカスタマーの会話から、問い合わせのカテゴリを予測するタスクを行いました。 3つの手法で比較を行い、 BERTを用いた手法が一番精度が高いことがわかりました。 しかし今のままでは実用には厳しい精度であるため、大分類までは人手で判断する、もしくはPrecision@Kのように候補を複数提示してオペレーターに選択してもらう、というように運用と合わせて組み込むのがいいのではないかと思います。
スタイル変換
もう一つのタスクとして経験の浅いオペレーターの発話をベテランオペレーターの発話に寄せるスタイル変換の実験を行いました。不慣れなオペレーターが作成した文章を良い応答文のスタイルに変換することで、文章作成の手間や難しさを軽減することを目指しています。
仮定
カスタマーの満足度に直結する要因としてオペレーターの応答文が関係していると考えられます。オペレーターの応対文品質を評価する指標としては複数考えられますが、今回は経験年数を指標に実験を行うことにします。経験年数が長い人の応対文は良い応答と仮定し、全ての応対をこれに近づけることを目的とします。なお、今回は表現のみに注目し、内容については評価しません。そのため、内容は変わっていないことが前提となります。
技術検討
今回はスタイル変換と呼ばれる技術でこれが実現可能かを実験します。
ICML2017でHuらが発表した Toward Controlled Generation of Textに基づいたスタイル変換を行います。この手法ではパラレルコーパスを用意する必要はなく、スタイル変換前後の文をそれぞれ収集するだけで実行できます。なおソースコードはTexar内にあるものをベースに行います。
モデルの説明
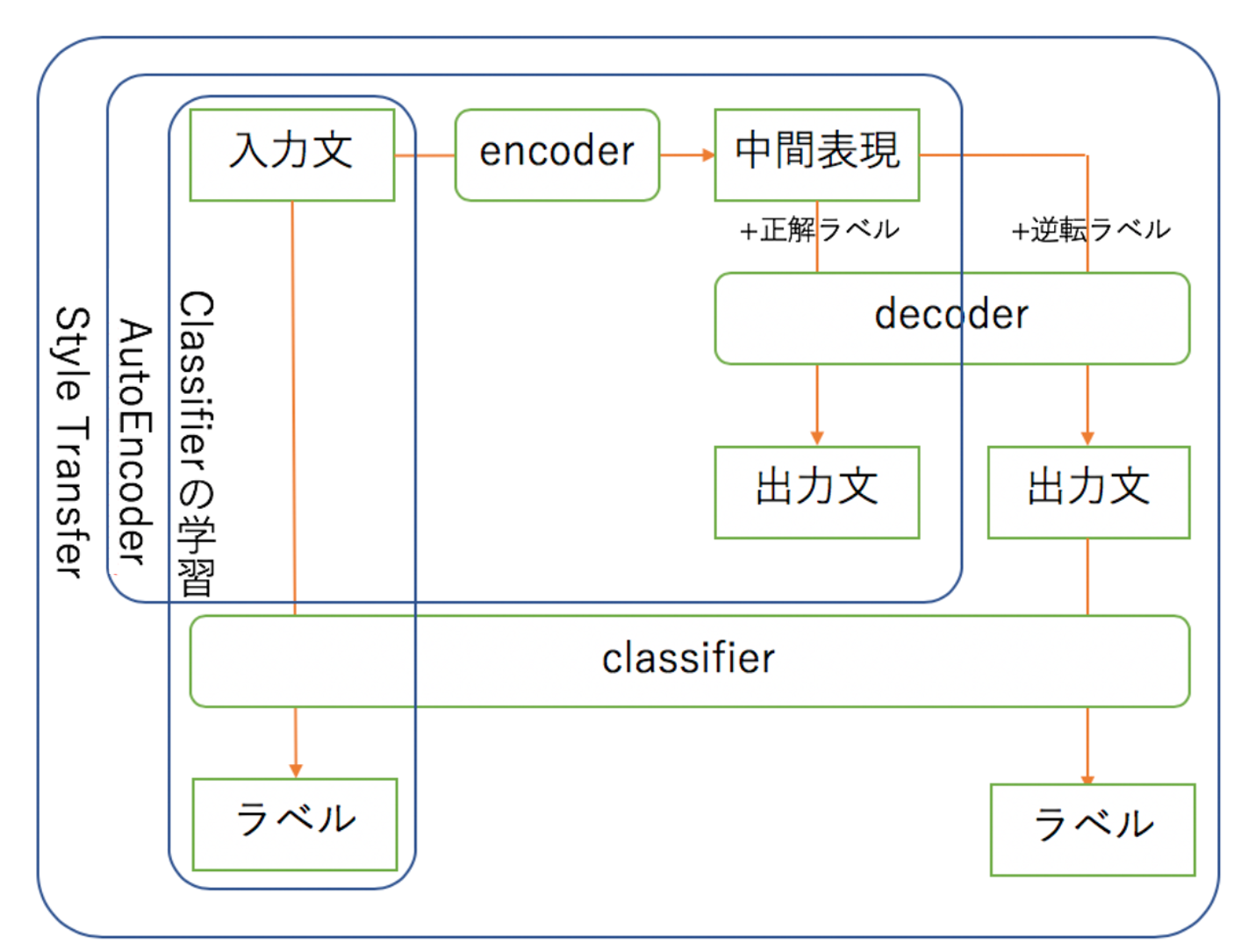
このモデルには3つの構造があります。
- AutoEncoder: 中間表現を学習する(入力文のラベルの文を生成する)
- Classifier: 入力された文のラベル(今回はベテランかどうか)を評価する
- Style Transfer: classifierのlossを用いて逆転ラベルの文を生成するように学習する
また、ハイパーパラメータが2つ存在します。
- gamma: Style Transfer学習時のGumbel-Softmaxのパラメータ
- lambda: Style Transfer学習時にClassifierのLossの考慮割合
データ
実際の対話データから特定の分野に関する対話だけに絞って実験を行います。
今回は対話のうちオペレータの発話のみを抽出しています。
ある特定の条件に基づいてデータ整形を行い、実験に用いた文数は下の表のようになりました。
| 対話数 | 文数 | (内ベテラン文数) | |
|---|---|---|---|
| 学習用 | 1,182 | 17,353 | 12,500 |
| 評価用 | 643 | 7,249 | 5,208 |
対象文の中には挨拶文から特定の内容に関する文まで多岐にわたり、挨拶文などは複数の対話で同一の表現が使われることもあります。
データには以下のようなものがあります。
ここ まで の ご 案内 で 、 ご 不明 点 など は ござい ませ ん でしょ う か ?
実験設定
一般的な設定は前述のソースコードに沿って行います。
以下は独自に設定したものです。
- クラスター構造:単方向LSTM(公開実装ではConv1D)
- gamma:0.001, 0.01
- lambda:0.1, 0.5, 0.9
- エポック:100
評価方法
- BLEUによる自動評価
- 入力文との評価を取っているため、BLEU=100は一切訂正が行われていません。
- 出力文による人手での考察
実験結果
- BLEUスコア(一部)
| lambda | gamma | BLEU |
|---|---|---|
| 0.01 | 0.1 | 14.19 |
| 0.01 | 0.5 | 10.54 |
| 0.01 | 0.9 | 7.71 |
| 0.001 | 0.1 | 18.88 |
- 出力文(lambda=0.001, gamma=0.1の時の一部抜粋)
- 入力文
>それでは しばらく お待ち ください ませ 。 - 出力文
>それでは 少々 お待ち ください ませ 。
- 入力文
考察
- BLEUによるチューニングの考察
- gammmaを減らすことがBLEUスコアの向上に繋がる
- lambdaを減らすことがBLEUスコアの向上に繋がる
- 出力文に極度の影響を与える操作をすることは好ましくない
- 出力文による考察
- 部分的な変化が多く、語彙の選択が変わる程度の影響である
- 例文には載せられないが、経験年数の短いオペレータの名前が経験年数の長いオペレータの名前へと置き換えられた
- 文頭に「ただいま」をつけたり「少々」が「2〜3分」に置き換わったりと、カスタマーを安心させるような具体性のある言い回しへの変換を得られるケースも存在した。
まとめ
今回検討した手法は文の内容から変化させるものに影響がある(先行研究より)が、今回のように内容は変わらず表現を変えるような小規模編集にはあまり効果を示しませんでした。また文脈などの影響は軽度であり、単語などの要素が大きな影響を示しました。
単語の置換ではなく、ベテランオペレーター特有の上手な言い回しやカスタマーを慮るような表現へのスタイル変換を期待したのですが、今回はその辺りをうまく学習することができなかったため今後はそこを考慮できるような手法を調査・検証していければと思います。
終わりに
弊社が小町研と取り組んでいる共同研究について紹介してきました。実用性と先進性のバランスのいいテーマの検討や個人情報を含むデータの取り回しなど難しい箇所は存在しますが、少しずつ前進してこのような形で結果を公開できるとこまできました。今後はプロダクトに乗せるところまで成果を進めたり、学会へのアウトプットまでできるように引き続き取り組んでいきたいと思います。




