こんにちは、AIチームの杉山です。
今回は、私の好きな言語であるC#で機械学習を行ってみて、そのPros./Cons.や実用の可能性について検証してみたいと思います。なぜどこにもニーズのなさそうなことをやろうと思ったかと言うと、私がC#が好きだからです。(0点🙅♂️)
普段使いしているPythonとの比較のために、Pythonとの違いやPythonだったらどう書くかをなるべく記述していく予定です。
C#
このブログは自然言語処理や機械学習系の興味を持っている方がご覧になることが多いと思いますが、その界隈ではC#はあまり一般的でないことが多いと思うので簡単に紹介します。
C#はMicrosoftにより開発されているタイプセーフなオブジェクト指向のプログラミング言語です。.NETやVisual Studioとの組み合わせにより高い生産性を得られるため、エンタープライズアプリケーションの開発などに用いられるケースが多いです。C#は後述の.NET (Framework/Core)上で動作するため、その共通言語ランタイムが解釈できる共通中間言語にコンパイルされ、実行時にJITコンパイラが処理を行い実行されます。これはC言語やC++のようなAOTコンパイラ方式に比べると速度面では劣りますが、Pythonのようなインタプリタ方式の処理系よりは高速に動作することが期待されます。ここが今回C#で機械学習を試そうと思った主なモチベーションになります。詳細な言語仕様に関してはこちらをご覧ください。
また、C#と言うとWindowsでアプリケーション開発をするための言語というイメージが強いかと思います。確かにASP.NETやWPFを作成するフレームワークでありランタイム環境である.NET FrameworkはWindows上で動作するものでした。しかし最近ではLinuxやMacとのクロスプラットフォーム開発のためのOSSである.NET Coreの開発が進んでおりWindows以外の環境でも動作します。今後は.NET Frameworkは.NET Coreの後継である.NETに統一される予定のため、よりWindowsだけのものというイメージは薄くなっていくと思われます。今回の記事は、普及のためにあえてMacを対象としています。
C#で機械学習を行うためのライブラリ
Pythonが機械学習系プロジェクトに用いられる大きな理由としてscikit-learnやTensorFlowといった機械学習ライブラリの存在があります。C#ではどうかというと、ML.NETというライブラリがMicrosoftから2018年にリリースされました。(C#にはAccord.NETという機械学習系ライブラリもありますが、ML.NETの登場によりそちらがメインストリームになるであろうことから開発が止まってしまいました..)近年、従来にも増して人工知能系のトップカンファレンスでMicrosoft Researchによる論文を見ることが多くなりましたが、その知見や内部での実装が反映されていることが特徴です。既にMicrosoftの多くの製品で実用されておりAzure Stream Analyticsでの異常検知やPower PointのDesign Ideas(画像を挿入したらこんな配置はどうですか、とサジェストが出るアレです)などで使われているそうです。
精度面、速度面について前述のscikit-learnと分散型インメモリ機械学習プラットホームであるH2Oとの比較が行われており、図のようにどちらにおいてもML.NETが一番優れていたとされています。
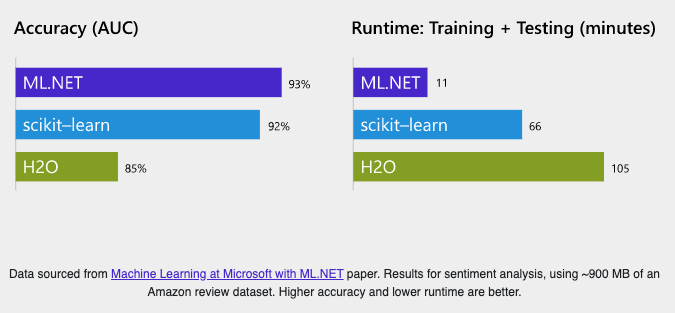
Amazon review datasetによるsentiment analysisの結果。他にもレコード数、特徴量ともに大規模なデータセットであるCriteoデータセットとFlight Delayデータセットでも同様にML.NETが最優位であることが示されています。
また、scikit-learnは主にメインメモリに収まるデータセット上でのインタラクティブなユースケースを対象としていますが、その特性上、大きなデータの扱いにはいくつかの制限があります。データセットのストリーム化ができず、メインメモリからのバッチアクセスしかできないことや、PythonのGILの制限によりマルチコア処理をネイティブにはサポートしていないなどです。ML.NETでは,DataViewによる抽象化やデータベースの考え方から着想を得た技術により,上述の問題を解決したとされています。この辺りは今後実装していく中で確認したいと思います。
加えて、TensorFlowやONNXとの連携がサポートされていたり、PythonからML.NETを利用するためのバインディングであるNimbusMLが公開されたりと周辺エコシステムとの共存も考慮されており、.NETアプリケーションへの組み込みを容易にするための配慮が感じられます。
ML.NETに関する詳細は論文として公開されておりますのでこちらをご覧ください。
なお、ML.NETは同じ.NETファミリーであるF#からも呼ぶことができるため、関数型言語が好きな方も安心(?)です。
準備
**以降の記述は全てmacOSを対象とします。**
前置きが長くなりましたが、実際に使ってみることにします。
まずは.NETのIDEであるVisual Studio for Macをインストールしましょう。こちらからダウンロードできます。また、実行環境である.NET SDKはこちらからダウンロードできるので、こちらもインストールしておきます。
インストールが終わったら、適当なコンソールアプリケーションのプロジェクトを作って実装できる状態にしましょう。
次に、ML.NETの準備をします。ML.NETはNuGet(PythonでいうPyPIのようなパッケージ管理プラットフォーム)に公開されているため、[NuGet Packageの管理]からMicrosoft.MLを選択し、プロジェクトに追加します。
以上で準備は終わりです。
Hello world.
それでは、チュートリアル的によく用いられるIris Datasetで多クラス分類の実装をしてみたいと思います。
ML.NETによる実装は大きく以下の流れで行います。
- MLContext(後述)の作成
- データの読み込み
- データの前処理と学習パイプラインの作成
- モデルの学習
- 検証データによる評価
流れ自体は一般的な機械学習のフローと同じかと思いますが、ML Contextについて補足します。ML ContextはML.NETで必要な操作を内包するクラスで、データの読み込みや操作、モデルの選定などはML Contextクラスのオブジェクト経由で行います。また、その名の通りコンテキストを管理するため、ランダムシードの設定はインスタンス化時に行います。
では、実際にそれぞれのコードを書いていきたいと思います。
MLContextの作成
ここではおまじない的にMLContextクラスをインスタンス化するのみで大丈夫です。ランダムシードを固定する場合はこの時点で引数として与えます。
var mlContext = new MLContext(seed: 0);データの読み込み
データの読み込みは、先ほどのMLContextクラス下のData経由で行います。Irisのデータはテキスト(tsv)ファイルであるため、LoadFromTextFileを用いるのですが、そのジェネリックに読むこむファイルの型をクラス定義する必要があります。Pythonであればpandas.read_csv()などで容易に読み込むことができるのですが、C#がタイプセーフであるためこの一手間が必要になり少々辛いところです。
データは遅延評価されるためこの時点では読み込まれずスキーマ情報などが渡されます。
public class IrisData
{
[LoadColumn(0)]
public float Label;
[LoadColumn(1)]
public float SepalLength;
[LoadColumn(2)]
public float SepalWidth;
[LoadColumn(3)]
public float PetalLength;
[LoadColumn(4)]
public float PetalWidth;
}
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<IrisData>(TrainDataPath, hasHeader: true);
IDataView testDataView = mlContext.Data.LoadFromTextFile<IrisData>(TestDataPath, hasHeader: true);データの前処理と学習パイプラインの作成
今回は簡単のために特別前処理は行いませんが、列名と目的変数・特徴量のマッピングを以下のように行い、パイプラインとして定義します。前処理が必要な場合はここに追記する形で実装します。
また、最後のAppendCacheCheckpointは大きくないデータに対してインメモリで計算するための設定で、大きいデータに対してストリーム的に扱う場合は不要です。
var dataProcessPipeline = mlContext.Transforms.Conversion
.MapValueToKey(outputColumnName: "KeyColumn", inputColumnName: nameof(IrisData.Label))
.Append(mlContext.Transforms.Concatenate("Features", nameof(IrisData.SepalLength), nameof(IrisData.SepalWidth),
nameof(IrisData.PetalLength), nameof(IrisData.PetalWidth))
.AppendCacheCheckpoint(mlContext));モデルの学習
学習アルゴリズムの設定はML Context以下に用意されているものを使用することができます。今回はアヤメの種類を予想する多クラス分類の問題なので、MulticlassClassificationのTrainerに用意されている多クラスロジスティック回帰(SdcaMaximumEntropy)を用いることにします。先ほどのデータハンドリング用のパイプラインにTrainerを加え、scikit-learnのように.Fitすることがモデルの学習を行います。trainingDataViewはLazy Loadされ、この時点で初めてデータが読み込まれます。
var trainer = mlContext.MulticlassClassification.Trainers
.SdcaMaximumEntropy(labelColumnName: "KeyColumn", featureColumnName: "Features")
.Append(mlContext.Transforms.Conversion
.MapKeyToValue(outputColumnName: nameof(IrisData.Label) , inputColumnName: "KeyColumn"));
var trainingPipeline = dataProcessPipeline.Append(trainer);
ITransformer trainedModel = trainingPipeline.Fit(trainingDataView);
検証データによる評価
モデルの学習が終わったら、検証データを用いてモデルの評価を行います。
testDataViewを学習モデルに合わせて変換し、Evaluateメソッドに渡すことで結果を得ることができます。多クラス分類の結果を出力するヘルパーメソッドに結果を渡すことで、Macro/Micro F1やLogLossなどを確認することができます。
var predictions = trainedModel.Transform(testDataView);
var metrics = mlContext.MulticlassClassification.Evaluate(predictions, "Label", "Score");
Common.ConsoleHelper.PrintMultiClassClassificationMetrics(trainer.ToString(), metrics);
AccuracyMacro = 1, a value between 0 and 1, the closer to 1, the better
AccuracyMicro = 1, a value between 0 and 1, the closer to 1, the better
LogLoss = 0.0036, the closer to 0, the better
LogLoss for class 1 = 0.0004, the closer to 0, the better
LogLoss for class 2 = 0.0043, the closer to 0, the better
LogLoss for class 3 = 0.0057, the closer to 0, the betterIris Datasetの分類は簡単な問題設定ですが、このように正常に学習が進んでいることがわかります。
終わりに
前段が長くなってしまったので、今回はここまでとします。今回の多クラス分類を始め、異常検知やレコメンドなど他の手法のチュートリアルがこちらにあるので、気になる方はご確認ください。
使ってみた感想としては、メソッドチェーンで処理をパイプライン的に書けるのは良さそうに思いました。また今回は扱いませんでしたがpandasのDataFrameに対する操作感も、LINQ to Objectで代替できそうです。ただ、型周りの取り回しがやはりネックになりそうに感じました。加えて、機械学習モデルを組む際には必ず探索的にデータを分析するフェーズが必要になりますが、進んで戻ってを繰り返すこのフェーズは明らかにPythonのインタプリタ形式が適していると思います。なのでデータの分析自体はJupyterなどで行い、学習の方針が定まったらパフォーマンスや大規模データの扱いに強いML.NETで学習を行い.NETアプリケーションから呼び出すなど用途で使うのがいいのかと思いました。
まだまだ恩恵を得られるほど深掘りできていないため、今後はもう少し利用ケースや適切な使い方について見ていきたいと思います。




