こんにちは。
AIチームの戸田です。
先日公開されましたT5の多言語版、Multilingual T5(以下mT5)の事前学習モデルを使って、我々AI Shiftの提供するチャットボットプロダクト、AI Messengerを通して収集されたカスタマーサポートの対話を学習させてみました。
T5のfine-tuningについては株式会社オージス総研様のこちらの記事が非常に参考になりましたので、是非そちらもご覧いただければと思います。
そもそもT5とは?
T5とはText-to-Text Transfer Transformerというモデルの略称です。T5はあらゆるタスクをText-to-Text、つまり入力も出力もテキストで学習してしまおうというモデルになります。(元論文)
ベースはBERTで使用されるものと同様のTransformerで、Colossal Clean Crawled Corpus(以下 C4)という大規模コーパスで事前学習されます。mT5はこれの多言語版のmC4で事前学習されます
BERTなどの従来の事前学習モデルは下流のタスクに応じてヘッダーを合わせる必要があります。
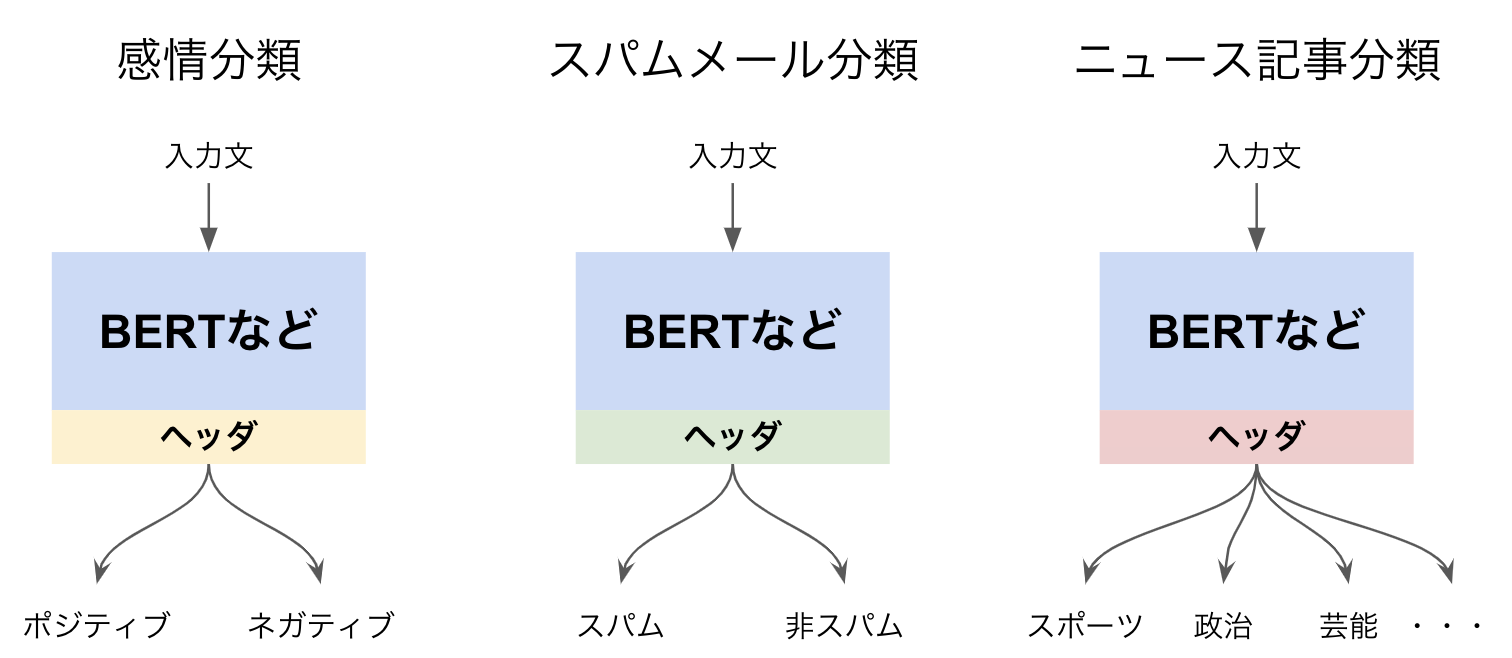
一方T5は下図(元論文Figure1)のように入力文の先頭にタスクに応じた特殊タグを付け加えることで、それぞれのタスクを解くことができます。
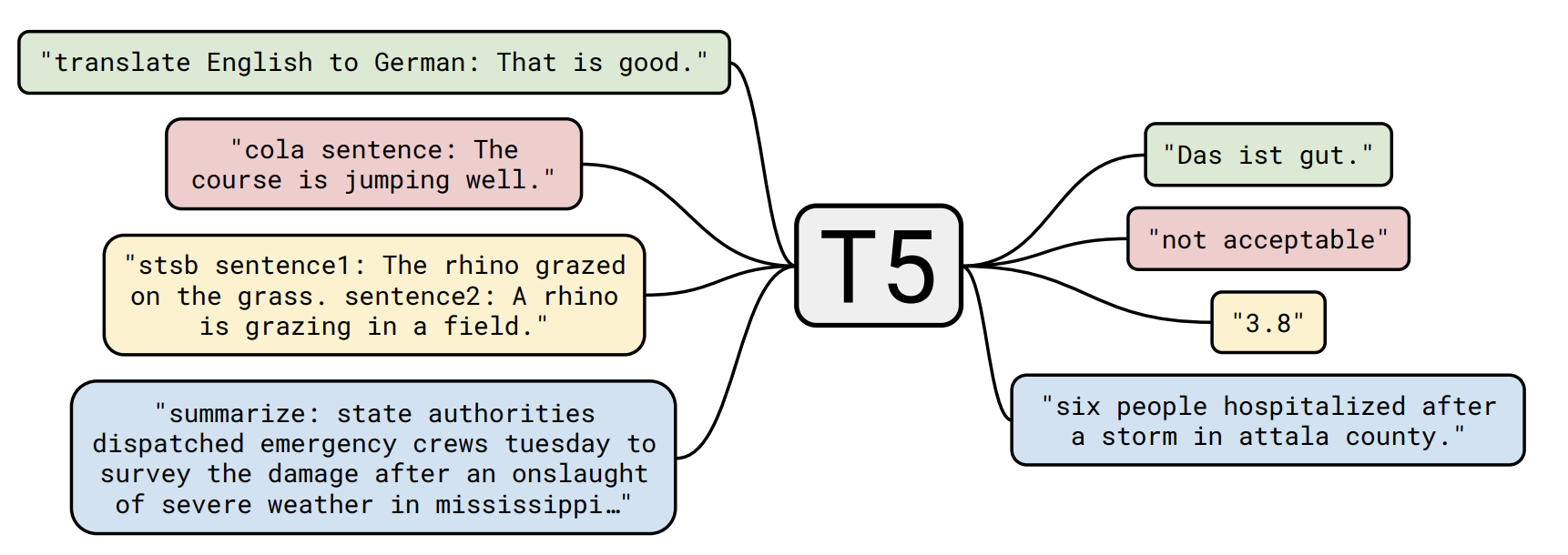
翻訳や要約といったタスクもヘッダーを変える必要がなく、とてもfine-tuningしやすいモデルとなっています。
詳細なモデル構造やハイパーパラメータ、損失関数などはもとの論文で詳細な比較実験が行われているので、本記事では割愛させていただきます。
用意した対話データでfine-tuning
ここからは本題のfine-tuningの実践になります。
まずは学習させるデータを用意します。今回は我々の保有する、あるインフラ系のカスタマーサポートの対応データを利用します。(データ取り扱いの都合上、一部マスキングさせていただく部分もございますがご了承ください。)
import pandas as pd
df = pd.read_csv("<対話ログデータのcsvファイル>")
train_df = df.iloc[3:]
test_df = df.iloc[:3] # テスト用に3個分、対話ログ保存しておくデータは以下のカラムを持ちます
- Timestamp: 発話時刻
- ConversationID: 1つの会話ごとにつけられたユニークID
- Speaker: 発話者(カスタマー or オペレーター or システム)
- Text: 発話内容
text-to-textで、入力をユーザーの発話、出力をオペレーターの発話として学習し、自動応答を行うボットを作りたいと思いますので、データ形式を揃えます。
以下にサンプルを示します。

左のカラムがカスタマーの発話、右のカラムがそれに続くオペレーターの発話になります。行の前後関係は現状考慮していません。
こちらのファイルをtsv形式でtrain_data.tsv、test_data.tsvという名前で保存します。
学習
T5に限らず、Transformerで構成されるモデルは非常にパラメータが多いため、学習にはGPUやTPUなどの計算資源が必要です。今回はGoogle Colaboratoryを使ってGPUでfine-tuningを行おうと思います。
事前準備
まずは必要なライブラリをインストールします。
# T5ライブラリ
!pip install t5[gcp]
!pip install tensorflow-gpu
!git clone https://github.com/google-research/multilingual-t5.git
# 日本語を扱う上で必要なライブラリ
!apt-get install mecab mecab-ipadic-utf8
!pip install mecab-python3 sumeval
!apt-get install nkf
!pip install janome
!pip install sacrebleu[ja]加えてcloneしたmultilingual-t5ディレクトリにパスを通しておきます
import sys
sys.path.append("/content/multilingual-t5/")次にオージス総研様の記事を参考に、以下のようなT5のタスクを定義(t5_chatbotとします)するpythonプログラムのファイルを作成してGoogle Colaboratory上アップロード、t5_chatbot.pyという名前でmultilingual-t5ディレクトリに移動します。
import t5.data
from t5.data import sentencepiece_vocabulary
from t5.evaluation import metrics
from t5.data import preprocessors
from t5.data import TaskRegistry
from t5.data import TextLineTask
import functools
import tensorflow as tf
from sumeval.metrics.lang.lang_ja import LangJA
from sacrebleu import corpus_bleu, TOKENIZERS
lang_ja = LangJA()
DEFAULT_SPM_PATH = "gs://t5-data/vocabs/mc4.250000.100extra/sentencepiece.model"
DEFAULT_VOCAB = sentencepiece_vocabulary.SentencePieceVocabulary(
DEFAULT_SPM_PATH)
DEFAULT_OUTPUT_FEATURES = {
"inputs": t5.data.Feature(
vocabulary=DEFAULT_VOCAB, add_eos=True, required=False),
"targets": t5.data.Feature(
vocabulary=DEFAULT_VOCAB, add_eos=True)
}
# オージス総研様と同様にBLEUを指標にしたいと思います
def bleu(targets, predictions):
predictions = [tf.compat.as_text(x) for x in predictions]
if isinstance(targets[0], list):
targets = [[tf.compat.as_text(x) for x in target] for target in targets]
else:
targets = [tf.compat.as_text(x) for x in targets]
targets = [targets]
bleu_score = corpus_bleu(predictions, targets,smooth_method="exp", smooth_value=0.0,
force=False,lowercase=False,tokenize="ja-mecab", use_effective_order=False)
return {"bleu": bleu_score.score}
task_name = "t5_chatbot"
tsv_path = {
"train": "/content/train_data.tsv",
"test": "/content/test_data.tsv",
}
TaskRegistry.add(
task_name,
TextLineTask,
split_to_filepattern=tsv_path,
text_preprocessor=[
functools.partial(
preprocessors.parse_tsv,
field_names=["inputs", "targets"]),
],
output_features=DEFAULT_OUTPUT_FEATURES,
metric_fns=[bleu])fine-tuningモデルの保存にGoogle Cloud Storageを使います。t5-test-modelというバケットを作り、その中のsmallというフォルダにmT5のsmallモデルをコピーしておきます。
from google.colab import auth
auth.authenticate_user()
!gsutil cp gs://t5-data/pretrained_models/mt5/small/checkpoint gs://t5-test-model/small
!gsutil cp gs://t5-data/pretrained_models/mt5/small/model.ckpt-1000000* gs://t5-test-model/small
!gsutil cp gs://t5-data/pretrained_models/mt5/small/operative_config.gin gs://t5-test-model/small学習実行
以下のコマンドで学習が実行されます。
!export PYTHONPATH=${PYTHONPATH}:. && cd multilingual-t5 && \
\
PRE_TRAINED_MODEL_DIR='gs://t5-data/pretrained_models/mt5/small' && \
OPERATIVE_CONFIG=$PRE_TRAINED_MODEL_DIR'/operative_config.gin' && \
FINE_TUNED_MODEL_DIR='gs://t5-test-model/small' && \
FINE_TUNING_BATCH_SIZE=`expr 512 \* 2` && \
PRE_TRAINGING_STEPS=1000000 && \
FINE_TUNING_STEPS=`expr $PRE_TRAINGING_STEPS + 1000` && \
INPUT_SEQ_LEN=128 &&\
TARGET_SEQ_LEN=128 &&\
\
echo "OPERATIVE_CONFIG=$OPERATIVE_CONFIG" &&\
echo "FINE_TUNED_MODEL_DIR=$FINE_TUNED_MODEL_DIR" &&\
echo "FINE_TUNING_BATCH_SIZE=$FINE_TUNING_BATCH_SIZE" &&\
echo "PRE_TRAINGING_STEPS=$PRE_TRAINGING_STEPS" &&\
echo "FINE_TUNING_STEPS=$FINE_TUNING_STEPS" && \
echo "INPUT_SEQ_LEN=$INPUT_SEQ_LEN" && \
echo "TARGET_SEQ_LEN=$TARGET_SEQ_LEN" && \
\
t5_mesh_transformer \
--model_dir="$FINE_TUNED_MODEL_DIR" \
--module_import="t5_chatbot" \
--gin_file="dataset.gin" \
--gin_file="$OPERATIVE_CONFIG" \
--gin_param="run.layout_rules=''" \
--gin_param="run.mesh_shape=''" \
--gin_param="utils.get_variable_dtype.activation_dtype='float32'" \
--gin_param="MIXTURE_NAME = 't5_chatbot'" \
--gin_file="learning_rate_schedules/constant_0_001.gin" \
--gin_param="run.train_steps=$FINE_TUNING_STEPS" \
--gin_param="run.sequence_length = {'inputs': $INPUT_SEQ_LEN, 'targets': $TARGET_SEQ_LEN}" \
--gin_param="run.save_checkpoints_steps=200" \
--gin_param="run.batch_size=('tokens_per_batch', $FINE_TUNING_BATCH_SIZE)"オージス総研様の記事からパラメータを変えているところは、データの文長が比較的長いため、INPUT_SEQ_LENを128トークンにしているところと、それに合わせてバッチサイズを1024にしているところ、そしてデータ数が記事で扱っている優しい日本語データより少ないので、学習ステップ数を1000に減らしています。加えて多言語版を扱う上で、multilingual-t5ディレクトリ上で実行する必要があります。
Google Colaboratoryで割り当てられるGPUはランダムなのですが、私の場合1ステップあたり4〜5秒程かかり、1000ステップ学習するのには前処理の時間なども含めて1.5時間ほどかかりました。(何が割り当てられたかをきちんとメモするのを失念しておりましたがおそらくTesla T4だったと思います)
テスト
テスト用にとっておいたデータのカスタマーの発話部分だけをinputs.txtというテキストファイルでテスト用に保存します。この文章は学習データには入っていないので、学習したモデルを使ってどのような出力が得られるかテストしてみます。
!export PYTHONPATH=${PYTHONPATH}:. && cd multilingual-t5 && \
\
FINE_TUNED_MODEL_DIR='gs://t5-test-model/small' && \
OPERATIVE_CONFIG=$FINE_TUNED_MODEL_DIR'/operative_config.gin' && \
\
echo "OPERATIVE_CONFIG=$OPERATIVE_CONFIG" &&\
echo "FINE_TUNED_MODEL_DIR=$FINE_TUNED_MODEL_DIR" &&\
\
t5_mesh_transformer \
--model_dir="$FINE_TUNED_MODEL_DIR" \
--module_import="t5_chatbot" \
--gin_file="$OPERATIVE_CONFIG" \
--gin_param="run.layout_rules=''" \
--gin_param="run.mesh_shape=''" \
--gin_file="infer.gin" \
--gin_file="beam_search.gin" \
--gin_param="utils.get_variable_dtype.slice_dtype='float32'" \
--gin_param="utils.get_variable_dtype.activation_dtype='float32'" \
--gin_param="run.batch_size=('tokens_per_batch', 128)" \
--gin_param="infer_checkpoint_step = 1001000" \
--gin_param="input_filename = '/content/inputs.txt'" \
--gin_param="output_filename = '/content/ouputs.txt'"本来であればきちんとvalidationデータを設定して、最適なステップのモデルを選択するべきですが、今回は最終モデル(1000ステップ目)を利用します。
出力されたテキストは以下のようになります

文章として破綻しているものや、Seq2Seqの失敗でありがちな無限ループにはまってしまう問題(現象の名前がわからないのですが、こちらの論文で扱われている問題です)は起こっていないようです。ただし「<MASK>番号はおわかりになりますでしょうか?」や「手配をしますので少々お待ち下さい」にオーバーフィットしている感がありますが、きちんとvalidationを設定すればこれらは回避できるかもしれません。
おわりに
今回はGoogle Colaboratory上のGPUで学習するということもありsmallモデルを利用しましたが、きちんとインスタンスを立ててTPUで学習する場合はより大きなもモデル(130億パラメータのXXLモデルも公開されています!)も使うことができます。
AI ShiftにおけるmT5の活用方法として、少量のデータからの用例ベース対話システムをつくるのに利用できそうかな、と考えています。生成系のタスクにあまり取り組んだことがないので、これから色々いじりながら検討しようと思います。
最後までご覧いただきありがとうございました!




