こんにちは
AIチームの戸田です
今回は以前参加したKaggleのコンペRiiid! Answer Correctness Prediction(以下Riiid)でも利用したBigQueryMLの紹介をさせていただきます。Riiidの振り返り記事はこちらになります。
BigQueryMLとは
BigQueryMLはBigQueryの標準SQLを使って機械学習モデルを学習できる機能です。GCPでWebサービスを運用していると、ログをBigQueryに流すことが多いと思います。ログを学習したモデルを作るために、これまではローカルなどにデータを落として学習したりしていましたが、BigQueryMLを使うと、BigQueryだけで作業を完結することができます。TB級の莫大なデータを扱う際はBigQuery上で処理できるのは非常に嬉しいと思います。
使用出来るモデルはロジスティック回帰のようなシンプルなものからXGBoostのようなTREE系、またTensorFlowのモデルをアップロードして使うこともできるようです。詳細は公式のマニュアルを御覧ください。
多様なモデルが使えることに加えて、標準化やOnehot Encodingなどの入力値の変換も自動で行ってくれるので、SQLさえ書ければほぼOKという、人間の学習コストが低い利点もあります。
実際に使ってみる
Riiidコンペのデータを使って実際にBigQueryMLをつかってみます。
Riiidコンペについて
TOEICの学習アプリのデータを使って、ユーザーが出された問題に正解できるかを、ユーザーの行動履歴(以前どんな問題を解いていて、それに正解したか、など)から予測します。
学習データがなんと1億行もあるため、定番のpandasで読み込んで、scikit-learnのモデルで学習、といったことをすることができません。
他にも提出にAPIをつかったりと、一筋縄では行かない非常に面白いコンペだったのですが、本稿の趣旨と外れてしまうので、詳細を知りたい方は実際のコンペのページをご参照ください。
データのアップロード
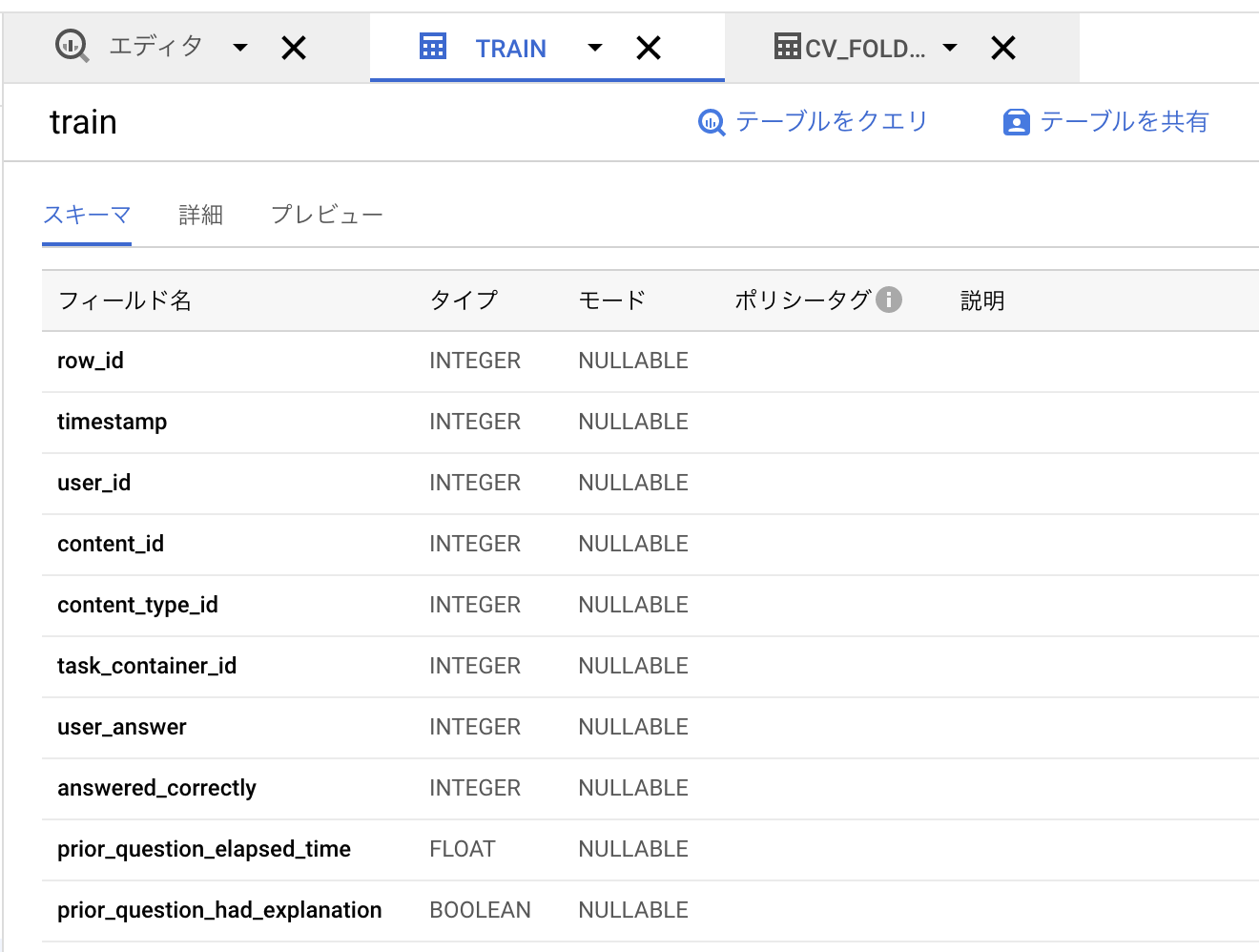
コンペのページの下部にあるDownload AllからデータをダウンロードしてBigQueryにアップロードします。ファイルアップロード方法については公式のドキュメントがわかりやすいと思いますのでご参照ください。
Riiidコンペは時系列を考慮しなければならないため、テストデータの分割にこちらのNotebookの出力ファイルcv_fold_info.csvを使用します。ダウンロードして、train.csvと同様にBigQueryにアップロードします。こちらはtito氏の分割戦略をもとに作成したもので、コンペでも多くの方がこの戦略を利用していました。
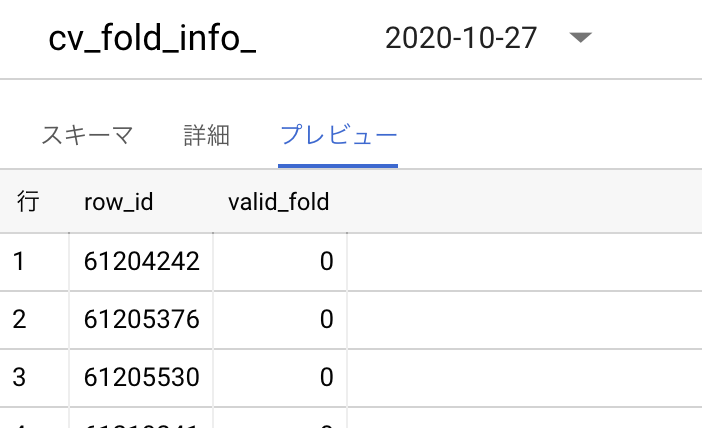
cv_fold_info.csvは以下のように行番号とその行が、3-FoldでCross Validationするうち何Fold目でテストデータとして使われるかの情報がvalid_foldに入っているデータになります。
特徴量作成
標準SQLを使って特徴量を生成します。今回はコンペでも有効だったTarget Encodingの特徴量を作ろうと思います。目的変数は出された問題に答えられたかどうか(間違えた=0 or 答えられた=1)なので、ユーザーの正解率を計算して特徴量とすることにしました。
実際に実行したSQLは以下になります。
-- テーブル作成
CREATE TABLE Kaggle_Riiid.t_feat_window_100to500 AS
--
SELECT
row_id,
IFNULL(LAG (work_sum_all, 1) OVER (PARTITION BY user_id ORDER BY row_id), 0) AS work_sum_all,
IFNULL(LAG (rate_sum_w100, 1) OVER (PARTITION BY user_id ORDER BY row_id), 0) AS rate_sum_w100,
IFNULL(LAG (rate_sum_w200, 1) OVER (PARTITION BY user_id ORDER BY row_id), 0) AS rate_sum_w200,
IFNULL(LAG (rate_sum_w300, 1) OVER (PARTITION BY user_id ORDER BY row_id), 0) AS rate_sum_w300,
IFNULL(LAG (rate_sum_w400, 1) OVER (PARTITION BY user_id ORDER BY row_id), 0) AS rate_sum_w400,
IFNULL(LAG (rate_sum_w500, 1) OVER (PARTITION BY user_id ORDER BY row_id), 0) AS rate_sum_w500,
FROM(
-- 各時間窓での正解率を求める(データが窓幅に足りていない場合は0)
SELECT
*,
CASE WHEN work_sum_all>100 THEN correct_sum_w100/100 ELSE 0 END AS rate_sum_w100,
CASE WHEN work_sum_all>200 THEN correct_sum_w200/200 ELSE 0 END AS rate_sum_w200,
CASE WHEN work_sum_all>300 THEN correct_sum_w300/300 ELSE 0 END AS rate_sum_w300,
CASE WHEN work_sum_all>400 THEN correct_sum_w400/400 ELSE 0 END AS rate_sum_w400,
CASE WHEN work_sum_all>500 THEN correct_sum_w500/500 ELSE 0 END AS rate_sum_w500,
FROM (
-- 時間窓ごとの正解数を求める
SELECT
row_id,
user_id,
COUNT(answered_correctly) OVER (PARTITION BY user_id ORDER BY row_id) AS work_sum_all,
SUM(CASE WHEN answered_correctly=1 THEN 1 ELSE 0 END) OVER (PARTITION BY user_id ORDER BY row_id RANGE BETWEEN 100 PRECEDING AND CURRENT ROW) AS correct_sum_w100,
SUM(CASE WHEN answered_correctly=1 THEN 1 ELSE 0 END) OVER (PARTITION BY user_id ORDER BY row_id RANGE BETWEEN 200 PRECEDING AND CURRENT ROW) AS correct_sum_w200,
SUM(CASE WHEN answered_correctly=1 THEN 1 ELSE 0 END) OVER (PARTITION BY user_id ORDER BY row_id RANGE BETWEEN 300 PRECEDING AND CURRENT ROW) AS correct_sum_w300,
SUM(CASE WHEN answered_correctly=1 THEN 1 ELSE 0 END) OVER (PARTITION BY user_id ORDER BY row_id RANGE BETWEEN 400 PRECEDING AND CURRENT ROW) AS correct_sum_w400,
SUM(CASE WHEN answered_correctly=1 THEN 1 ELSE 0 END) OVER (PARTITION BY user_id ORDER BY row_id RANGE BETWEEN 500 PRECEDING AND CURRENT ROW) AS correct_sum_w500,
FROM Kaggle_Riiid.train
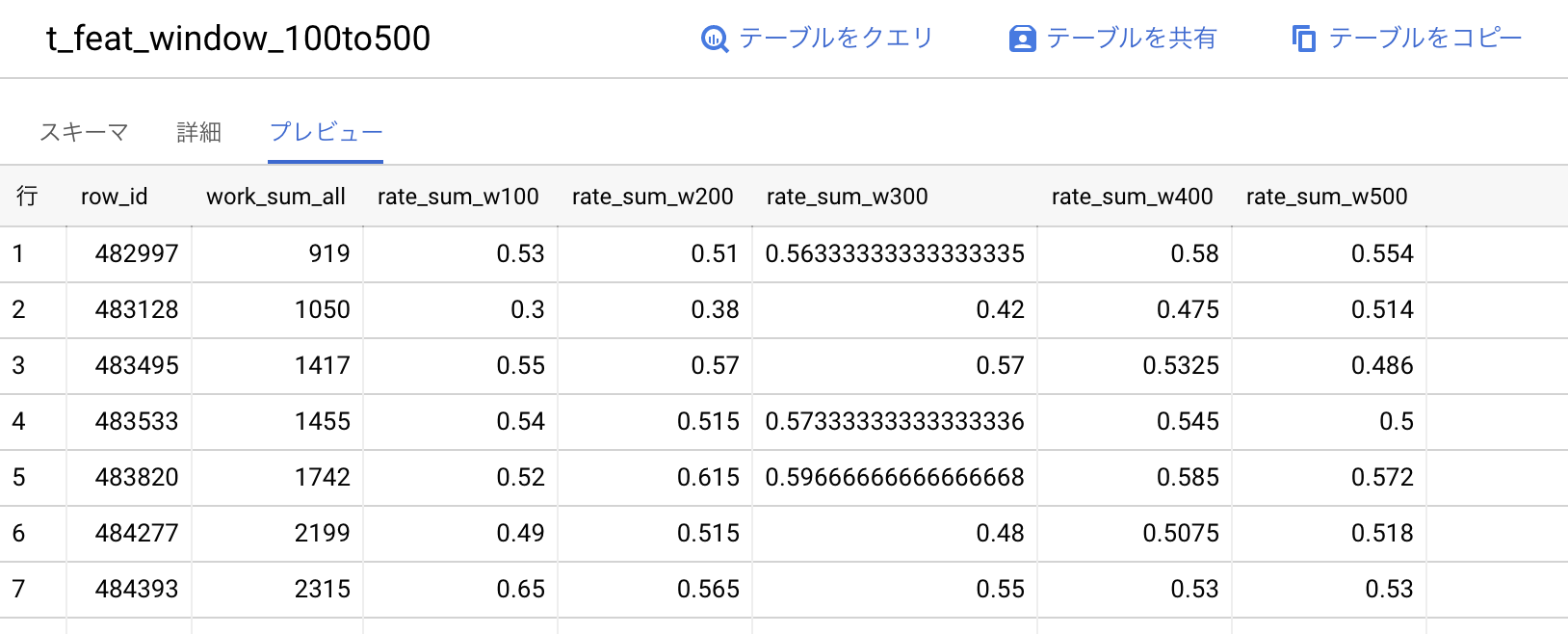
))Kaggle_Riiidというデータセットにt_feat_window_100to500という名前でテーブルを作りました。作成されたカラムは時間窓ごとの移動平均(100〜500で100ステップ)、つまり直近の問題N問の正解率rate_sum_wNとそれまでに解いた問題数work_sum_allの計6個です。
学習
いよいよBigQueryMLを使った学習を行います。特徴量が5つしか無いのでシンプルな学習器でも良さそうですが、せっかくなのでKaggleで良く使われるXGBoostを使ってみます。学習に実行するSQLは以下のようになります。
CREATE MODEL Kaggle_Riiid.xgb_test_01
-- モデルの設定
OPTIONS(MODEL_TYPE='BOOSTED_TREE_CLASSIFIER',
BOOSTER_TYPE = 'GBTREE',
NUM_PARALLEL_TREE = 1,
MAX_ITERATIONS = 1000, -- early stoppingがあるので多めに設定
TREE_METHOD = 'HIST',
EARLY_STOP = True,
MIN_REL_PROGRESS=0.0001,
LEARN_RATE = 0.1,
INPUT_LABEL_COLS = ['answered_correctly'], -- 目的変数のカラムを設定
DATA_SPLIT_METHOD='CUSTOM', -- データ分割方法
DATA_SPLIT_COL='is_test' -- データ分割カラムを設定
)
AS
-- 学習するテーブルを作成する
SELECT
-- 特徴量
work_sum_all,
rate_sum_w100,
rate_sum_w200,
rate_sum_w300,
rate_sum_w400,
rate_sum_w500,
-- 目的変数
answered_correctly,
-- テストデータ分割用カラム
valid_fold = 0 AS is_test,
FROM Kaggle_Riiid.cv_fold_info_20201027
INNER JOIN Kaggle_Riiid.train USING (row_id)
LEFT JOIN Kaggle_Riiid.t_feat_window_100to500 USING (row_id)特殊なカラムが2個あります
- INPUT_LABEL_COLS: 目的変数のカラム
- DATA_SPLIT_COL: テスト用のデータ分割のカラム
以上2個以外は全て特徴量として利用されるので、使用するカラムはSQLのSELECT文などで調整します。ちなみにテスト用のデータ分割はカラムを指定しなくても、ランダム分割のようなシンプルな戦略であればDATA_SPLIT_METHODで指定することができます。
ハイパーパラメータは学習率とearly_stoppingだけ設定していますが、実際はもっと細かく設定することができます。DARTなども設定できるので、ほぼPythonで使うXGBoostと同じなのではないでしょうか。パラメータの詳細について、XGBoost以外の学習器のものも含めて公式のドキュメントで全て確認出来ます。
結果
学習結果もBigQueryのコンソール上で確認することが出来ます。
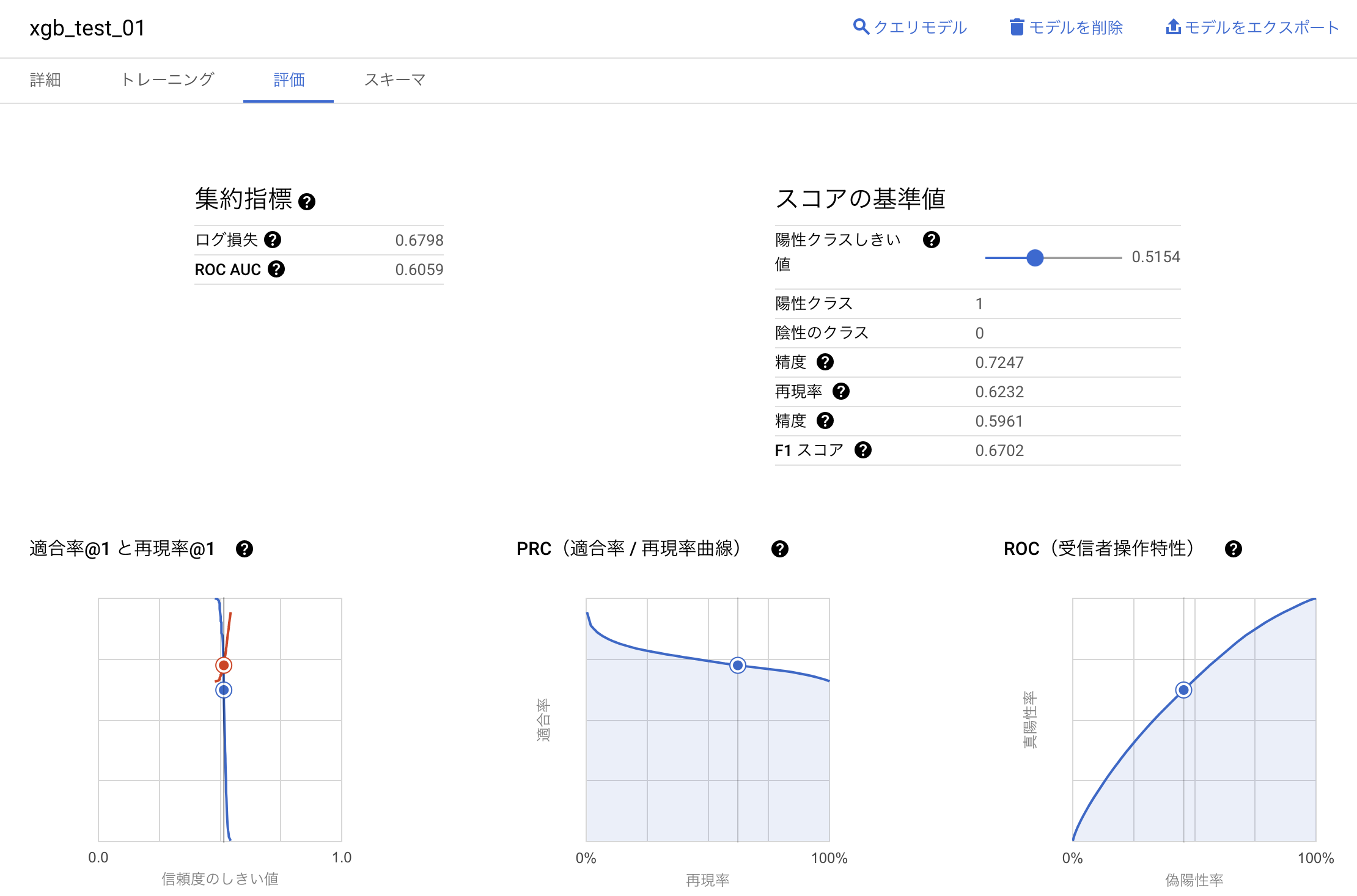
Web UIで陽性クラス閾値を動かして再現率や適合率といった評価指標の変化も見ることが出来ます。
今回のモデルはlog lossが0.6798、ROC AUCが0.6059となりました。あまり良い結果とは言えませんが、本記事のテーマがはBigQueryMLのを使ったモデルの作成なので、精度向上に関しては扱わないこととします。
デプロイ
実際にモデルをデプロイするために、学習したモデルをエクスポートします。
メニューバーに「モデルをエクスポート」という項目があるので、それをクリックしてGoogle Cloud Storageの任意の場所にモデルをエクスポートします。
エクスポートされたモデルをダウンロードすると、以下のようなファイル構成になっています。
xgb_test_01/
├── assets
│ └── model_metadata.json
├── main.py
├── model.bst
└── xgboost_predictor-0.1.tar.gzまずはxgboost_predictor-0.1.tar.gzを解凍して推論に必要なモジュールを配置します。
第一引数にjsonリストを文字列で与えてmain.pyを実行することで予測を行う事ができます。
$ python main.py '[{"rate_sum_w100": 0.49, "rate_sum_w200": 0.485, "rate_sum_w300": 0.47333333333333333, "rate_sum_w400": 0.465, "rate_sum_w500": 0.474, "work_sum_all": 500}, {"rate_sum_w100": 0.52, "rate_sum_w200": 0.5, "rate_sum_w300": 0.5, "rate_sum_w400": 0.49, "rate_sum_w500": 0.5, "work_sum_all": 1000}, {"rate_sum_w100": 0.44, "rate_sum_w200": 0.455, "rate_sum_w300": 0.45, "rate_sum_w400": 0.4725, "rate_sum_w500": 0.47, "work_sum_all": 5000}]'
[09:54:25] WARNING: /Users/travis/build/dmlc/xgboost/src/learner.cc:790: Loading model from XGBoost < 1.0.0, consider saving it again for improved compatibility
[{'predicted_answered_correctly': '1', 'answered_correctly_values': ['1', '0'], 'answered_correctly_probs': [0.5057607293128967, 0.49423927068710327]}, {'predicted_answered_correctly': '1', 'answered_correctly_values': ['1', '0'], 'answered_correctly_probs': [0.5057607293128967, 0.49423927068710327]}, {'predicted_answered_correctly': '1', 'answered_correctly_values': ['1', '0'], 'answered_correctly_probs': [0.5003229379653931, 0.49967703223228455]}]結果も同様にjsonリストで返ってきます。
推論コードもモデルと一緒にエクスポートしてもらえるので、CloudRunなどで簡単にデプロイできると思います。(本記事ではCloudRunでのデプロイまでは扱いませんので、詳細は公式ドキュメントを御覧ください)
ちなみに今回の入力値は以下のコードで疑似的に作りました。
import json
import numpy as np
import pandas as pd
def generate_dummy_data(n_data):
correct = np.random.randint(0, 2, n_data)
lst = [
pd.DataFrame(correct).rolling(100).mean().values[-1][0],
pd.DataFrame(correct).rolling(200).mean().values[-1][0],
pd.DataFrame(correct).rolling(300).mean().values[-1][0],
pd.DataFrame(correct).rolling(400).mean().values[-1][0],
pd.DataFrame(correct).rolling(500).mean().values[-1][0]
]
d = {f"rate_sum_w{(i+1)*100}": v for i, v in enumerate(lst)}
d["work_sum_all"] = n_data
return d
dummy = [
generate_dummy_data(500),
generate_dummy_data(1000),
generate_dummy_data(5000)
]
json.dumps(dummy)なお、model.bstはpythonのxgboostライブラリで読み込むことができるので、Feature Importanceなどを確認することもできます。
import xgboost as xgb
from matplotlib import pyplot as plt
# エクスポートしたモデルのディレクトリ上で実行する
from predictor import Predictor
predictor = Predictor.from_path('./')
predictor._extract_model_metadata()
mapper = {'f{0}'.format(i): v for i, v in enumerate(predictor._feature_names)}
mapped_gain = {mapper[k]: v for k, v in predictor._model.get_score(importance_type="gain").items()}
_, ax = plt.subplots(figsize=(8, 6))
xgb.plot_importance(mapped_gain, ax=ax, show_values=True)
plt.show()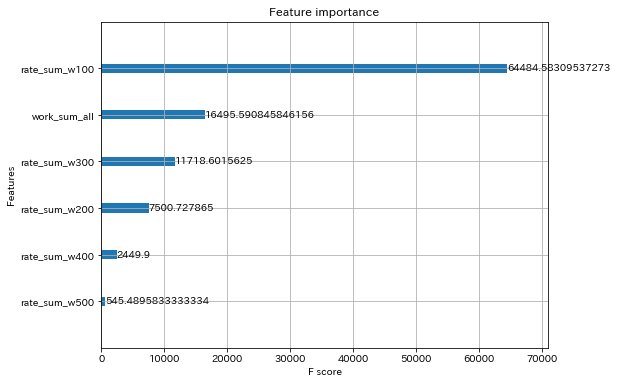
おわりに
以前参加したKaggleのコンペRiiidのデータを使って、BigQueryMLの学習方法の紹介をさせていただきました。
SQLのみでスピーディに学習でき、デプロイも簡単そうでした。可視化・分析はTableauなどのBIツールがありますし、将来的にMLプロダクトでコードを書く機会はなくなるかもしれません。
今回のような教師あり学習の他にもクラスタリングやレコメンドといった教師なし学習やAutoMLを使うこともできるよう(使用できるリージョンに制限あり)なので、また色々試してみたいです。
最後までご覧いただきありがとうございました!




