こんにちは
AIチームの戸田です
本記事では先日終了しました、KaggleのコンペRainforest Connection Species Audio Detectionのふりかえりを行いたいと思います。
コンペ概要
コンペの名前の通り、熱帯雨林で録音された音声から鳴いている鳥やカエルの種類を推定する音声処理タスクとなっています。1つの音声ファイルは60秒で、その中には複数の種類が存在するためマルチラベル問題になります。スコアはlabel-weighted label-ranking average precision(LWLRAP)で評価されます。
キーポイント
今回のコンペで難しかったのは、与えられた学習データのラベルが完全ではないということです。
主催者の投稿から、与えられた学習データはまず初歩的な学習アルゴリズムに通して音声データ内の種を予測し、その予測結果を専門家が確認してラベル付けがされていることがわかりました。

したがって最初の初歩的なアルゴリズムが見逃した場合、学習データでは明確にラベル付けされてないけどその種が鳴いている、というケースが想定されます。
実際にこちらのDiscussionでそういった例が挙げられてました。
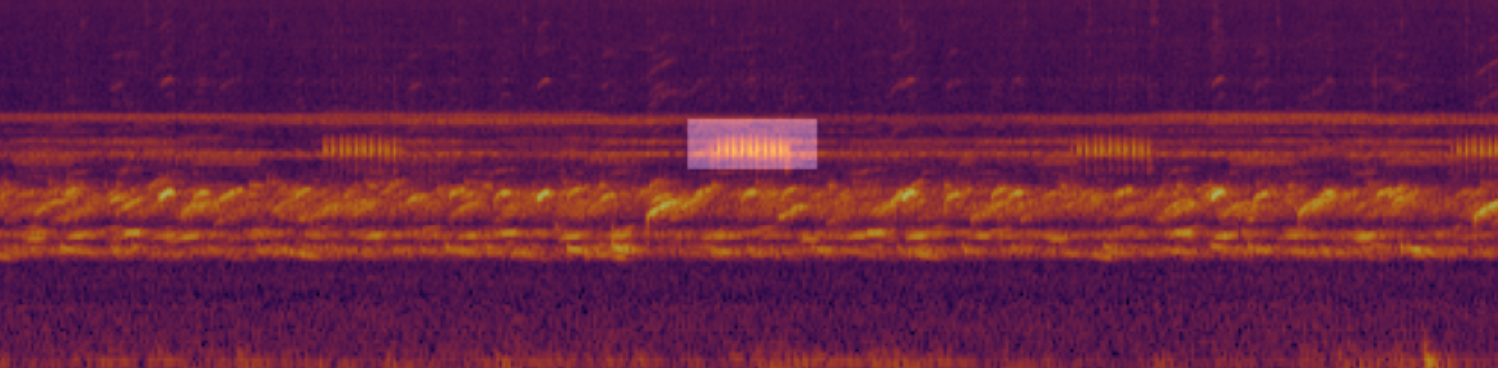
上記例だと白いboxで強調されている部分が、実際に学習データとして与えられているラベルなのですが、スペクトログラム画像を見た感じ、前後にも似たような波形があるため、実際はそこでも対象の種が鳴いていることが想定できます。
一方テストデータは最初から専門家が確認してラベル付けを行うため、上記のようなラベルの欠損は起こりづらいと考えられます。したがって、学習時にこのギャップを埋めてあげる必要があります。
ちなみに初歩的なアルゴリズムに種が存在する、と予測されたけど専門家によって否定されたFalse Positiveのデータも学習用データとして配布されます。そしてそのデータ量はTrue Positiveの1132件に対して約4倍の3958件もあります。そこにその種が存在しない、という情報なので扱いが難しいですが、このデータをいかに活用するかが大事な戦略になると思います。
加えて、与えられた学習データのラベルが何の種類なのかが隠されています。雑音や虫の音、さらには今回のコンペの予測対象外の鳥の声も多く含まれているので、下手に外部データを使ってブーストしてしまうと、誤った種を学習してしまう恐れがあります。これは今回のコンペの目的として希少種への適用があり、限られた学習データ、加えてノイズの多い環境での高精度な種の検出をおこなう手法が求められていたことから、このような問題設定になったのだと思います。
チームでの参戦
今回はチームで取り組ませていただきました。もともとプライベートで繋がりのあったkutoさんと2人で取り組んでいたのですが、Public Gold圏に入って0.95あたりをウロウロしていたところ、Grand MasterのAhmet氏からお声がけいただき、最終的に3人のチームで参加させていただきました。
チーム名がbirdcall revengeとなっているのは以前のCornell Birdcall Identificationのリベンジという意味合いです。(前回はメダル圏外でした...)
解法
最終モデルは3人全員のBESTモデルのアンサンブルでしたが、各々の学習の基本戦略はほぼ同じです。
1st stage: pre-train
このstageでの目標はImageNetで学習されたベースモデルのパラメータをスペクトログラムに寄せることです。ただしこれは必ずしも必須というわけではないようで、チームメンバーのAhmet氏はここをスキップしていました。
学習するモデルはこちらのDiscussionでも紹介されているSound Event Detection(SED)モデルで、私はベースにResNet18を使用しました。clip-wiseで学習してframe-wiseで予測するのが今回のコンペでは効くようだったので私もそれに習いました。
学習は与えられた音声データをスペクトログラムの画像として扱い、train_tp.csvのラベルを学習します。スペクトログラムはTheo Viel氏の上げてくれたデータセットを利用しました。これは128×3751の画像としてみなすことができます。
細かい工夫として、スペクトログラム画像を実際の音声波形付近で128×512で切り取ることと、train_fp.csvのデータをepoch毎に30件ずつサンプリングしていることがあります。前者は効率よくTrue Positiveラベルを学習させるため、後者は単純な計算量削減が目的でした。(本当はすべて学習させたかったのですが、google colaboratoryで参戦してたので...)
以降の2nd stage, 3rd stageでは、初めにここで学習した重みを読み込んで、学習率を下げてfine-tuningするようなイメージで学習します。
2nd stage: 明確なラベルのみ学習する
上記キーポイントで説明したとおり、今回のコンペでは実際に対象の種が鳴いていてもラベル付けされてないケースが存在するという問題があります。この問題に対処するため、明確にラベル付けされていないlossの勾配を計算しない、という方法をとりました。
True Positiveのラベルを1、False Positiveのラベルを-1、それ以外を0として、BCE Lossをベースに以下のような損失関数を定義しました。
def rfcx_2ndd_criterion(outputs, targets):
posi_label = (targets == 1).float().to(device) # train_tp.csvのラベル
nega_label = (targets == -1).float().to(device) # train_fp.csvのラベル
posi_y = torch.ones(clipwise_preds_att_ti.shape).to(device) # Positiveラベル
nega_y = torch.zeros(clipwise_preds_att_ti.shape).to(device) # Negativeラベル
# loss計算. reduction="none"で各次元のlossをまとめないようにする
posi_loss = nn.BCEWithLogitsLoss(reduction="none")(clipwise_preds_att_ti, posi_y)
nega_loss = nn.BCEWithLogitsLoss(reduction="none")(clipwise_preds_att_ti, nega_y)
# 明確にラベル付けされているlossだけマスキング
posi_loss = (posi_loss * posi_label).sum()
nega_loss = (nega_loss * nega_label).sum()
loss = posi_loss + nega_loss
return loss
こちらのアイディアはKaggleGrandMasterのCPMP氏の以前のコンペのSolutionから拝借しました。
3rd stage: re-labelingして学習
最後の3rd stageでは2nd stageで学習したモデルを使って、初歩的なアルゴリズムが見逃したラベルを予測し、re-labelingして再度1st stageの重みからfine-tuningします。
re-labelingはSlideWindowで切り出した画像patchに対して行います。Windowを512 pixelに設定し、重要な音が分割の境界に位置している可能性があることを考慮して、49 pixelずつカバーして、60秒の音声を8つに分割します。
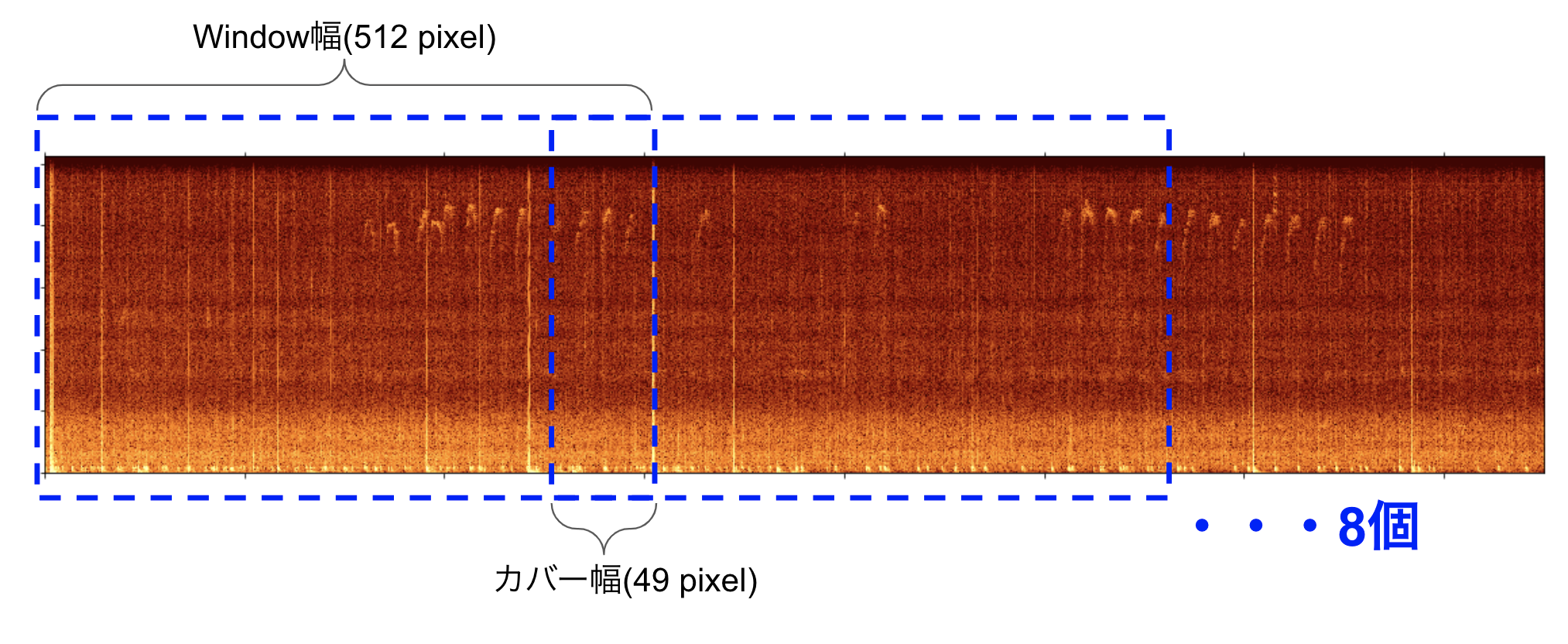
位置を生成するコードは以下のようになります
N_SPLIT_IMG = 8
WINDOW = 512
COVER = 49
slide_img_pos = [[0, WINDOW]]
for idx in range(1, N_SPLIT_IMG):
h, t = slide_img_pos[idx-1][0], slide_img_pos[idx-1][1]
h = t - COVER
t = h + WINDOW
slide_img_pos.append([h, t])
print(slide_img_pos)
# [[0, 512], [463, 975], [926, 1438], [1389, 1901], [1852, 2364], [2315, 2827], [2778, 3290], [3241, 3753]]この画像patch毎に欠損しているラベルを予測し、Sigmoidを通した予測値が0.5以上のものをSoft True Positiveとしてラベルに追加しました。なお、予測値はチーム全員の2nd stageのモデルの予測平均をとることでロバストさを確保しました。
re-labelingしたデータの学習は、基本的に2nd stageと同様ですが、こちらのブログを参考に最終層でのmixupを追加し、re-labelingによって追加されたSoft True Positiveのlossに0.5の重みを付けました。
予測
予測もre-labeling時と同様にSlidingWindow毎に行い、各画像patchの予測値の最大プーリングを取ります。
Kaggle定番手法のTTAなどは効かなかったのですが、ちょっとした工夫としてSliding Windowのカバーpixelを256に拡大しました。ここに関してはきちんと検証できていないのですが、こちらの方が漏れがなさそうですし、re-labelingのときもこの戦略で行っておけばもう少しスコアも上がったのかな、と思っています。
CV
iterative-stratificationのMultilabelStratifiedKFoldを利用しました。評価指標として
- 元のラベルのLWLRAP
- re-labelingされたLWLRAP
- AUC
- 閾値0.5のときのPrecision / Recall
など、色々検討していたのですが、どうもLBと相関が取れず、あまり良くないと思いながらも基本的にはTrust LBでした。
各stageのスコアは以下のようになります。
| stage | CV | Public | Private |
|---|---|---|---|
| 1st | 0.7889 | 0.842 | 0.865 |
| 2nd | 0.7766 | 0.874 | 0.878 |
| 3rd | 0.7887 | 0.949 | 0.951 |
なお、3rd stageのre-labelingされたもののスコアは0.9621でした。
結果
最終的なSubmissionファイルは
- 私のResNet18
- kutoさんのEfficientNet-b2
- Ahmet氏のViT, WaveNet
をベースとしたモデルのアンサンブル(加重平均)でした。
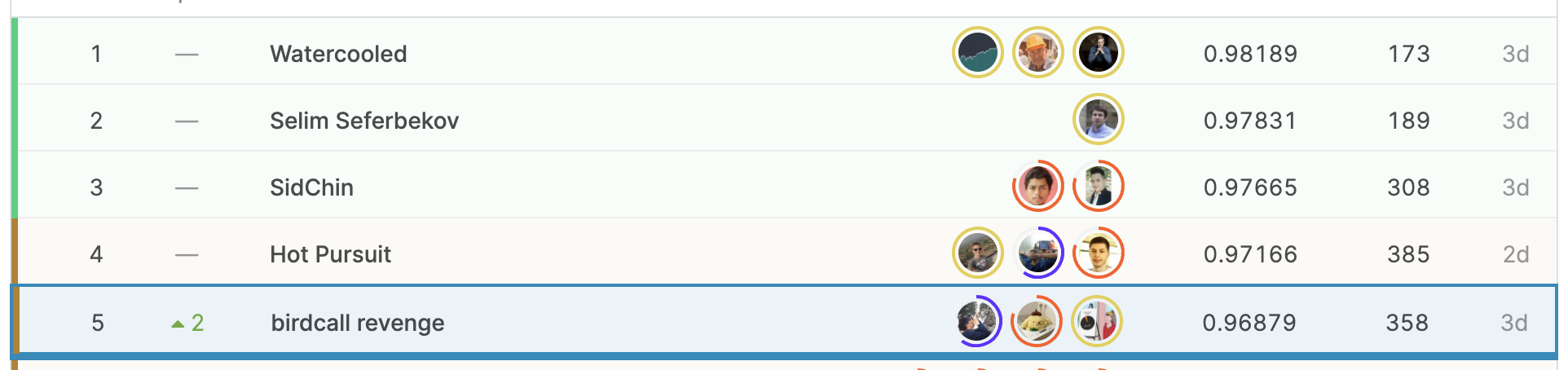
最後までLB/CVの相関が取れなかったのが怖かったですが、結果としてはPublic 8th → Private 5 thで見事金メダルを取得し、チーム名のBirdCallコンペのリベンジを果たすことが出来ました!!
おわりに
Deep Learningの発展で、画像認識や音声認識の精度は格段に向上して来ましたが、それらは認識対象ごとにきちんとラベル付けされた大量のデータありきだと思います。限られたデータ量かつアノテーションも完全ではないという問題設定は賛否両論あると思いますが、(分野はNLPですが)我々の業務でもよく見られるため、それに適用するモデルを作るのは、個人的にはDeep Learningを活用していく中で非常に価値のあるものだったのではないかなと思います。
5位という成績で終えることが出来ましたが、まだDiscussionに投稿された上位Solutionを追えていないので、これからしっかり復習していきたいと思います。
最後までお読みいただきありがとうございました!
参考
- Rainforest Connection Species Audio Detection
- コンペティションの概要ページです
- Rainforest Connection Species Audio Detection 5 th Place Solution (Training Strategy)
- コンペのDiscussionに学習パラメータなどの詳細を乗せたSolutionを上げていますので、もし気になる方がいましたらこちらを御覧ください。(ご質問等もこちらでしていただければと思います。)
- 思考の本棚 鳥蛙コンペの振り返り
- チームメンバーのkutoさんのソリューションです
- loss関数など、モデルが若干私と異なります
- 【Kaggleコンペふりかえり】Cornell Birdcall Identification
- 私が書いたものになりますが、今回のコンペと類似したKaggleコンペの振り返り記事になります。




