こんにちは
AIチームの戸田です
今回は異常検知アルゴリズムを用いたテキストノイズ抽出を試してみたいと思います。
自然言語処理を行う際に必ずと言っていいほど直面する問題の一つがテキストのノイズです。特に実環境で動いているプロダクトのログデータを扱う際は、「あああああああ」のような無意味な文字列や「よろしくお願いします」のようなタスクと関係の無い一般的な文章など多種多様なノイズが存在するため、これらを除去しなければなりません。
今回紹介する手法をきっかけはこちらのブログで、簡単に手法を説明すると、GloVeとTF-IDFから得られたベクトルをPCAで圧縮し、IsolationForestで異常値を見つける、といったものでした。こちらのブログではNIPS 2015の論文に対して手法を適用してい概ね良い結果を収めています。本記事では日本語のカスタマーサポートのデータに適用し、言語とドメインを変えてもうまくいくのか、手法を紹介しながら確認したいと思います。
データ
データはブログサービスのチャットサポートのデータを利用します。期間は2020年8月の1ヶ月分のデータで、10,558件の対話になります。
元ブログでは単語ベクトル化モデルとしてGloVeを利用しているのですが、GloVeの日本語学習済みモデルがなかったためこちらのWord2Vecモデルを利用します。(単語ベクトル化手法の違いで実験に大きな差はないと考えたため)
テキスト前処理
まずはneologdnを使った正則化を行います。単語分割にはMeCabを利用し、SlothLibのStopWordで不要な単語を除去します。最後に数字をすべて"0"に変換します。
import MeCab
import neologdn
default_t = MeCab.Tagger("-Ochasen")
with open("{SlothLibの日本語StopWord}", "r") as f:
slothlib_stopwords = [line.split("\n")[0] for line in f]
def sep_mecab(text):
wakati = [t for t in default_t.parse(text).split('\n') if t not in ["", "EOS"]]
wakati = [w.split("\t")[0] for w in wakati]
return wakati
def text_preprocessing(text):
texts_norm = neologdn.normalize(texts)
sp_text = sep_mecab(texts_norm)
sp_text = [w for w in sp_text if w not in slothlib_stopwords]
sp_text = ["0" if w.isnumeric() else w for w in sp_text]
return " ".join(sp_text)
# customer_uttrances: チャットサポートのデータから抽出したカスタマーの問い合わせ文リスト
customer_uttrances_processed = []
for text in customer_uttrances:
text = text_preprocessing(text)
customer_uttrances_processed.append(text)テキストノイズ抽出
初めに前処理されたテキストで、TF-IDFのモデルを学習します
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_model = TfidfVectorizer()
tfidf_model.fit(customer_uttrances_processed)
tfidf_feat = tfidf_model.get_feature_names()
tfidf_emb = tfidf_model.transform(customer_uttrances_processed)ダウンロードした学習済みWord2Vecモデルでベクトル化した単語にTF-IDFの重みをかけて、各文章のベクトルを計算していきます。
w2v_model = gensim.models.Word2Vec.load('{ダウンロードしたWord2Vecモデル}')
def get_sent_and_vec(sent, row):
sent_vec = np.zeros(emb_dim)
weight_sum = 0
for word in sent.split():
try:
vec = w2v_model.wv[word]
tfidf_score = tfidf_emb[row, tfidf_feat.index(word)]
sent_vec += (vec * tfidf_score)
weight_sum += tfidf_score
except (KeyError, ValueError):
pass
if weight_sum != 0:
sent_vec /= weight_sum
org_sent = customer_uttrances[row]
return org_sent, sent_vec
org_sents, sent_vecs = [], []
for row, sent in enumerate(customer_uttrances_processed):
org_sent, sent_vec = get_sent_and_vec(sent, row)
org_sents.append(org_sent)
sent_vecs.append(sent_vec)
org_sents = np.array(org_sents)
sent_vecs = np.array(sent_vecs)元のブログでは、GloVe(本記事ではWord2Vec)でベクトル化できない文章は、一般的でない語のみで構成されているといえるので、ノイズであると言える、とあります。上記コードではベクトル化できなかった文書のベクトルはゼロベクトルになるので、それを抽出しました。
抽出されたほとんどの文章はメールアドレスでした。他には「!\n\n\n\n\n\nわ。。、!、!!!」のような意味の無い文章や「おk」のようなスラングが抽出されました。(データ取り扱いの都合上、抽出結果をすべて載せられないのが残念です...)
ゼロ以外のベクトルを抽出し、PCAで2次元に圧縮します。
from sklearn.decomposition import PCA
from matplotlib import pyplot as plt
sent_vecs_no_zero = sent_vecs[(sent_vecs == 0).sum(1) != 300]
pca = PCA(n_components=2)
X = pca.fit_transform(sent_vecs_no_zero)
plt.scatter(X[:, 0], X[:, 1])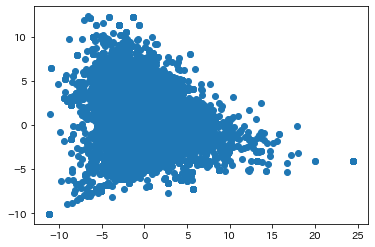
PCAで圧縮された結果をプロットすると上記のようになります。
元のブログでは分布から明らに外れた異常値がありましたが、今回のデータは比較的よくまとまっているように見えます。これはデータにノイズ(異常値)が少なかったとも取れます。
最後にIsolationForestを使ってノイズとなる文章を抽出します。IsolationForestは決定木を使った異常検知アルゴリズムで、 異常値は正常なデータと特徴が大きく異なると仮定し、分類する際の木の深さから異常値を判断します。
from sklearn.ensemble import IsolationForest
IF = IsolationForest(contamination=0.005, behaviour='new')
IF.fit(X)
if_preds = IF.predict(X)
plt.scatter(X[:, 0], X[:, 1], c=if_preds)グラフを見たところ、異常値はかなり少なく見えたので、contamination(異常値の割合)はかなり厳しく設定しました。結果をグラフ上で色分けすると以下のようになります。
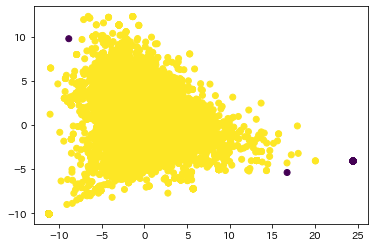
異常値のサンプルを見てみると、「お手数おかけしてすみません」や「なんとかしてください」のようなタスクと関係の無い一般的な文章や「オペレターにひつもする」のような入力ミス(おそらくオペレーターに質問する、と入力したかった)が抽出できました。一方で「退会するには?」のような退会に関する質問もいくつかあり、ノイズではないものも抽出されてしまっていることがわかりました。
おわりに
本記事では文章ベクトルと異常検知アルゴリズムを使ってテキストノイズの抽出を試してみました。想定していたノイズの抽出は確認できましたが、一部ノイズではない文章も抽出されてしまいました。
今回、ノイズではないものが抽出されてしまった原因は2つあると考えています。1つ目はデータが特定のサービスのカスタマーサポートへの問い合わせだったので、似たような文章が多く、文章ベクトルが近い位置に固まってしまったこと、2つ目はチャットボットへの入力という短文が対象だったため、使われている単語の種類が少なかったことが原因だと考えられます。
カスタマーサポートのチャットボットというドメインにおいて、異常検知アルゴリズムを用いたこの手法は効果が小さかったですが、チャットボット回答候補となる用例を作る初期設計の段階で、例えばメールサポートのデータなどに対しては使ってみる価値があるかもしれません。また、手法適用前の前処理的なものになりますが、学習済み単語ベクトル化モデルでベクトル化できない文章は一般的な単語が含まれないのでノイズ、という考え方はシンプルで効果的なノイズ検出手法だったのではないかと思います。
テキストノイズ除去は業務で自然言語処理をやる上で避けては通れない処理なので、今後も色々な手法を試していきたいと思います。
最後までお読みいただきありがとうございました!




