こんにちは
AIチームの戸田です
本記事はAI Shift Advent Calendar 2021の2日目の記事です
今回は、先日終了したNishikaコンペ、小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~ の振り返りを行いたいと思います
コンペ概要
日本最大級の小説投稿サイトである小説家になろうのデータを用いて、ジャンルや作者名などの関連データから各小説のブックマーク数を予測します
目的変数であるブックマーク数は5段階にビニングされ、評価指標はMulti-class loglossで計算されます
詳細はコンペページをご参照いただければと思います
解法
今回のコンペはテキストデータとテーブルデータを扱うマルチモーダルなタスクになります
マルチモーダルタスクはあまり経験がないので、正しいアプローチかはわかりませんが、テキストはBERTにまかせて、初期特徴から自作の特徴量をたくさん作っていく方針で進めていました
特徴量
初期特徴量
配布データには以下の特徴量が含まれています
- general_firstup: 初回掲載日
- title: 小説名
- story: 小説のあらすじ
- keyword: キーワード
- userid: 作者のユーザーID
- writer: 作者名
- biggenre: 大ジャンル
- genre: ジャンル
- novel_type: 連載の場合は1、短編の場合は2
- end: 短編小説と完結済小説は0、連載中は1
- isstop: 長期連載停止中なら1、それ以外は0
- isr15: 登録必須キーワードに「R15」が含まれる場合は1、それ以外は0
- isbl: 登録必須キーワードに「ボーイズラブ」が含まれる場合は1、それ以外は0
- isgl: 登録必須キーワードに「ガールズラブ」が含まれる場合は1、それ以外は0
- iszankoku: 登録必須キーワードに「残酷な描写あり」が含まれる場合は1、それ以外は0
- istensei: 登録必須キーワードに「異世界転生」が含まれる場合は1、それ以外は0
- istenni: 登録必須キーワードに「異世界転移」が含まれる場合は1、それ以外は0
- pc_or_k : 投稿媒体(モバイル端末かPCか)
isr15のようなonehot特徴はそのまま、genreなどのカテゴリ特徴はonehot-encodingして特徴量としました
Keyword
出現頻度50回以上のキーワードをbag-of-words特徴として追加しました。なお、コメディ⇔コメディーのような表記揺れがあったので、編集距離で抽出して統合しています。
分析する中で、キーワードには"夏のホラー2021"や"キネノベ大賞3"のような企画の特徴が入っていることがわかったので、こちらを別途抽出して特徴量としました。
キーワード自体が存在しない(未入力?)データもあったので、kw_is_noneという、キーワードが存在するか否か特徴を追加しました。
日時
初回掲載日を分解して、年・月・曜日・時刻の特徴を作成しました。曜日と時刻は円周上に置いて周期性をもたせます。
今回のデータ特有の時刻特徴として、「小説家になろう」の日付が代わった瞬間に公開する設定ができる自動投稿機能があります。時刻が0時0分のものは自動投稿として扱えると考え、これを特徴量としました。
ユーザー特徴
ユーザーIDを特徴量として使う場合、GBDT系の学習器ではcategoryに指定するだけでよいのですが、ニューラルネットにそのまま入力すると連続値として扱われてしまうので、embeddingしました。
またユーザーごとの特徴量として、投稿数、ジャンルごとの投稿数、初期特徴(isr15など)ごとの累積を計算しました
テキスト特徴
基本的にテキストはBERTに入力し、最終層の平均値を特徴量としています
前処理としては、小説のあらすじにURLが入っているものがいくつかあったので、URLをすべて「URL」という文字列で置換し、抽出したURLのドメインをonehot特徴として追加しました
また、未だに理屈はきちんと理解できていないのですが、以前参加したKaggleのコンペ、Jigsaw Unintended Bias in Toxicity Classificationの1st Solutionのように、genreをメタ文字として追加し、titleの先頭に追加することで精度が向上しました
Target Encoding
今回のタスクの場合、作者や流行りのジャンルなどが予測に役立つと考えたので、以下3種類のTarget Encodingを考えました
- ジャンル
流行りがあると考え、年や年月の期間と一緒にTarget Encodingを行った - 作者
leakしないように過去の情報だけを使う - キーワード
すべての単語に対しては行えないので、kmeansでクラスタリングをし、そのクラスに対してTarget Encodingを行った
これらの特徴が一番精度向上に貢献したと感じています
モデル
モデルはCatBoost, LGBM, ニューラルネット(NN)の3種類を使いましたが、ここでは特に工夫したNNの構造について説明します
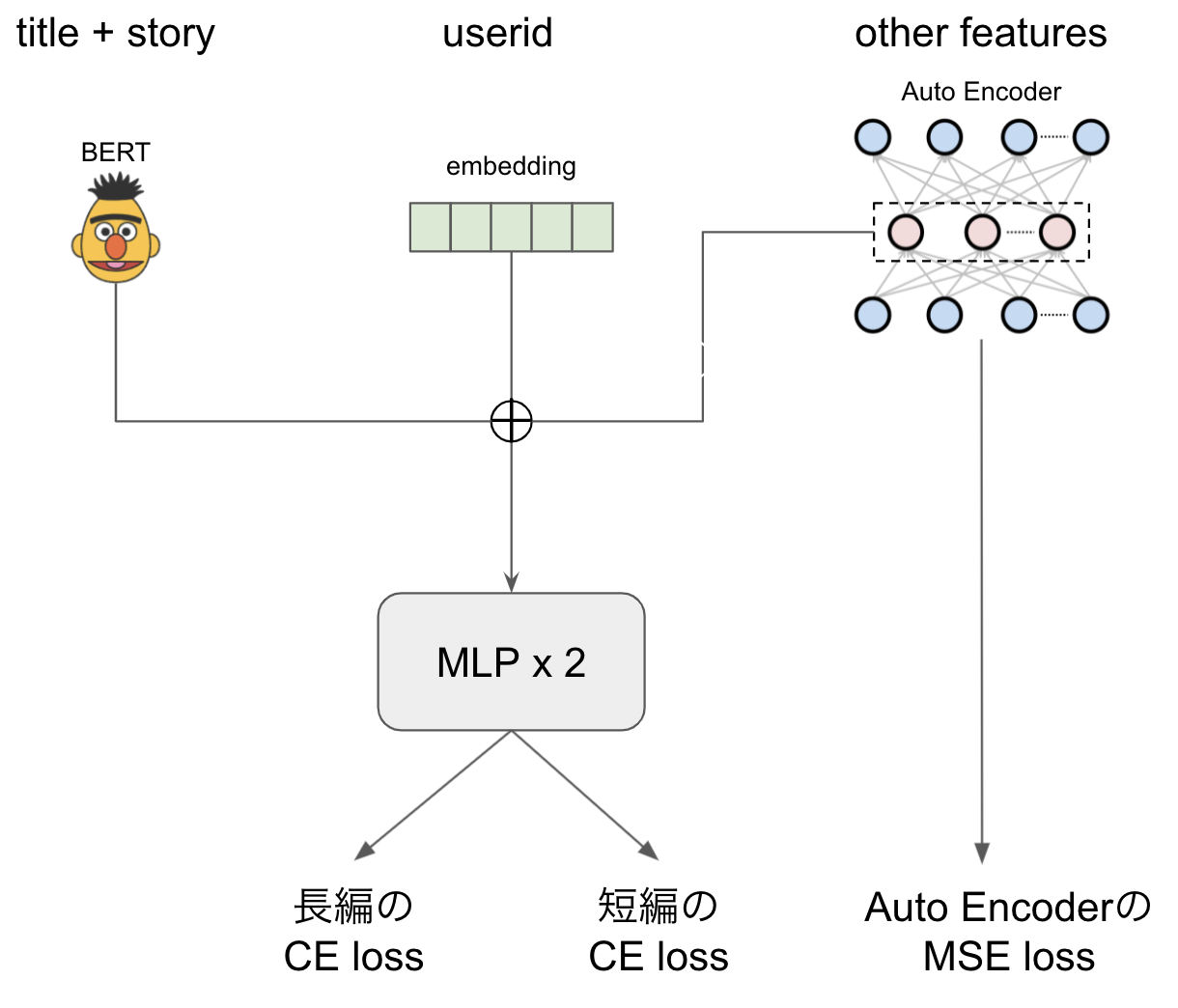
BERTによる文章のベクトル化、useridのembeddingなどは一般的かと思われますが、他の特徴がキーワードのbag-of-wordsなどスパースなものが主だったので、Auto Encoderで圧縮した特徴を利用しました。Auto Encoderはタスクと同時に学習されます。
また、novel_type特徴(長編か短編か)がタスクに大きな影響を与えているようだったので、この2つを分けて計算するようなloss関数を使用しました。実装を以下に示します
def custom_loss_fn(y_pred_1, y_pred_2, mask, y_true):
"""
y_pred_1: 長編headの出力
y_pred_2: 短編headの出力
mask: maskは短編か否か
y_true: 正解ラベル
"""
loss_1 = nn.CrossEntropyLoss(reduction='none')(y_pred_1, y_true)
loss_2 = nn.CrossEntropyLoss(reduction='none')(y_pred_2, y_true)
loss = loss_1 * (1 - mask) + loss_2 * mask
return loss.mean()このモデル単体でも最終スコアを見ると銀メダル圏内だったので、後述のアンサンブルではなく、もう少しNNに拘っても良かったのかな、と考えています
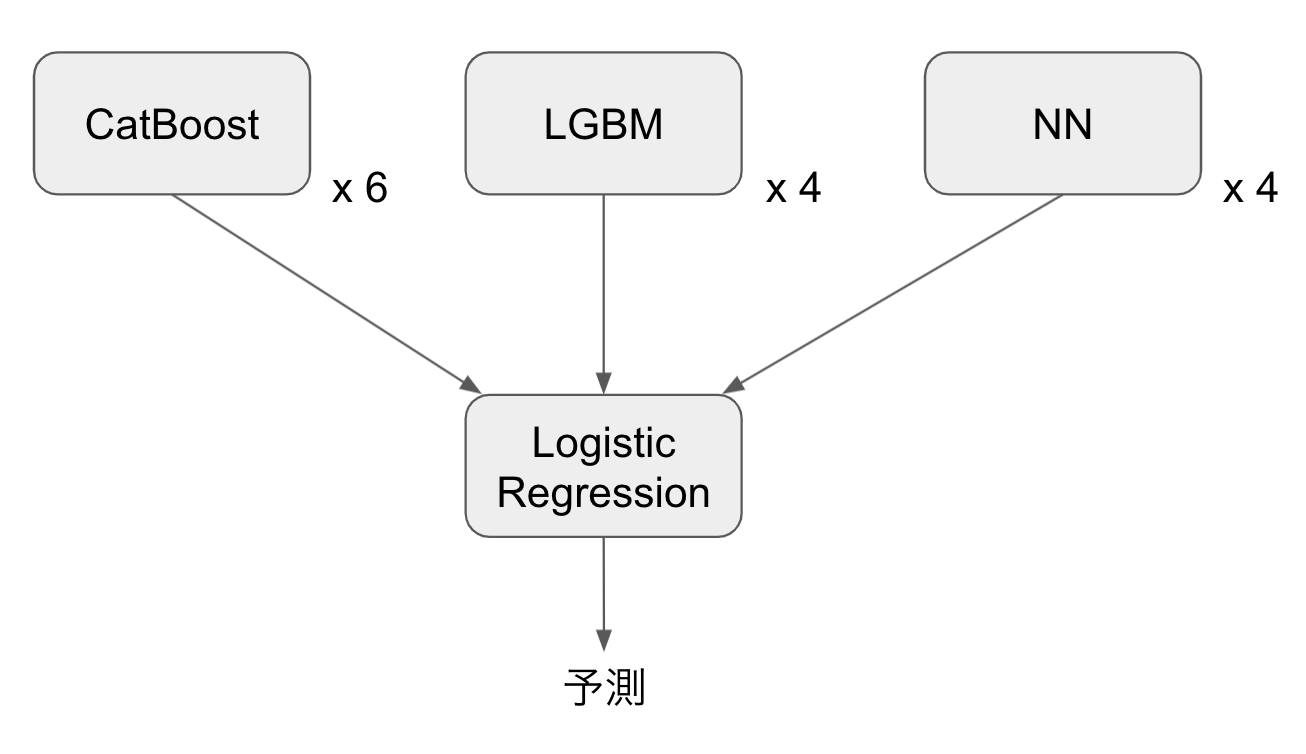
アンサンブル
上記のNNモデルに加えて、CatBoostとLightGBMをパラメータや特徴量などを変えて学習し14個のモデルを作り、最終的にロジスティック回帰でStackingしました
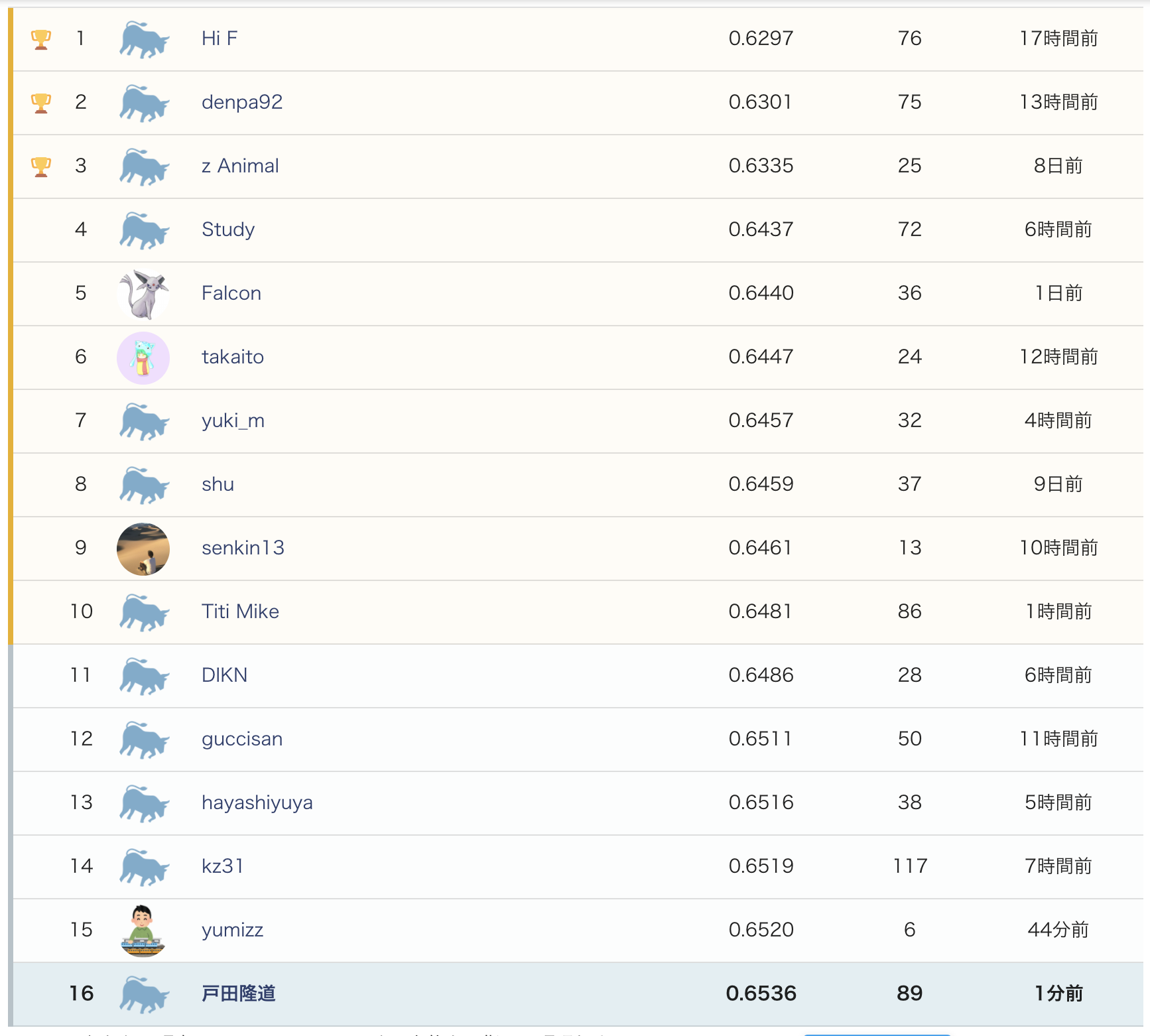
Public Leaderboardは参加者575人中16位でした
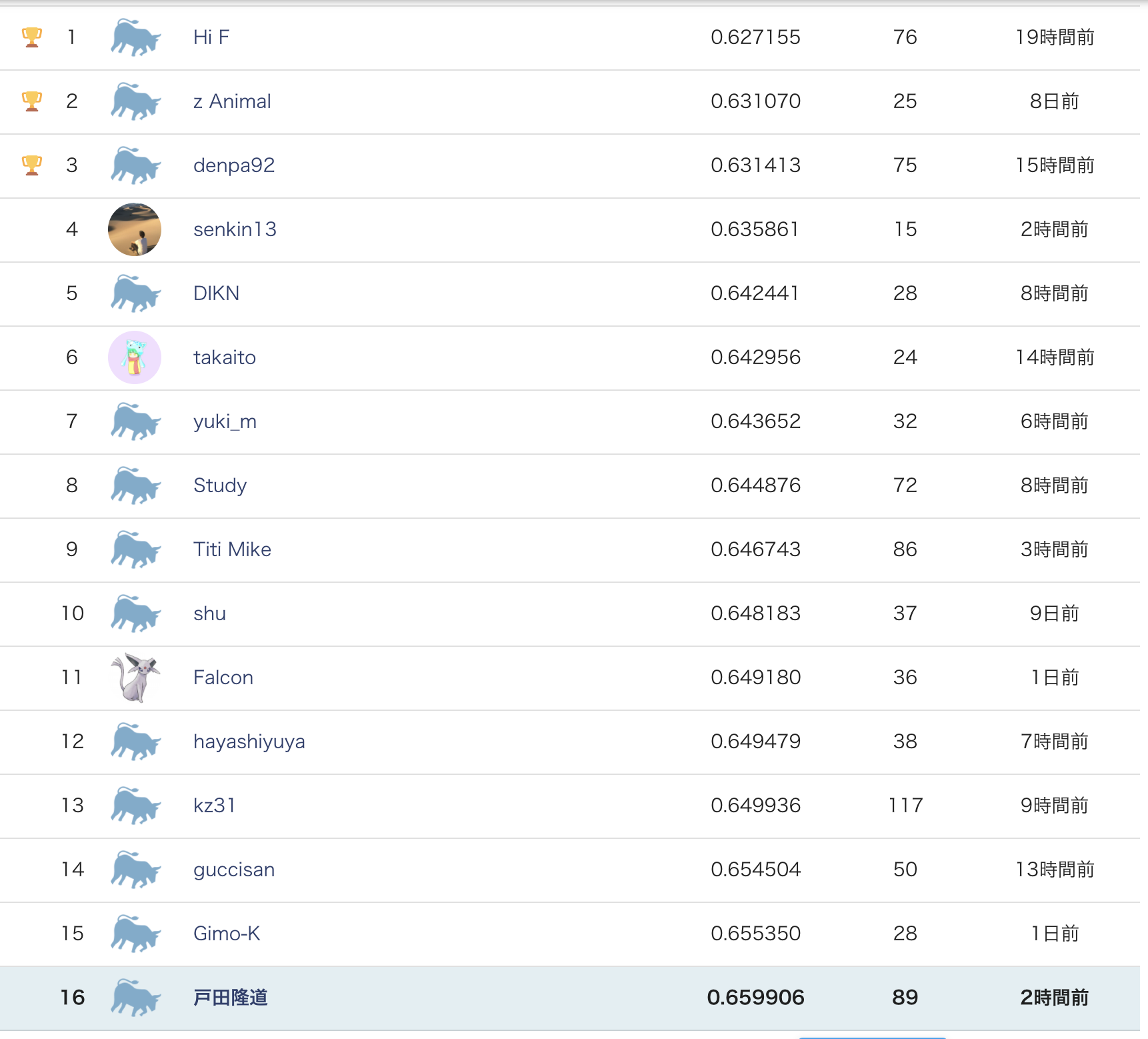
Private Leaderboardも同じく16位のままで、スコアもほとんど変動がなかったです。上位にはいけませんでしたが、安定したモデルが作れたのではないでしょうか。
試したけど上手く行かなかったこと
- 特徴量
- writerの追加
- テストデータに無いカテゴリ98の除外
- 特徴量の正規化
- キーワードのLDA特徴量
- 離散特徴をPCAで圧縮した特徴量
- 複数投稿しているユーザーのwindow特徴
- 投稿日時の差
- NNモデル構造
- skip connect
- カテゴリのembeding
- layerごとのlearning rate設定
- BERTの最終層付近のre-initialize
- BERTの出力として複数層使う
- 損失関数
- focal loss
- loss weight
- label smoothing
- ordered regression
- モデル
- rinnaのRoBERTa
- XGBoost
- その他
- pseudo labeling
- pseudo labelingで Target Encodin
- ノイズデータの除去(例えばN4771GYのデータは小説ではなく、円周率を入稿限界文字数まで書いている)
終わりに
Nishikaコンペに参加したのは初めてでしたが、日本語NLPのマルチモーダルという、Kaggleには無い面白い問題設定のコンペだったので、とても楽しかったです
コンペに使用したコードはGitHubにあげていますので、興味のある方はご参照下さい
今後、入賞者のソリューション発表などがある振り返り会が開催されるようなので、参加してしっかり復習したいと思います
最後までお読みいただきありがとうございました!
明日はTableauに関しての記事が公開される予定です!




