こんにちは、AIチームの東です。
本記事はAI Shift Advent Calendar 2021の4日目の記事です。
今回は、今年のICASSPで発表された音声区間検出の一手法であるMarbleNetについて紹介します。
音声区間検出
音声区間検出(Voice Activity Detection; VAD)とは、音声と音声以外の雑音が含まれる信号から、音声信号が含まれる区間を判別する技術です。音声認識は目的の音声以外の信号の影響を受けやすく、前処理として音声区間のみを音声認識モデルに渡すことで、雑音を音声信号として誤って認識することを防ぐ効果が期待できます。
以前、本ブログで信号パワーと零交差数を用いた音声区間検出とinaSpeechSegmenterによる音声区間検出を取り上げましたが、前者はシンプルで古典的な手法、後者はジェンダー識別を目的とした、CNNベースの軽量な機械学習モデルを用いた手法でした。今回は比較的最近登場した機械学習ベースの手法を試してみます。
MarbleNet
MarbleNetはNVIDIAが開発したNeMoというツールキットに含まれているモデルです。NeMoにはVADだけではなく音声認識や音声合成、自然言語処理など、自動音声対話に関わる様々な学習済みモデルが用意されています。
MarbleNetの元の論文はこちらから読むことができます。
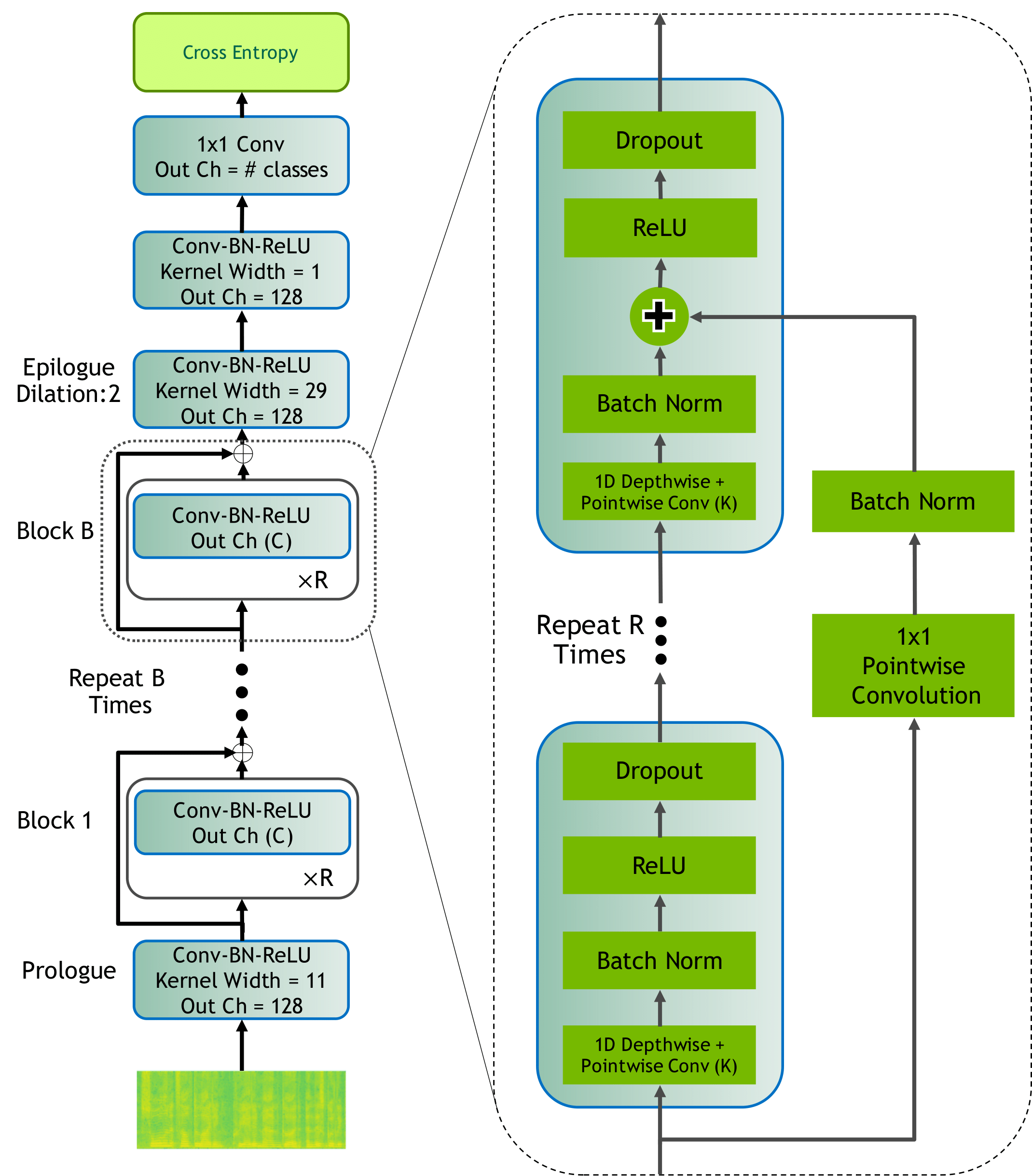
論文によると、当時最先端のモデルと比較して約10分の1のパラメーター数で同等の性能を達成したと報告されています。音声対話システムの前処理として利用するには高速な動作が求められるため、軽量なモデルであることが望ましいでしょう。
モデルの実行手順
それでは実際に、モデルの実行を説明していきます。スクリプトは公式のチュートリアルをベースにし、実行環境はGoogle Colaboratoryを利用します。
まず、以下のコードを実行して必要なライブラリをインストールします。
!pip install wget
!apt-get install sox libsndfile1 ffmpeg portaudio19-dev
!pip install unidecode
!pip install pyaudio
## Install NeMo
BRANCH = 'main'
!python -m pip install git+https://github.com/NVIDIA/NeMo.git@$BRANCH#egg=nemo_toolkit[asr]
## Install TorchAudio
!pip install torchaudio>=0.10.0 -f https://download.pytorch.org/whl/torch_stable.html
!pip install git+git://github.com/ricardodeazambuja/colab_utils.git
!pip install resampy1. 事前準備
次に、使用するライブラリ、定数を設定します。
import numpy as np
import pyaudio as pa
import os, time
import librosa
import IPython.display as ipd
import matplotlib.pyplot as plt
%matplotlib inline
import nemo
import nemo.collections.asr as nemo_asr
from omegaconf import OmegaConf
import copy
# 定数
SAMPLE_RATE = 160002. モデルの設定
今回は提供されている学習済みモデルを利用します。
論文によると、モデルはGoogle Speech Commands Dataset V2とfreesound.orgから取得した雑音データを用いて学習され、AVA speech dataset上で良い性能を発揮しているとのことです。ドメイン外のデータに対しても追加学習なしにある程度の性能が期待できそうです。
vad_model = nemo_asr.models.EncDecClassificationModel.from_pretrained('vad_marblenet')
cfg = copy.deepcopy(vad_model._cfg)
vad_model.preprocessor = vad_model.from_config_dict(cfg.preprocessor)
vad_model.eval()
vad_model = vad_model.to(vad_model.device)3. メイン処理
この学習済みモデルを用いて処理を行います。音声信号を保持するクラスから受け取ったデータをもとに、認識結果を返す関数infer_signal()を定義します。
data_layer = AudioDataLayer(sample_rate=cfg.train_ds.sample_rate)
data_loader = DataLoader(data_layer, batch_size=1, collate_fn=data_layer.collate_fn)
def infer_signal(model, signal):
data_layer.set_signal(signal)
batch = next(iter(data_loader))
audio_signal, audio_signal_len = batch
audio_signal, audio_signal_len = audio_signal.to(vad_model.device), audio_signal_len.to(vad_model.device)
logits = model.forward(input_signal=audio_signal, input_signal_length=audio_signal_len)
return logits次に、フレームベースで動作するVADのクラスFrameVADを定義します。ここでは推論に関わる処理のみ抜粋して記述しています。データを保持するクラスやFrameVADの詳細を知りたい方はこちらからご覧ください。
class FrameVAD:
def __init__(…):
…
def _decode(self, frame, offset=0):
assert len(frame)==self.n_frame_len
self.buffer[:-self.n_frame_len] = self.buffer[self.n_frame_len:]
self.buffer[-self.n_frame_len:] = frame
logits = infer_signal(vad_model, self.buffer).cpu().numpy()[0]
decoded = self._greedy_decoder(
self.threshold,
logits,
self.vocab
)
return decoded
@torch.no_grad()
def transcribe(self, frame=None):
if frame is None:
frame = np.zeros(shape=self.n_frame_len, dtype=np.float32)
if len(frame) < self.n_frame_len:
frame = np.pad(frame, [0, self.n_frame_len - len(frame)], 'constant')
unmerged = self._decode(frame, self.offset)
return unmerged
…最後に、これらの処理をまとめた関数offline_inference()を定義します。
def offline_inference(audio, STEP = 0.025, WINDOW_SIZE = 0.5, threshold=0.5):
FRAME_LEN = STEP # infer every STEP seconds
CHANNELS = 1 # number of audio channels (expect mono signal)
RATE = 16000 # sample rate, Hz
CHUNK_SIZE = int(FRAME_LEN*RATE)
vad = FrameVAD(model_definition = {
'sample_rate': SAMPLE_RATE,
'AudioToMFCCPreprocessor': cfg.preprocessor,
'JasperEncoder': cfg.encoder,
'labels': cfg.labels
},
threshold=threshold,
frame_len=FRAME_LEN, frame_overlap = (WINDOW_SIZE-FRAME_LEN)/2,
offset=0)
empty_counter = 0
preds = []
proba_b = []
proba_s = []
for i in range(len(audio) // CHUNK_SIZE):
signal = audio[i*CHUNK_SIZE:(i+1)*CHUNK_SIZE]
result = vad.transcribe(signal)
preds.append(result[0])
proba_b.append(result[2])
proba_s.append(result[3])
if len(result):
print(result,end='\n')
empty_counter = 3
elif empty_counter > 0:
empty_counter -= 1
if empty_counter == 0:
print(' ',end='')
vad.reset()
return preds, proba_b, proba_sモデルの実行
それでは手元の音声を使ってモデルを実行してみます。今回は私自身が発話した「AI Shiftの東です」という音声を識別させます。
Google Colaboratoryではマイク音声をそのまま入力に使用できないので、colab_utilsというライブラリを使用して音声を録音します。
from colab_utils import getAudio
from resampy import resample
audio, sr = getAudio()このままだと48kHzで音声が収録されてしまうようなので、事前学習時と同じサンプリングレートにダウンサンプリングします。
audio = resample(audio, sr, SAMPLE_RATE, filter='kaiser_best')この音声を使ってVADを行うのですが、波形表示に使用してるlibrosaがfloat32の形式にしか対応していないのでこちらのTipをもとに変換をかけます。
def soundDataToFloat(SD):
"Converts integer representation back into librosa-friendly floats, given a numpy array SD"
return np.array([ np.float32((s>>2)/(32768.0)) for s in SD])実行結果
閾値を0.4に設定したところ、下の画像のような結果が得られました。
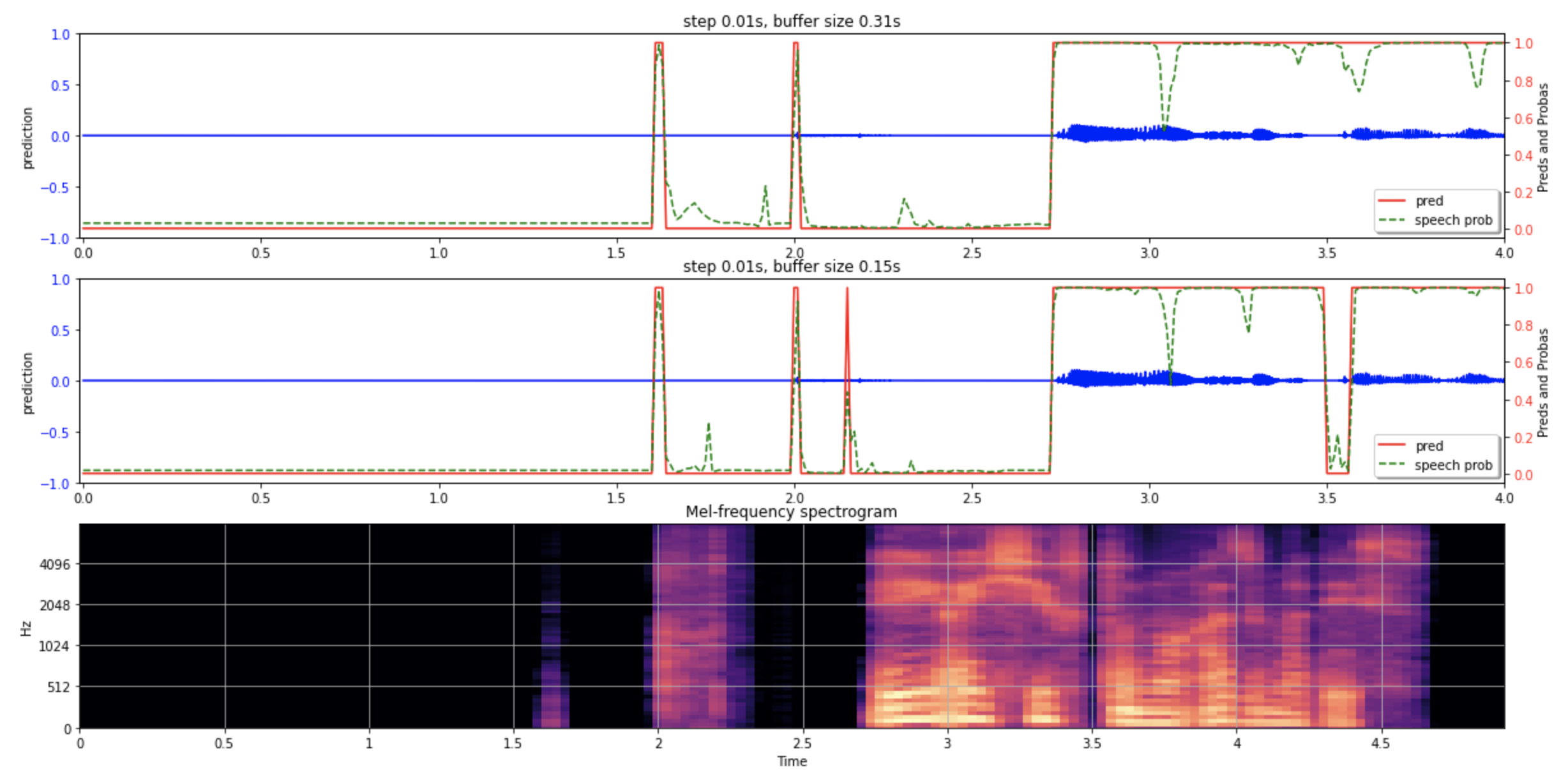
画像一番上が窓幅を0.31に、中段が0.15sに設定した結果です。一番下が波形をメルスペクトログラムに変換した結果です。
発話を始めたタイミングが2.7秒あたりですので、概ね正しく識別できていそうです。
おわりに
本記事ではMarbleNetを使用して音声区間検出を行いました。
NeMoのフレームワークを利用することで、手元で学習を行わない状態でも、ある程度手軽で正確に音声を識別することができました。
ただ、発話前の一部にSpeechと誤判定されている箇所もあり、ファインチューニングや結果のスムージング等の処理をかける必要がありそうです。
明日は最適輸送に関する記事が出ますので、是非そちらもご覧ください。
最後までお読みいただきありがとうございました!
参考
- 信号パワーと零交差数を用いた音声区間検出
- inaSpeechSegmenterによる音声区間検出
- MarbleNet: Deep 1D Time-Channel Separable Convolutional Neural Network for Voice Activity Detection
- https://github.com/ricardodeazambuja/colab_utils
- Python resampyで音声・音楽ファイルをリサンプリング(アップ/ダウンサンプリング)
- Audio Tip: Librosa Float to Int and Int to Float Conversion




