こんにちは。AIチームの杉山です。
本記事は AI Shift Advent Calendar 2021 の6日目の記事です。
今回の記事では現在弊社が提供している、電話での音声自動応答サービスであるAI Messenger Voicebotにおける音声認識結果からのエンティティ抽出に関する取り組みについて紹介します。
はじめに
店舗の検索や予約などのタスクを行う音声自動応答サービスでは、ユーザーの発話を音声認識モデルを通してテキスト化し、そこからタスク完了に必要なエンティティ(ex. 日時、店舗名、etc.)を抽出することが一般的です。
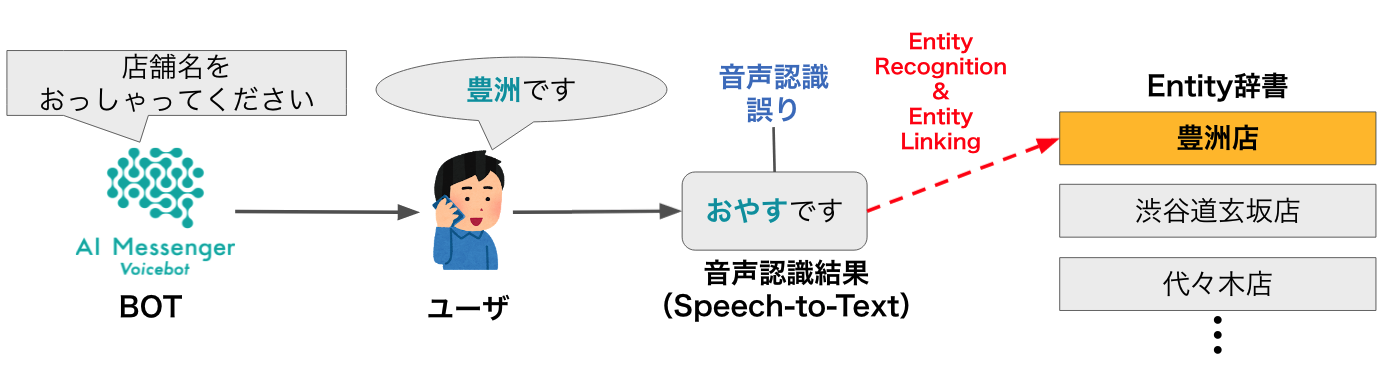
そのため、ユーザーの発話内容を正しく音声認識できることはタスクの完了率に直結する重要な要素ですが、近年大幅に進歩しているとはいえその精度は完璧ではありません。
また、電話というチャネルの特性上サンプリング周波数が8kHzであったり話者の周囲の雑音が入ってくる可能性があったりと、いわゆる実験室的な環境より難しい問題となっています。
そこで弊社では昨日の記事の内容をはじめ、ノイジーな音声認識結果であってもタスクの完了に必要なエンティティを抽出するために様々な取り組みをしていますが、その中の一つとして音声を音素レベルで認識した結果を用いた抽出の検証について紹介します。
音素列を用いたエンティティ抽出
先述のように音声認識結果には誤りが含まれることがありますが、その誤り方は全くのランダムではなくある程度音の近いものであることが想定されます。(ex. AI->出会い)
そこで、音声認識結果に対して音の情報を使用することで多少の認識誤りがあってもエンティティのマッチングができるのではないかと考えました。MeCabやOpenJTalkなどを用いてテキストの読み情報を取得することができますが、ここでは音声認識結果としての音素を使用することにします。モチベーションとしては読みを用いた編集距離やアラインメントよりも、「sh」と「ch」や「hy」と「ky」の類似性を考慮できるのではないかと考えたためです。
なお我々が利用しているGoogle Speech-To-Textを始め、昨今の高精度な音声認識モデルはEnd-to-Endで学習が行われるようになってきており、漢字変換後の結果しか取得できないことが多いため、今回はESPNet2で学習した音素列認識モデルを用いて検証を行いました。また、正解エンティティの音素列の取得にはPyOpenJTalkを用いました。
文字列アラインメントとBioPython
今回の検証では、ユーザーが単純にエンティティのみを発話したのではなく、エンティティを含む文章を発話するケースを想定とします。(ex.システム「あなたはどこに勤めていますか」→ユーザー「はい、株式会社AI Shiftです。」正解エンティティ:AI Shift、不正解エンティティ:[サイバーエージェント、etc.・・・])
このようなケースでは編集距離だと削除コストが大きくマッチしている部分文字列のスコアが低く評価されるのではないかと考えられます。そこで、以前バイオインフォマティクスを学んでいたときに扱っていたゲノム配列の配列アラインメントが使えないかと考えました。配列アラインメントとは、大雑把に言うとベースとなる塩基列に対し挿入や欠損を考慮しつつ類似する塩基列を探索する手法です。詳しくはこちらの資料などが参考になります。配列アラインメントには大きくローカルアラインメントとグローバルアラインメントがありますが、今回は局所的にエンティティがマッチングできれば良いため、ローカルアラインメントを用いることにします。
当時は限られたツールが提供されているのみでしたが、現在ではPythonのパッケージとしてバイオインフォマティクスで用いられる様々な実装がBioPythonというライブラリで提供されていますので、アラインメントについてはこちらを使用することにします。
検証
それでは、今回の検証の流れを説明します。
- エンティティを含む文章を発話し、音素列認識モデルを用いてその音素列を取得する
- エンティティ候補のリストに対してPyOpenJTalkで各音素列を取得する
- エンティティ候補の音素列それぞれとのアラインメントを行いスコアを算出、スコアが一番高い候補を正解エンティティとして抽出する
1に関して、まずQuickTime Playerで録音し以下のコマンドで電話音声と同じ8kHzにダウンサンプリングして音素列認識モデルを適用します。
afconvert -f WAVE -d LEI16@8000 source.m4a target.wav先述の例のように「はい、株式会社AI Shiftです。」と発話した音声に対し、
「h a i pau k a b u sh I k i g a i sh a pau r e e a i sh i f U ts u」
という音素列が得られました。エーアイのエがレになったり最後がぐしゃぐしゃっとなって「トです。」の部分が潰れて「ts u」と認識されています。
2では以下のようにPyOpenJTalkでそれぞれのエンティティ候補に対し音素列を取得します。今回は、少ないですが「AI Shift」「サイバーエージェント」「AI事業本部」の3つをエンティティ候補としています。
import pyopenjtalk
ais_phoneme = pyopenjtalk.g2p("AI Shift") # 'e e a i pau sh i f U t o'
ca_phoneme = pyopenjtalk.g2p("サイバーエージェント") # 's a i b a a e e j e N t o'
aid_phoneme = pyopenjtalk.g2p("AI事業本部") # 'e e a i j i gy o o h o N b u'最後に、BioPythonを用いて各ペアのアラインメントを計算します。本来は「sh」と「ch」の類似性を表現するためにアラインメントを用いたかったのですが、そのまま計算すると「sh」と「h」など類似していない音素でも一部マッチしてしまうことから、各音素を1文字に、類似性を持つものは2文字にエンコードし(ex. a->A, ..., k->F, ... cl->t, ... sh->N1, ch->M1, ... , ky-> D2, ry->E2, ...)、アラインメントを行いました。その結果の一例を示します。
なお、アラインメントのマッチ・ミスマッチ、欠損に関するパラメーターは簡単のために固定で以下の通りとしました。
from Bio import pairwise2
from Bio.pairwise2 import format_alignment
match = 2
mismatch = -1
gap_start = -0.5
gap_expand = -0.1
asr_phoneme_result = "h a i pau k a b u sh I k i g a i sh a pau r e e a i sh i f U ts u"
# phoneme_encode()は音素をエンコードする関数
encoded_asr_result = phoneme_encode(asr_phoneme_result)
encoded_ais_phoneme = phoneme_encode(ais_phoneme)
for a in pairwise2.align.localms(encoded_asr_result, encoded_ais_phoneme, match, mismatch, gap_start, gap_expand):
print(format_alignment(*a))
break
-------アラインメント結果--------
22 eeac-n1cCr
|||| |||||
1 eeacmn1cCr
Score=17.5
このように、簡単に局所最適なアラインメントを得ることができます。ここで、スコアは高い方がより類似した部分文字列を表します。このままではどういうマッチングがされたか分かりづらいため、エンコードを元の音素列に戻し、読みやすいように整形した結果をそれぞれ以下に示します。
-------AI Shiftとのアラインメント結果--------
22 eeac-n1cCr
|||| |||||
1 eeacmn1cCr
Score=17.5
------デコード、整形後----------
e e a i --- sh i f U
e e a i pau sh i f U
-------サイバーエージェントとのアラインメント結果--------
2 acmfawdn1sfcpacn1amiee
|| | | | ||
2 ac---w-------a---a--ee
Score=10.9
------デコード、整形後----------
a i pau k a b u sh i k i g a i sh a pau r e e
a i --- - - b - -- - - - - a - -- - a - - e e
-------AI事業本部とのアラインメント結果--------
22 eeacn1-cCry--------d
|||| | |
1 eeac--xc---F2bbubkwd
Score=9
------デコード、整形後----------
e e a i sh - i f U ts - - - - - - - - u
e e a i -- - j i - - - gy o o h o N b u今回の結果では、正解となるべきAI Shiftとのスコアが最大となりました。結果を見ても「はい(h a i)」の部分に引っ張られず発話中のエンティティ箇所とマッチングできていることがわかります。逆にサイバーエージェントとのアラインメントでは類似している箇所が少なく無理矢理なアラインメントになっておりスコアも低く算出されています。最後に、AIを含む候補としてAI事業本部で試したところ、AIの部分でマッチングしたものの以降が類似していないためか意外にもスコアとしては2番目よりも低い結果となりました。
今後は、エンティティの候補と発話パターンを増やして定量的な精度の検証とよりよいパラメーターの探索なども行っていきたいと思います。また、今回は検証のために録音した音声で確認しましたが、実際の電話の音声ではよりノイジーな認識結果になると想定されるため、実データでも試していきたいと思います。
終わりに
今回は定量的な評価までできませんでしたが、パラメーターの設定やスコアの閾値、アラインメントの速度など実用面での課題は種々あるもののそれなりの結果は得られそうな感触でした。最近ではAlexaやGoogle Homeなどのスマートスピーカーを始め、同じような課題を持つサービスは増えてきており、近年のINTERSPEECHやSIGDIALではAmazon, Googleなどを始め音の情報を用いたエンティティ抽出の研究が多く見られるようになってきています。我々も音声認識を伴うプロダクトを開発するものとして、引き続きこういった取り組みを進めていきたいと思います。
明日はSpotifyの介入割当選択モデルの性能比較に関する論文の紹介記事です。ぜひそちらもご覧ください。
参考
[1]https://biopython.org/
[2]https://espnet.github.io/espnet/espnet2_tutorial.html




