こんにちは、AIチームの杉山です。
今回の記事では、音声言語理解(Spoken Language Understanding: SLU)の1タスクである音声からの固有表現抽出の課題と評価用データセットであるAISHELL-NER[1]を紹介します。
音声からの固有表現抽出とその課題
音声からの固有表現抽出(NER)は、音声信号から固有表現を抽出することを目的としたSLUタスクで、Voice Assistant関連や弊社のように音声自動応答サービスを提供する企業を中心に研究が活発に行われています。
音声からのNERは一般的に、1.音声認識, 2.音声認識結果へのNERタグの付与という2段階のパイプラインによって行われます。しかしパイプライン構成では前段のタスクの精度が後段のタスクに大きく影響を与えるため、最近の研究では音声を入力としてNERタグ付きテキストを出力するEnd-to-End (E2E) アプローチの研究が盛んに行われており、英語とフランス語の音声でその性能が示されています。[2][3]
しかし、日本語や中国語には多くの同音異義語や多義語が存在するため、それらの音声からのNERはより難易度が上がります。加えて一般的なNERの公開テキストデータセットは音声での入力と傾向が異なるため、それらのデータセットでSLUのための事前学習を行うことは不十分であることが報告されています。[4]
音声認識誤りやフィラーといった音声言語特有の課題もあり、実用面での精度向上に向けて我々のチームも日々改善に取り組んでいます。
AISHELL-NER
これらの課題に対し、Alibaba NLPチームがICASSP2022で新しいデータセットAISHELL-NERを公開しました。AISHELL-NERはオープンソースの中国語音声コーパスAISHELL-1 [5]を基に構築されています。AISHELL-1は170時間以上の北京語音声データ(約15GB)と書き起こし文を含むオープンソースの音声コーパスで、中国語に対するASRシステムの性能評価によく利用されています。このコーパスは金融・科学技術・スポーツ・エンターテインメント・ニュースの5つのドメインに関する音声が収録されています。このコーパスはBeijing Shell Shell Technology Co., LtdによってApache License v.2.0の下で公開されており、変更の有無にかかわらず再配布が可能です。
アノテーション
AISHELL-NERは、AISHELL-1の書き起こし文に対しPER、LOC、ORGの3種類の固有表現タグをアノテーションしています。具体的な方法は元論文に譲りますが、大まかにはBERTをfine-tuningしたモデルで仮のタグ付けを行い、そのタグに対し手動アノテーションを行なっています。手動アノテーションはアノテーターのスキルレベルの統一や厳密な検修品質を設定するなどかなり高品質に行われています。
固有表現タグはそれぞれPERの[ ]、LOCの( )、ORGの< >といった特殊なトークンで固有表現を囲うことで付与されます。こうすることで、E2Eに学習する場合音声信号とアノテーションデータとのアライメントを学習することができ、音声から直接NEを抽出することができるようになります。その結果、パイプライン構成とした場合の課題であったカスケードエラーを排除できることが期待されます。なお、パイプライン構成でも使うことができるように一般的なBIOフォーマットのアノテーション結果も提供されています。
コーパス統計
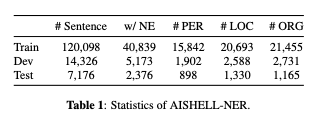
AISHELL-NERコーパスのデータ数と固有表現タグの出現頻度は表1のような内訳となっています。アノテーションには、合計68,604個の固有表現を含む48,388文があり、そのうち約1/3に固有表現タグが含まれています。
データの確認
それでは、実際にデータをダウンロードして確認してみたいと思います。AISHELL-1は音声処理フレームワークであるESPnetにレシピがあるため、ESPnetをインストールしていれば音声データはそちらから以下のように取得できます。
$ cd YOUR_ESPNET_PATH/egs2/aishell/asr1
$ ./run.sh --stage 1 --stop-stage 1また、こちらのリンクから直接ダウンロードすることもできます。
AISHELL-NERのアノテーションデータはこちらに公開されています。AISHELL-1の書き起こしデータである downloads/data_aishell/transcript/aishell_transcript_v0.8.txt を上記のものに置き換えることでE2Eでの学習に使用することができます。
実際に1つのデータを確認してみたいと思います。残念ながら私は中国語がわからず書き起こすことができないため、今回はGoogleの音声認識APIを使用します。
アノテーションデータ
BAC009S0902W0133 美丽(北京)大型绿色公益品牌项目
北京にLOCのタグ()が付与されています。
次にアノテーション元の音声の書き起こしを行います。
wav_path = "YOUR_FILE_PATH/BAC009S0902W0133.wav"
with io.open(wav_path, "rb") as audio_file:
content = audio_file.read()
audio = gs.RecognitionAudio(content=content)
config = gs.RecognitionConfig(
encoding=gs.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code="zh",
max_alternatives=10,
)
response = client.recognize(config=config, audio=audio)
for result in response.results:
for alt in result.alternatives:
print(alt.transcript)
# 音声認識結果
# 美丽北京大型绿色工艺品牌项目
# 美丽北京大型绿色供应品牌项目
# 美丽北京大行绿色工艺品牌项目
# 美丽北京大兴绿色工艺品牌项目
# 美丽背景大型绿色工艺品牌项目
# 美丽的北京大型绿色工艺品牌项目
# 美莉北京大型绿色工艺品牌项目
# 美丽背景大型绿色供应品牌项目
# 每粒北京大型绿色工艺品牌项目
# 美力北京大型绿色工艺品牌项目パイプライン構成を想定した今回の例では、固有表現である北京は正しく認識できましたが正解の書き起こし文と一致したASR N-Bestはなかったため、誤り箇所が固有表現だった場合にはカスケーディングエラーが起きてしまいそうです。
今後E2Eでこの課題が解決できるようにする方向性で研究が進むのだと思います。
終わりに
今回は音声からの固有表現抽出のための中国語音声データセットであるAISHELL-NERの紹介を行いました。本記事ではデータセットの紹介に留めましたが、元論文ではこれらのデータセットを用いたパイプライン構成とE2Eでの実験結果の比較なども行われているので気になる方はぜひそちらもご覧ください。
今回の論文を読んでいて、我々と似た課題感を持っているんだなと感じたと共に、そこに対しデータセットの作成から公開まで行なったAlibaba NLPチームの貢献の大きさを感じました。データの所有権や音声のプライバシーなど様々な障壁はありますが、今後日本語データセットでも同様の貢献ができればと思いました。




