こんにちは。AIチームの柾屋です。
もともとビジネス側で広告運用コンサルティングやツール導入後のカスタマーサクセスを担当してきましたが、2022年4月からビジネスチームからAIチームへデータアナリストとして異動してきました。
tableauやGAS、RPA、簡単なPythonなどは業務で取り組んできましたが、初の試みとして機械学習で知識ゼロからボイスボットの離脱予測モデルを作成するというミッションに取り組みました。
取り組みの中で得られた「概念としての機械学習」と「実務で利用するため機械学習」とのギャップや面白さを紹介していきたいと思います。
この記事を読んで得られること
この記事は「AIや機械学習について概念は知っているけど、実務での取り組みはない」という方を対象にしています。
この記事を通して
- AIや機械学習の特性を理解した上で、どのような業務へ活用できるかを考えるきっかけになる
- これから機械学習でモデルを作成しようとする際に、失敗しがちなポイントを理解して効率よく進めることができる
- AIや機械学習のエンジニア、データサイエンティストの仕事の一部を理解し、採用や今後のキャリア選択に活かせる
などに役立てられる情報共有を目指していきたいと思います。
前半パートでは、AIや機械学習についての基礎的な知識から、今回の予測タスクで活用したロジスティック回帰、決定木、LightGBMの特徴について紹介しました。
後半パートでは、実際にモデリングをした際に陥った失敗例を紹介していきたいと思います。
機械学習のモデルを実行するまでは簡単
機械学習のモデルを実行することは難しくありません。
必要なのは、
- Pythonの実行環境(なくてもGoogleアカウントがあればOK)
- 活用したい機械学習モデルのコード
- 学習データ
の3つだけです。
1.Python環境
機械学習やデータ分析周りはPythonで数行のコードで簡単に実行できることが多く、実行するまでのハードルは高くはありません。
Pythonは専用ツールをPCにインストールしていなくとも、Googleの無料ツール(Google Colab)で利用することができます。
2.活用したい機械学習モデルのコード
機械学習のプログラミングコードはインターネット上にかなり公開されています。
自身の活用したいモデルでコードを検索すると親切にまとめてくれている記事がいくつもヒットします。
数年前まではインターネットで調べても参考となる情報が少なかったと聞いていますが、最近ではそのような心配はしなくても良さそうです。
3.学習データ
前半パートでは機械学習には大きく、「教師あり学習」、「教師なし学習」、「強化学習」の3つの領域に分かれていると紹介しました。
それぞれの学習に合わせて必要なデータセットを準備してあげる必要があります。
私の場合は、「ボイスボットの離脱予測モデル」を作成する予定だったため、ボイスボットの特徴量となるような情報と、「離脱したかどうか」の情報が含まれているデータセットを用意しました。
この3つが揃えば予測モデルを簡単に作成することができます。
予測モデルを作成した後は、どの程度の精度があるかをスコアで図ることができます。スコアを出すと「高い・低い」など何かしらの結果を得ることができます。
ここが機械学習のモデル作成のスタートポイントとなります。
モデルの改善
予測モデルのスコアは
- どのモデルを活用するか?
- どの学習データを与えるか?
- どうやってモデルの最適化をするか?
の3つで大きく変化します。
1.どのモデルを活用するか?
予測モデルを作成する場合、前半パートで少し出てきたこれらのようなモデルを活用することができます。
- ランダムフォレスト
- 決定木
- k近傍法
- 線形回帰
- ナイーブベイズ
- SVM(Support Vector Machine)
- ロジスティック回帰
- 勾配ブースティング
それぞれに特徴があり、判断基準はブラックボックスだけど、予測精度が高いモデルから、予測モデルはそこまで高くないけど、判断基準の解釈性が高いモデルまで幅広く分かれています。
大半の場合は、複数のモデルで予測精度を評価し、スコアが高いモデルを採用するといった流れが一般のようです。
2.どの学習データを与えるか?
予測精度の良し悪しの鍵となるものが、学習データです。
学習データの量はもちろん、どのような特徴量(説明変数)を準備できるかによって、予測の精度は大きく変わります。
実務の環境では、利用できるデータはデータソースがバラバラだったり、複数行に跨ってデータが分かれていたり、テキストデータだったりと、そのまま学習データとして利用できるケースはほとんどありません。
予測モデル作成のような機械学習の実務のうち、実に7割以上はデータ収集とデータの前処理(データクレンジング)に費やされると言われています。
また、どのようなデータなのかと言った事業知識があってこそ特徴量の取捨選択や解釈が生まれるため、ドメイン知識についても必須と言われています。
さらに、準備した特徴量は全てを利用すれば良いというわけでもありません。どのような特徴量の組み合わせにするかによってもスコアが変わってきます。
「feature importance」と呼ばれる特徴量の影響度を確認したり、「Wrapper Method」や「Embedded Method」などの特徴量選択のモデルを活用して選択する必要があります。
3.どうやってモデルを最適化させるか?
前処理されたデータセットを活用して、いくつか選定した機械学習モデルでスコアの比較を行っていく際に、もう1つチューニングポイントがあります。
それが、「ハイパーパラメータ」のチューニングです。
ハイパーパラメータとは,モデリングをする際に人間が決めなければいけない設定値です。
例えば、決定木モデルを活用する場合、木の深さ(depth)や最大の葉の数(max_leaf_nodes)がパラメータに当たります。
これらの数値を調整することで、スコアの改善を図ることができます。
ただ、地道に数字を当てずっぽうで入れて行っても最適なパラメータの組み合わせを見つけるのは至難の技でしょう。
そこで利用されるものが「パラメータ」最適化の手法です。
代表的な手法の1つが「Grid-Search(グリッドサーチ)」と呼ばれるもので、与えたパラメータの中からスコアの高い最適な組み合わせを選択することができます。
最初にもっと勉強しておけば良かった3つの失敗ポイント
予測モデルの改善を行っていく中で、チームの方からフィードバックや指摘をいくつもいただきました笑。
単純にスコアを高くするということだけではなく、選択したモデルや与える特徴量の制約をきちんと認識してモデリングを行う大切さを学びました。
その中で、特に重要だと思ったポイントをいくつか紹介していきたいと思います。
今回は下記3つのポイントを紹介します。
- ロジスティック回帰の際の特徴量選択の注意点
- 正しいモデル評価の重要性
- 予測モデルを作成する際に注意すべきリーク
1.ロジスティック回帰を行う際の特徴量選択の注意点
ロジスティック回帰は前半パートで紹介したように、「いくつかの要因(説明変数)から「2値の結果(目的変数)」が起こる確率を説明・予測することができる統計手法で、多変量解析の手法の1つ」です。
ロジスティック回帰を利用する場合は、「多重共線性(multi-colinearlity) 以下マルチコ」に注意する必要があります。
マルチコとは、「いくつかの特徴量(説明変数)同士が互いに強く相関しすぎている状態」のことを指します。
例えば、「足の速さ」を予測するようなモデルを作る場合に、特徴量(説明変数)として、身長・座高・年齢を選択したとします。
「身長が高ければ、座高は高く」、小中学生であれば、「年齢が高いほど、身長や座高も高い」という相関関係が見られると思います。
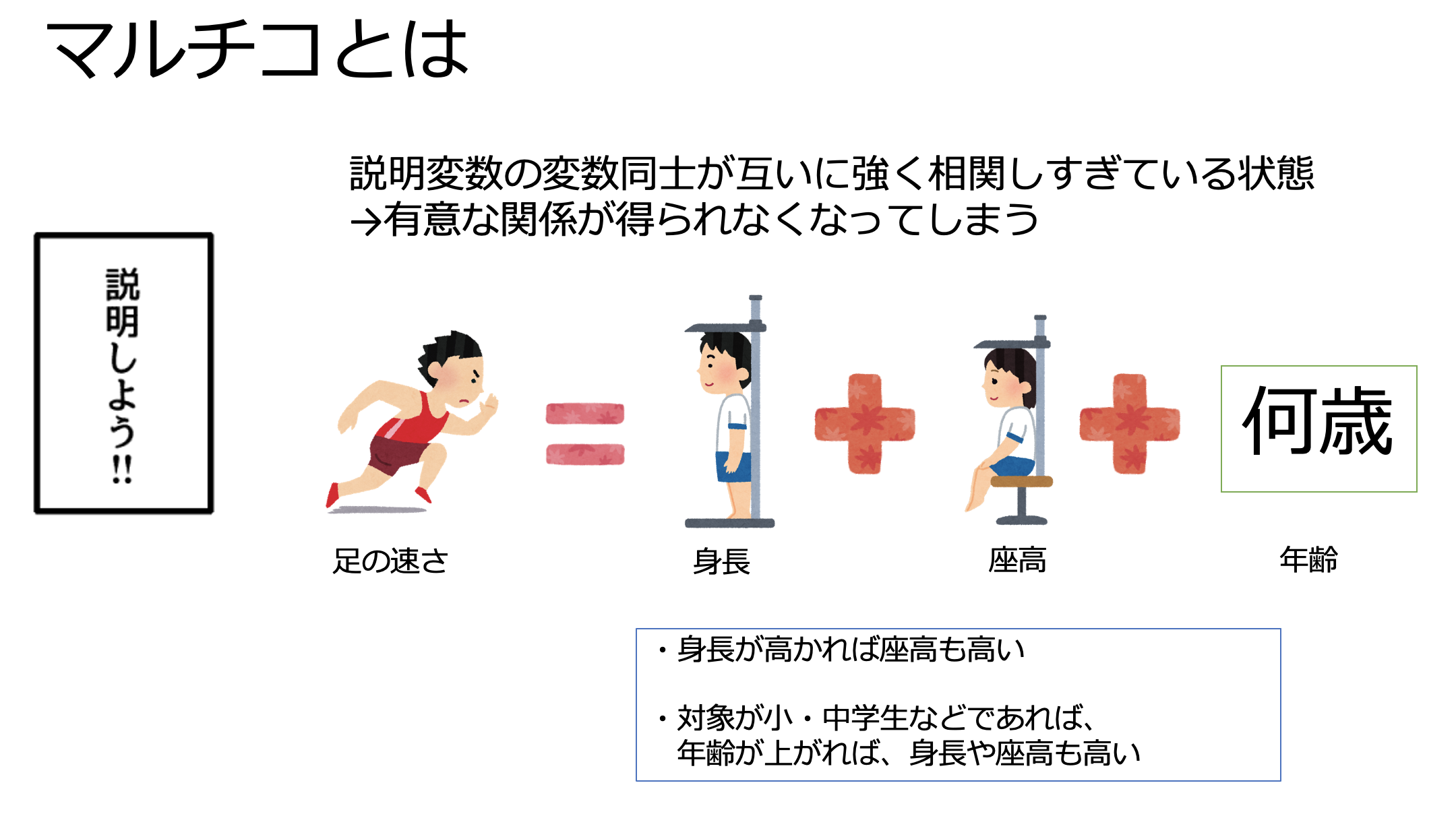
このように、特徴量(説明変数)同士が強く相関している場合、「足の速さ」との有意な関係が得られなくなってしまうことをマルチコと呼びます。
予測の正解率(Accuracy)だけを見ていると、マルチコに関わらず特徴量の取捨選択によってスコアが改善されるように見えてしまうので、注意が必要です。
2.正しいモデル評価の重要性
今回の離脱予測モデルのように、「離脱するか」「離脱しないか」と分けるタスクを「クラス分類」と呼びます。
クラス分類においては、いくつかの評価指標が存在しています。どの指標を使うかによって、特徴量選択からハイパーパラメータのチューニングまで大きく異なりますので、事前にどの評価指標を使うかを決めておく必要があります。
評価指標の種類
- 正解率・精度(Accuracy)
- 全体に対して予測が当たった割合
- 全体に対して予測が当たった割合
- 適合率
- 適合率は, クラスAと予測したものの中で, 実際に正しく予測できた割合
- 適合率は, クラスAと予測したものの中で, 実際に正しく予測できた割合
- 再現度
- 再現度は, 実際のクラスAのデータのうち, 正しくクラスAと予測された割合
- 再現度は, 実際のクラスAのデータのうち, 正しくクラスAと予測された割合
- F値
- 適合度と再現率の調和平均
- 適合度と再現率の調和平均
- LogLoss
- 確率(Probability)の大きさを評価スコアとして取得したい場合に利用
- 確率(Probability)の大きさを評価スコアとして取得したい場合に利用
- AUC
- モデルの精度(=性能:performance)をより汎用的に計測したい場合に利用


もともとは、正解率(Accuracy)を評価スコアとして活用していましたが、正解データと不正解データの不均衡が大きい場合、誤った評価となる可能性を指摘されました。
例えば、
- 離脱ありデータ:90サンプル
- 離脱なしデータ:10サンプル
だった場合、離脱ありのデータが圧倒的に多いため、「とりあえず離脱ありと予測しておけばよい」と予測モデルが学習する場合があります。
その場合、離脱ありのスコアは全部のデータに対して「離脱あり」と予測するため、正解率は90%となります。
ただ、一方で「離脱なし」を離脱なしとして予測し正解した割合は0%となり、「正しく分類できているのか?」という視点で見るとあまり精度は高く無いケースがあります。
そのため、最終的にはモデルの精度をより汎用的に評価することができる「AUC」でスコアを図る方針に変更しました。
AUC(Area Under the ROC Curve)
AUCは縦軸に真陽性率、横軸に偽陽性率を取り、最大値1の面積の値で表現する評価手法です。このROC曲線(青色の線)の下にある領域(水色の領域)の面積がAUCの値となります。
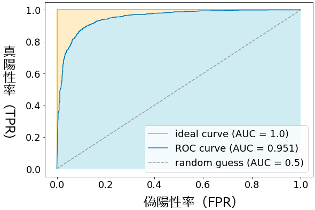
- 縦軸(y軸)に真陽性率(True Positive Rate:TPR)
- 横軸(x軸)に偽陽性率(False Positive Rate:FPR)

3.予測モデルを作成する際に注意すべきリーク
リークとは「本来手に入らない情報が特徴量に入っており、過度に良いスコアが出ている状態」のことを指します。
例えば、下記のような情報がリークに当たります。
- サッカーの試合結果を当てるモデルで、パス本数など試合をやってからでないと手に入らない変数を使っている
- 「2006年の映画に対して各ユーザーが評価をするかどうかを予測」するのに、2006年のデータを利用した
- 気候の時系列のデータで最高気温を予測するモデルを作る際に、そのモデルでの予測実行のタイミングではまだ得られていない「同時刻の最低気温」を特徴量として追加した
よくよく注意すると、「予測」として使うためのデータに、「実際のスコアに関連するデータ」が入っているのでおかしいと気づかれる方も多いかと思います。
ただ、実際にモデリングをしていると、気づくべきところで気付けないというケースが多いのです。
私の場合は、初期の段階からaucのスコアが9割を超えており、それが当たり前の水準と思い込んでいたため、不適切な特徴量が入っているとは少しも気にかけていませんでした。
実際に、決定木やLightGBMでのfuture_importanceや分岐条件を見て、特定の特徴量だけでほぼ全体が判断されていることが分かり、この情報はリークしていないか?と指摘を受け発覚しました。
データ準備の段階で、どのような情報がリークとなるかは、経験がないと判断が難しいと感じました。
周りの方の助言をもらいつつ、リークしない特徴量選択を行うことが大切だと思います。
まとめ
以上、前半パートではAIや機械学習、モデルの特徴について、後半パートでは実際にモデリングを行う手順から注意点についてを紹介しました。
私自身、もともと数年前まで非エンジニアで営業職だったので、今このような仕事の機会を得ていることに感謝しつつ、日々インプットの毎日を過ごしています。
AIや機械学習はまだまだ正しい知識としてインプットしている方は少数で、AIエンジニアと現場のビジネスマンとでの齟齬が生まれることは少なくありません。
AIに関する正しいインプットを持つことで、より多くの世の中の課題をAIで解決していくことができると考えています。
興味があれば誰でも学習できる環境が揃っていますので、ぜひチャレンジを検討してみてはいかがでしょうか。
最後までお読みいただきありがとうございました。




