こんにちは!AIチームの二宮・東です。
8/29, 30にNLP若手の会(YANS)第17回シンポジウムが開催され、AI Shiftからは2件の発表を行いました。
発表の詳細は以下の前回記事をご覧ください。
今回はその参加報告として、AI Shiftからの発表とハッカソンについてご紹介いたします。
オンライン開催
今年のYANSも昨年、一昨年に引き続きオンラインでの開催となりました。
チュートリアル講演はZoomでの開催となり、ポスター発表はGatherでの開催となりました。特にポスター発表では、自分の聞きたい発表を自由に見て回ることができるため、とても有意義な時間を過ごすことができました。人気の発表はキャラクターでスペースが埋まっているところもありました。
講演やポスター発表の移動時間がほとんどなく、また気になった発表は簡単に資料を読むことができるのはオンライン開催ならではのメリットだと感じました。
AI Shiftからの発表
今年のYANSでは2件の発表を行いました。どちらの発表もとても沢山の方々に聴講していただくことができました。また、活発に議論をさせていただき、実りの多い発表となりました。本当にありがとうございます。
以下、各発表ごとの簡単なまとめといただいた質疑、コメントをいくつか紹介させていただきます。
[P2-1] MC dropoutに基づく確信度を用いた回答可否の予測を伴う対話システム
○二宮大空(AI Shift),下山翔(AI Shift),戸田隆道(AI Shift),邊土名朝飛(AI Shift),杉山雅和(AI Shift),友松祐太(AI Shift)
本研究では、MC dropoutと呼ばれる手法を用いて、検索モデル(Bi-Encoder)の回答の確信度を求めました。これにより、回答の確信度が低い場合には「回答が見つかりませんでした。」と応答したり、「(回答A)でしょうか?(回答B)でしょうか?」など選択肢の提示をしたりすることで、解決率の向上に繋がるのではないかと考えております。
いただいた質疑、コメント:
- 推論速度と推論コストはどうなるか?
- 一方、もしくは両方が増加します。これは、MC dropoutで設定した回数分の推論処理が追加で実行されることとなるためです。プロダクトに組み込むことを想定すると、より詳細な分析が必要であると考えています。
- MC dropoutとベイズ推論との関係性は?
- MC dropoutは近似的にベイズ推論を行う手法です。提案された論文は、"Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning"で、その題からもベイズ推論と関連した手法であることがわかります。
[P3-10] 特定の文脈における正規表現を用いた電話音声認識のドメイン適応の検討
○東佑樹(AI Shift),友松祐太(AI Shift)
本研究では電話番号や番地等の「予めパターンの決まっている音声」の認識精度を向上させるために、正規表現によって得られるテキストをTTSによって音声に変換したものを転移学習に利用するという設定で実験を行いました。
始まったばかりの研究ではありましたが、当日はさまざまな方から質問、コメントをいただいきました。主な内容は以下の通りです。
- 実験に使用したConformerはどのような設定にしてあるか?
- 実験はESPnetを用いて実施しており、CSJのレシピをベースにしている。
- Conformer内部のPositional Encoding(以下、PE)の部分はRoPEという手法が提案されており、もし通常のPE(Sinusoidal PE,learnable PEなど)を使っているなら試してみてもいいかも
- 学習時と推論時の音声のサンプリング周波数の違いによる影響は確かに存在するかもしれないが、その対処だけで電話音声の特徴を捉えられる訳ではないので、別の工夫も検討されてみてはどうか
- 今回の実験設定では適用範囲があまり多くなさそうなので、特定のドメインの専門用語の認識に特化する方向に発展させるのはどうか?
- 今回のポスターには記載していなかったが、特定のドメインの用語への対応というのも今後の展望には入っており、サーベイ含めて検討段階である
ハッカソン
今回のハッカソンは、本会議開催前の8/28までの約2週間で、4人ほどのチームを組んでスコアを競い合いました。AI ShiftからはAIチームの二宮が参加いたしましたので、簡単に内容をご紹介したいと思います。
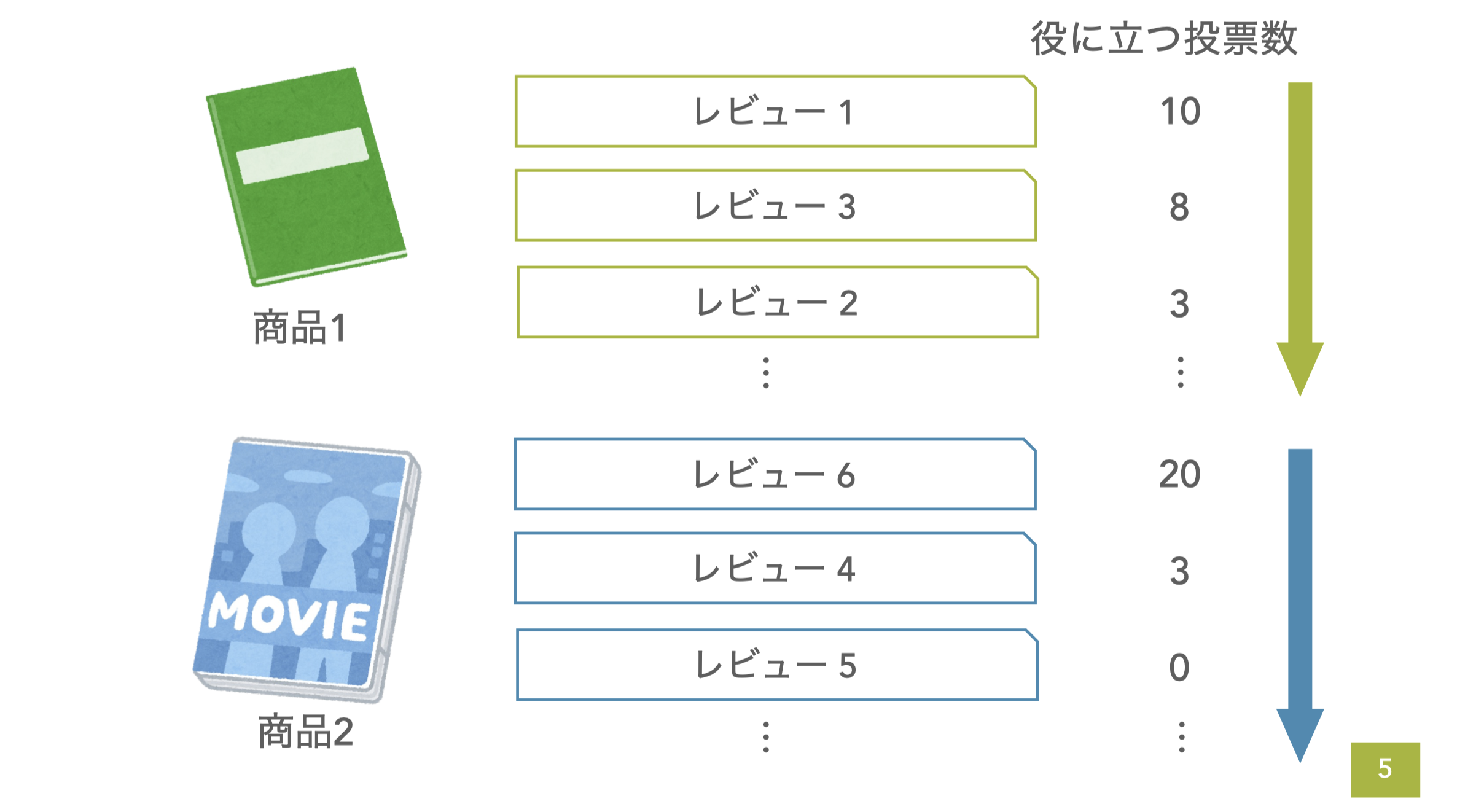
今回のタスクはアマゾンウェブサービスジャパン合同会社様からご提供いただいたもので、Amazonで販売する商品ごとに、レビューの"役に立つ"投票数が多い順にランキングするタスクでした。
計算機環境としてAmazon SageMaker Studio LabとGoogle Colab Pro +が提供されました。このおかげで計算機環境の面で苦労することはほとんどなく、かなり自由に試行錯誤することができました。Amazon SageMaker Studio Labは初めて利用したのですが、慣れ親しんだJupyterLabで作業することができたので、個人的にとても使いやすかったです。
また、ベースラインとしてBERTのfine-tuningのコードが提供されました。これがpytorch-lightningを用いてシンプルに実装されており、とても読みやすかったです。データ数を指定して学習することができますし、実行時間も1epochあたり1.5時間程度と非常に軽くなっており、PDCAが回しやすいものとなっていました。個人的には、Amazonの良いレビューの特徴を探るために、実際のレビューを眺めて特徴量を考える作業がとても面白かったです。

結果は参加チーム(チームA-Natural)が見事第1位となりました。さらに、同チームがAWSよりApplied Scientist賞に受賞されました。チームの方々には本当に感謝してもしきれません。
私自身はKaggleなどの機械学習コンペティションの経験がほとんどありませんでした。そのため、今回のハッカソンを通じてデータ分析の基礎から、コンペで使える手法まで多くのことを学ばさせていただきました。チームの皆様、運営の皆様、タスクを提供していただいたアマゾンウェブサービス合同会社様、関わって下さった全ての方々に感謝申し上げます。
おわりに
今回もオンライン開催となったYANSでしたが、オフラインの学会と遜色ないほど多くの知見や体験を得ることができました。発表を聞きにきてくださった皆様や委員の皆様のご尽力に感謝いたします。
弊社としても今後も継続的に対外発表の場として関わっていければと思います。
最後まで読んでいただきありがとうございました!




