こんにちは AIチームの戸田です
今回はLAUG(Language understanding AUGmentation)による対話データの拡張を紹介し、実際に試してみたいと思います。
LAUGとは
対話システムを学習するためのデータセットとして、近年ではMultiWoZやCrossWoZなど様々なデータセットが公開されていますが、実世界で対話システムを使おうとすると、音声認識誤りや「um…」のような言いよどみなど、こういったデータセットに無い変動がみられる場合が多くあります。

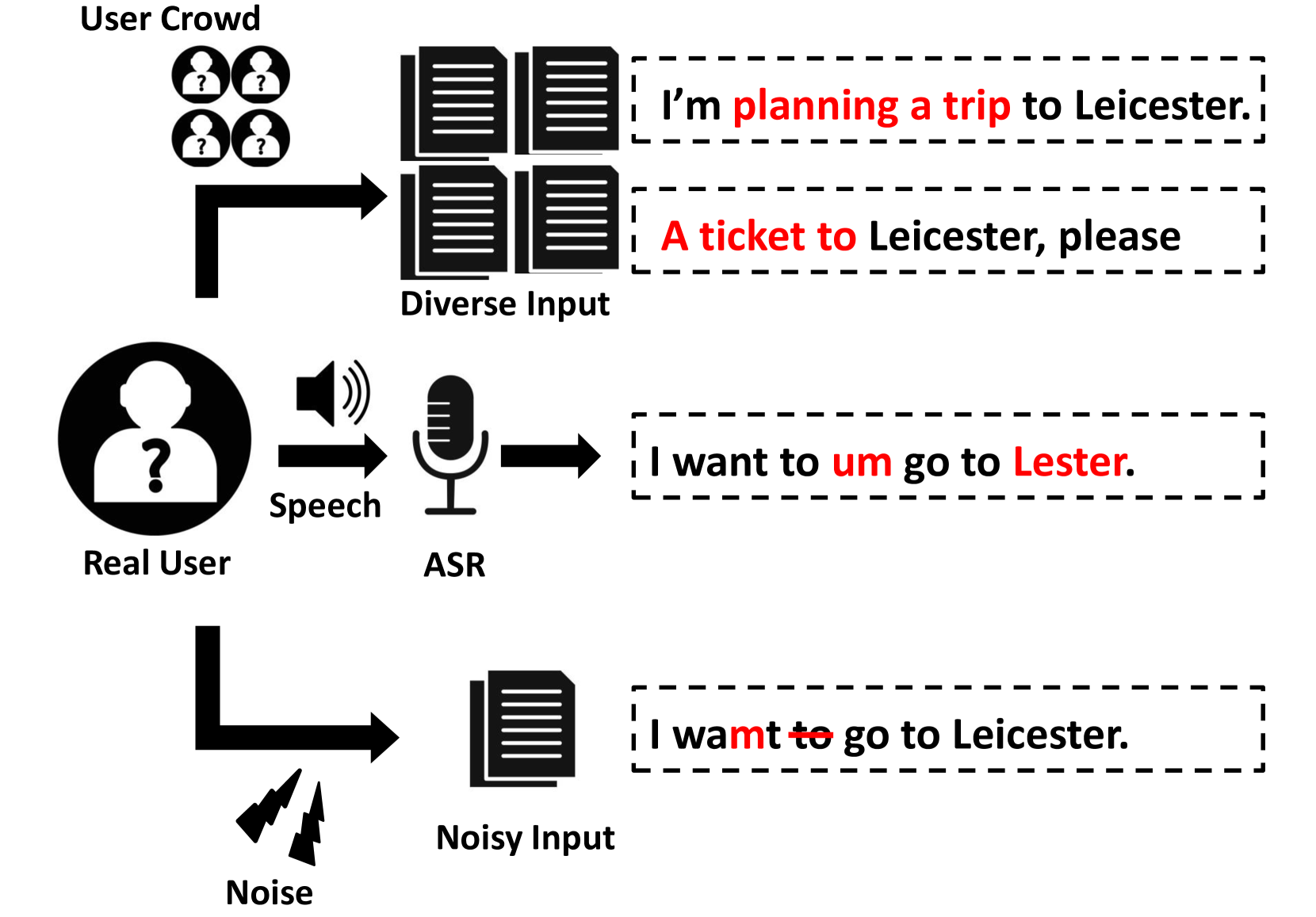
LAUGはこういった変動に対応するため、Robustness Testing of Language Understanding in Task-Oriented Dialogという論文で提案された、対話システムの言語理解(NLU)の学習のために、音声認識誤りや単語の位置入れ替えなどを再現することでデータ拡張を行うことが出来るツールです。
LAUGは4つのモジュールが含まれており、それぞれ異なったアプローチでデータ拡張を行います。
1. Word Perturbation
WordNetを使って以下の処理を行います
- 文章中の単語を類義語に置換
- 文の意味が通じる範囲で語順を入れ替え
- 文の意味が変わらない範囲で単語を削除
- 文の意味が変わらない範囲で単語を追加
対話に限らず、よく使われるデータ増強手法ですね。なお、ホテル検索での目的地など、タスクのスロットにかかわる単語は処理しないような制約がかけられています。
2. Text Paraphrasing
タスク指向対話の為に事前学習されたtransformerモデル、SC-GPTを使った言い換え文章を生成します。Word_Perturbationと同様、類似文を作るという処理になりますが、こちらは略語や主語や述語の省略への対応を期待しています。例えば
Aさん「Where do you want to go?(どこへ行きたいのですか?)」
Bさん「to Cambridge(ケンブリッジへ)」
といったやり取りが対話では起こりえます。Bさんの発話には「I want to go」が省略されているのです。大規模言語モデルをつかって、こういった省略を再現しようというのが、Text_Paraphrasingのねらいです。元の発話の意図とずれがないように、文章は複数生成され、編集距離を使ってフィルタリングしています。
READMEには記載はありませんが、コードを見るとXLNetやXLMなどGPT以外のモデルも対応しているようです。
3. Speech Recognition
TTS(Text To Speech)とASR(Automatic Speech Recognition)を組み合わせて、音声認識誤りを再現します。TTSモデルはgTTS、ASRモデルはdeep speechを使っています。
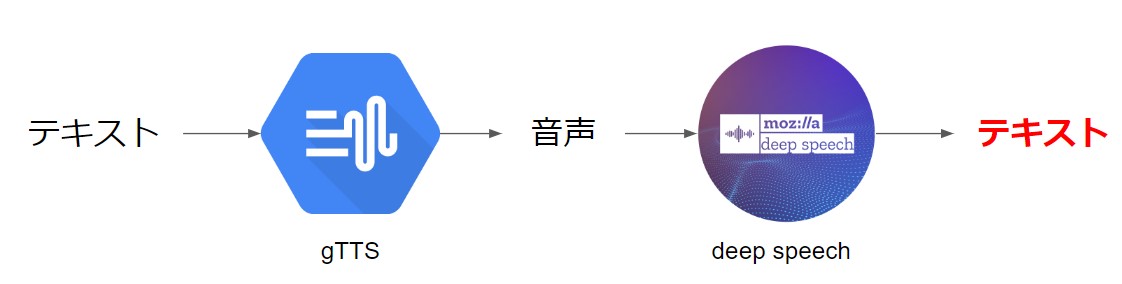
音声認識・合成の分野ではSpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognitionというこちらの研究など、TTSとASRを組み合わせることでそれぞれのモデルのロバスト性を高める研究は多くされているようです。音声対話における言語処理部分にも同様のことがいえて、「for 3 people」が「free people」になってしまうような、音声を介することで、元の文と音は似ているけど違った文章が入力されてしまう、といったケースが考えられます。
近年はEnd-to-Endで、このようなエラーもすべて大規模ニューラルネットワークに学習させてしまうという取り組みも多くされていますが、制御が難しいので従来のパイプライン型のシステムの方が主流です。音声認識の下流にあたる言語理解部はこういった音声認識誤りを許容するようなモデルであることが好ましいので、そのための学習データを生成します。
ちなみに私たちも同じアプローチを以前試していました。詳細はこちらの記事をご参照ください。
4. Speech Disfluency
「Ah」や「uh」などのフィラーや「I, I wan to go…」のような繰り返しを追加します。追加位置はbi-LSTMモデルで予測されます。加えて、いい直しも再現するような機能も備わっています。文章に含まれているスロット値にあたる語を置換し、その直後に「, sorry I mean」と元のスロット値の語を挿入します

論文中の評価
本論文ではMultiWoZ 2.3のNLUタスクを使って評価を行っています。テストデータに対してLAUGを適用し、拡張した1000件に対して人手で元の文意からずれがないかを確認しています。
評価実験結果が以下の表になります。(指標はF1)
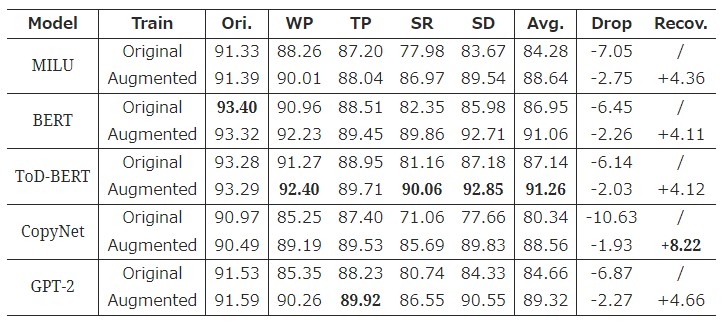
- Model: NLUモデル
- Train:
- Original: 元のtrainデータセットで学習した結果
- Augmented: trainデータセットにLAUGを適用して学習した結果
- Ori.: testデータにLAUGを適用しなかった際の結果
- WP/TP/SR/SD: Word Perturbation/Text Paraphrasing/Speech Recognition/Speech Disfluency
- Avg.: WP/TP/SR/SDの平均
- Drop: Ori.からAvg.がどれだけ下がったか
- Recov.: LAUGによってどれだけ精度が改善したか
どの手法もLAUGで拡張されたテストデータを使うとスコアが低下していますが、学習にもLAUGを使うことで改善しているのがわかります。
BERTとGPT-2に関しては学習時に適用する拡張の割合ごとの比較もされていました。
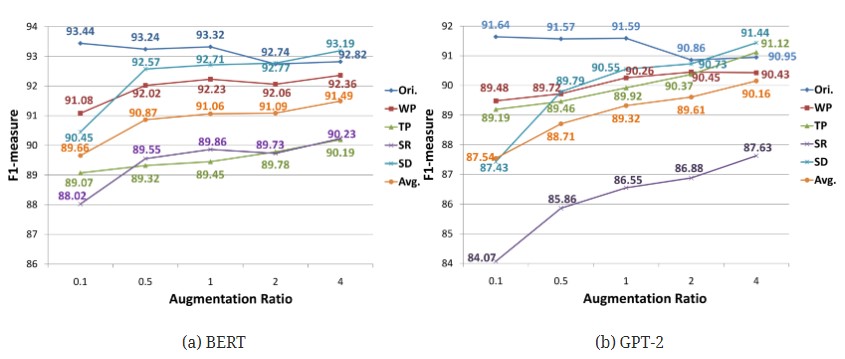
スコアに一番影響を与えるのはSpeech_Recognitionに見えるので、音声認識誤りが一番の課題なようです。これは私たちのプロダクトでも同じことが言えるので納得の結果です。
また、拡張データが多いほど、拡張テストセットでのスコアは増加していますが、BERTの性能は、拡張比率が0.5を超えるとほぼ横ばいとなる一方で、GPT-2は安定的に増加し続けています。この結果は、事前学習が分類ベースモデルなのか生成ベースモデルなのかによる差なのではないかと考察されています。
LAUGを使ってみる
事前準備
LAUGのリポジトリですが、いくつかREADMEに無い準備が必要だったので、ここで共有します
omw-1.4
nltkライブラリでwordnetをダウロードする指示はあるのですが、omw-1.4も必要になってくるので、こちらもダウンロードします
import nltk
nltk.download('omw-1.4')
ASR.py
Speech_RecognitionのためのASRライブラリですが、main処理が適切に処理されていないので、150行目以下を以下に変更します。
class args:
model = "deepspeech-0.9.3-models.pbmm"
scorer = "deepspeech-0.9.3-models.scorer"
audio = None
beam_width = None
lm_alpha = None
lm_beta = None
version = None
extended = None
json = None
candidate_transcripts = 3
hot_words = None
サンプルコード
MultiWoZを対象としたサンプルコードを以下に示します
from LAUG.aug import Word_Perturbation
from LAUG.aug import Text_Paraphrasing
from LAUG.aug import Speech_Recognition
from LAUG.aug import Speech_Disfluency
text = "I want a train to Cambridge" # 拡張対象のテキスト
span_info = [["Train-Infrom","Dest","Cambridge",5,5]] # 対象テキストの意図情報
# 各モジュールの定義
WP = Word_Perturbation('multiwoz')
TP = Text_Paraphrasing('multiwoz')
SR = Speech_Recognition('multiwoz')
SD = Speech_Disfluency('multiwoz')
WP_text,WP_span_info = WP.aug(text,span_info)
print('Word Perturbation:')
print(WP_text)
print(WP_span_info)
TP_text,TP_span_info = TP.aug(text,span_info)
print('Text Paraphrasing:')
print(TP_text)
print(TP_span_info)
SR_text,SR_span_info = SR.aug(text,span_info)
print('Speech Recognition:')
print(SR_text)
print(SR_span_info)
SD_text,SD_span_info = SD.aug(text,span_info)
print('Speech Disfluency:')
print(SD_text)
print(SD_span_info)
以下に出力例を示します(結果はランダムに生成されるので、実行ごとに結果は変わります)
Word Perturbation:
I need a train to Cambridge
[['Train-Infrom', 'Dest', 'Cambridge', 5, 5]]
Text Paraphrasing:
yes i need a train going to cambridge.
[['Train-Infrom', 'Dest', 'cambridge.', 7, 7]]
Speech Recognition:
i want a train to cambridge
[['Train-Infrom', 'Dest', 'cambridge', 5, 5]]
Speech Disfluency:
but i want a train to uh , cambridge
[['Train-Infrom', 'Dest', 'Cambridge', 9, 9]]
文章がシンプルなせいか、Speech Recognitionは結果が変わりませんでしたが、それ以外は元の文と意味は変わらず、うまく拡張できていると思います。
おわりに
本記事ではLAUGによる対話データの拡張手法を紹介しました。
4種類のデータ拡張手法がありましたが、評価実験でも示された通り、Speech_Recognitionが一番キーになってくるのではないかと考えています。今後はこのあたりの堅牢性を高める研究を進めていきたいです。
最後までお読みいただきありがとうございました!




