こんにちは!AIチームの戸田です。
本記事はAI Shift Advent Calendar 2022の1日目の記事です。
本記事では少量データで高精度なテキスト分類モデルを学習できると言われているフレームワークSetFit(Sentence Transformer Fine-tuning)をkaggleの入門コンテスト、Natural Language Processing with Disaster Tweetsで試して、他の手法と比較してみようと思います。
SetFitとは
背景
BERTをはじめとする大規模言語モデルは、fine-tuningによるタスク適用でデータリソースの少ないドメインでもロバストな精度を実現することができると言われていますが、それでもfine-tuningで安定した精度を出すためには数百のデータは必要になってきます。
近年話題になっているGPT-3はfew-shot(5~10、多くても50件程度の学習データ)のテキスト分類タスクで非常に有効な結果を示しています。しかし大量の計算リソースを必要とし、学習するテキストの選択に敏感なため、チューニングが困難であるという課題があります。
手法概要
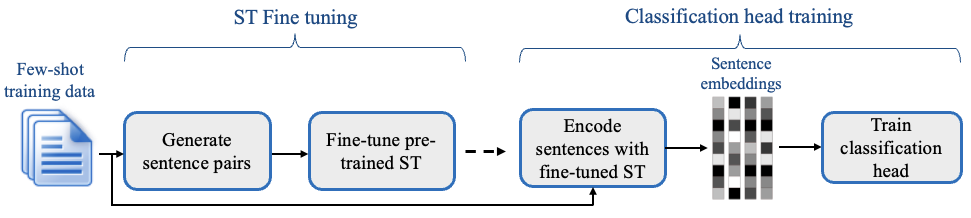
SetFitはSentence Transformerをfew-shotでfine-tuningする手法になっており、ベースとなるSentence Transformerはhuggingface hubなどに公開されている様々なモデルを利用できます。もちろん多言語モデルにも対応しており、フレームワーク作成者らの実験では、ドイツ語、日本語、北京語、フランス語、スペイン語の分類で有望な結果を示したそうです。
手法は2つのステップで構成されています
第一ステップ
分類するクラスの内外のテキストを正と負のペアとして距離学習を行います。これにより、よりタスクに適した文章ベクトル表現を得ることが期待できます。
第二ステップ
第一ステップで学習された文章ベクトルを入力とする分類学習を行います。一般的なfine-tuningと同じような学習になります。
ベンチマーク
SetFitでチューニングしたRoBERTa(SetFit RoBERTa)を RAFT (Real-World Few-Shot Text Classification) というfew-showのテキスト分類のベンチマークに適用して検証し、GPT-3と比較した結果が以下になります。
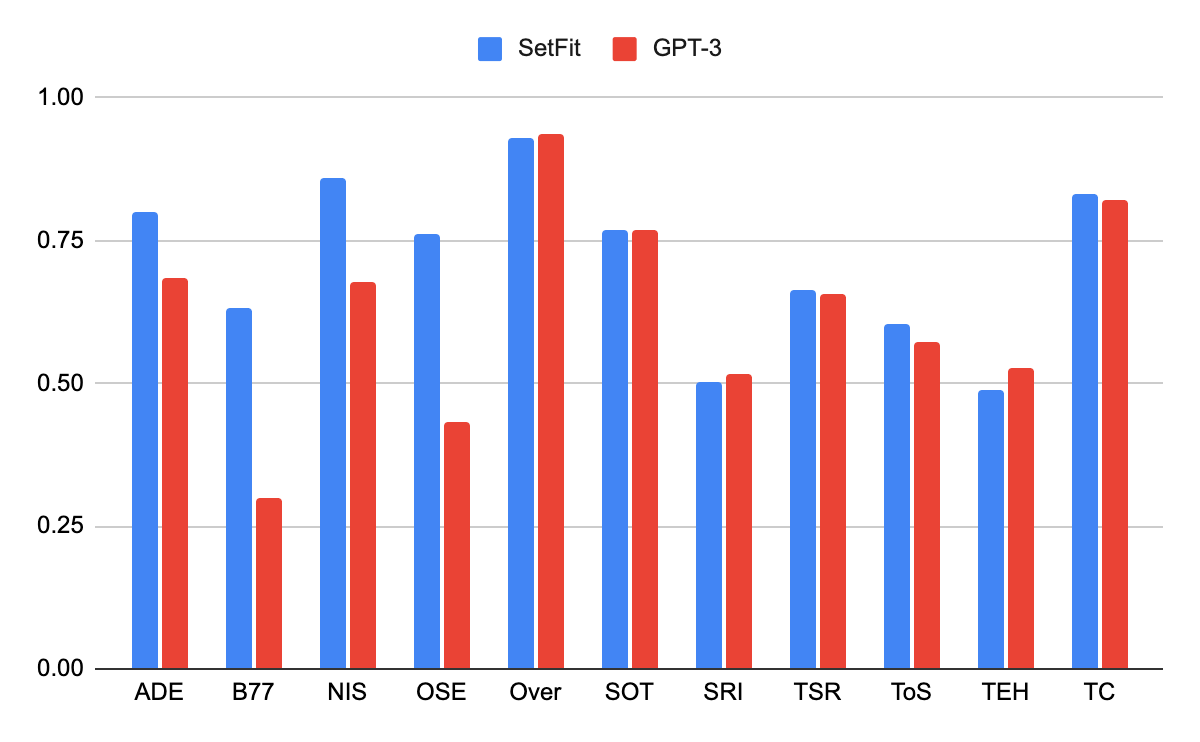
GPT-3のパラメータ数175Bに比べて、SetFit RoBERTaは355Mという極めて小さなモデルであるにも関わらず、RAFTの11タスクのうち7タスクで優れた結果を収めています。
評価実験
Kaggleの入門コンテスト、Natural Language Processing with Disaster TweetsでSetFitを試してみたいと思います。こちらは災害があった際とそうでない時のTweetの分類タスクになります。一見簡単そうに見えますが、例えばablazeという単語は火災などで燃えるという意味がありますが、アトラクションなどで熱狂する、という意味でも使われるため、ある程度文脈を考慮する必要が出てきます。
事前準備
必要なライブラリをimportしておきます。
import pandas as pd
from datasets import Dataset
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitModel, SetFitTrainersetfitライブラリ自体はpipで導入できます。詳細設定などは公式リポジトリをご参照ください。
データ読み込み
データを読み込みます。学習用データは7000件以上ありますが、few-shot学習の実験なので、正例と負例それぞれ4件ずつサンプリングします。
INPUT_ROOT = "[入力データのルートディレクトリ]"
N_SAMPLE = 4 # 各クラスのサンプル数
SEED = 0
train_df = pd.read_csv(f'{INPUT_ROOT}/train.csv')
test_df = pd.read_csv(f'{INPUT_ROOT}/test.csv')
sub_df = pd.read_csv(f'{INPUT_ROOT}/sample_submission.csv')
_train_df = pd.concat([
train_df.query('target==0').sample(N_SAMPLE, random_state=SEED),
train_df.query('target==1').sample(N_SAMPLE, random_state=SEED),
], axis=0)
# 評価用データは学習用にサンプリングしたもの以外からランダムに1000件取得する
_valid_df = train_df[[i not in _train_df.index for i in range(len(train_df))]]
_valid_df_sample = _valid_df.sample(1000, random_state=SEED)SetFitはhuggingfaceのTrainerライクな実装を使って学習を行うので、huggingfaceのデータセットクラスで各データセットを定義する必要があります。
train_dic = {
'text': _train_df['text'].tolist(),
'label': _train_df['target'].tolist(),
}
valid_dic = {
'text': _valid_df_sample['text'].tolist(),
'label': _valid_df_sample['target'].tolist(),
}
train_dataset = Dataset.from_dict(train_dic)
valid_dataset = Dataset.from_dict(valid_dic)モデル定義
モデルと学習用のTrainerを定義します
model_id = "sentence-transformers/all-roberta-large-v1"
num_classes = len(train_dataset.unique("label"))
model = SetFitModel.from_pretrained(
model_id,
use_differentiable_head=True,
head_params={"out_features": num_classes}
)
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
loss_class=CosineSimilarityLoss,
metric="f1",
seed=SEED,
batch_size=32,
num_iterations=20,
num_epochs=1,
column_mapping={"text": "text", "label": "label"}
)パラメータは特にチューニングはしておらず、READMEにあったものをそのまま持ってきています。SetFitにはOptunaを使った自動パラメータチューニング機能もあるので、また別の機会に試してみたいです。
学習
READMEには以下の第一ステップの学習で1e-5程度の小さな学習率、第二ステップの学習で1e-2程度の大きな学習率でチューニングすると経験的に良い結果が得られたとあったので、それにならって学習してみたいと思います。
# 1st Step
trainer.freeze() # 分類ヘッダーをfreeze
trainer.train(body_learning_rate=1e-5, num_epochs=1)
# 2nd Step
trainer.unfreeze(keep_body_frozen=True) # 分類ヘッダーをunfreeze, bodyはfreeze
trainer.train(learning_rate=1e-2, num_epochs=50)2ステップ合わせてCPUで30分程度の学習時間でした。以下のコードでvalidation dataの評価を行います
trainer.evaluate()
# {'f1': 0.7426067907995618}テスト
テストデータに対して予測を行い、コンテストの提出ファイルを作成します
pred = model(test_df['text'].tolist())
sub_df['target'] = pred
sub_df.to_csv('submission.csv', index=None)submitをするとPublic Score 0.75543を得ることができました
他の手法との比較
Leaderboadで近い位置にあるスコアと手法を確認してみました
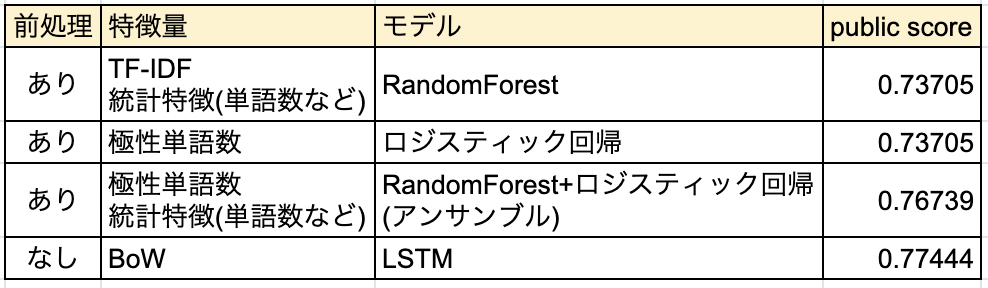
アンサンブルやフルセットのデータを使ったDeep Learningの手法には勝てないようですが、古典的な手法(link1, link2)よりは良い精度が出せているようです。
ちなみに2022年12月1日現在で公開されている最高スコアの手法はBERT Largeを使ったもので、Public Score 0.84370でした。
おわりに
本記事ではfew-shotテキスト分類フレームワークSetFitの紹介とkaggleの入門コンテストへの適用を行いました。
スコア自体は学習データのフルセットを使ったDeep Learning手法には及ばないものの、前処理無しのわずか8件のデータでGPUを使わずに古典的な手法より優れた精度を出すことができたのは衝撃的でした。
AutoMLなどと比較したときにどうなるかも気になるので、またいずれ試してみたいと思います
最後までお読みいただきありがとうございました!
明日はAIチームの二宮からFAQ検索に関する論文の紹介を行う予定です




