こんにちは
AIチームの戸田です
本記事ではオフライン強化学習手法の一つであるDecision Transformerの精度向上のための試行錯誤の結果を共有したいと思います。
タイトルに①とついていますが、今回の内容は長期的な取り組みになりそうなので、シリーズ化しようと考えています。特に今回はstate loss追加の有効性の検証について書かせていただきます。
背景
先日行われた言語処理学会第29回年次大会(NLP2023)で、タスク指向対話システムの方策学習へのDecision Transformerの適用というタイトルでポスター発表をさせていただいたのですが、そこで「Decision Transformerではactionのlossしか計算していないが、stateのlossも計算してみるのはどうか」というご意見をいただきまた。
確かに状態に関しても予測が行えた方が、例えば行動選択を誤ってしまい1つの対話状態が繰り返されていることを検知できるなど、より良い方策が学習できることが期待できそうです。(強化学習に関してはまだ学習中なので、認識が間違っている場合はご指摘いただきたいです)
しかし元論文では特に触れられておらず、著者の実装でも出力としてstateはあるものの、そのlossは計算されていませんでした。なので、stateのlossも計算するとどうなるのかを試してみようと思いました。
私の研究の詳しい発表内容については論文が公開されていますので、そちらをご参照いただければと思います。
Decision Transformer

今回の取り組みで扱うDecision Transformerについて簡単に説明します。元論文はこちらになります。
一般的な強化学習は環境においてエージェントが試行錯誤することで方策を改善します。

しかしオフライン強化学習手法は、事前に用意されたデータセットからの学習だけで、実環境と作用せずに良い方策を獲得することを目的としています。オフライン強化学習は実環境での失敗が許容できないドメインや試行錯誤のコストが高いドメインでの活用が期待されています。

Decision Transformer はモデルのアーキテクチャに GPT をベースとしており、非マルコフ性の問題、つまり将来が現在の状態だけでなく履歴全体に依存してしまう問題を Transformer の Attentionの仕組みで効率よく解くことができると言われています。
実験
NLP2023の発表ではMultiWOZというタスク指向対話のデータセットで実験していたのですが、本記事では問題設定を簡単にするために、強化学習のトイタスクであるHalf Cheetahを使って実験してみたいと思います。
Half Cheetah

Half Cheetahはロボット工学などの高速で正確なシミュレーションが必要な分野の研究開発を促進することを目的とした、オープンソースの物理エンジン、Mujocoで提供されているシミュレーション環境の一つです。
9つのリンクとそれらをつなぐ8つの関節からなる2次元のチーターロボットをできるだけ速く前方(右)に走れるように操作します。
操作できるチーターの行動(action)
チーターの胴体と頭は固定されており、トルクをかけることができるのは、胴体につながる前後の太もも、太ももにつながるすね、すねにつながる足の6つの関節になります。
観測できるチーターの状態(state)
チーターの体の部位の位置値と、その部位の速度などの17要素になります。オプションでチーターの重心の座標を得ることができますが、本記事の実験では使用しません。
環境から与えられる報酬(reward)
前進した距離に応じて正の報酬を、後進した場合は負の報酬を割り当てられます。また極端すぎる行動をとった時にはペナルティが与えられます。
コード
huggingfaceが提供してくれているこちらのコードを利用します。
stateのloss計算を追加するためTrainableDTクラスのforwardのloss計算部分を以下のように変更します。
- loss = torch.mean((action_preds - action_targets) ** 2) # 元のloss計算(actionのみ)
+ loss_a = torch.mean((action_preds - action_targets) ** 2) # actionのloss
+ loss_o = torch.mean((observations_preds - observations_targets) ** 2) # stateのloss
+ loss = loss_a + loss_o # actionとstateのlossを足す結果
評価施行は20回行い、累積報酬の平均をstepごとにplotすると以下のようになりました。
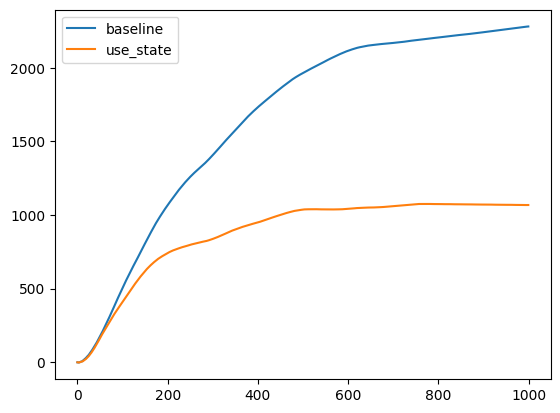
また、最終的に獲得した合計報酬は以下になります
| baseline | use_state |
|---|---|
| 2,279 | 1,067 |
予想に反して、stateのlossを含めると性能が落ちてしまうようです。
追加実験
stateのlossを含めた際に性能が落ちてしまう原因として、stateのlossの方が支配的になってしまい、より良い行動を予測するより、次の状態を予測する方が優先されてしまっているのではないか、と考えました。
そこでstateのlossに重み付けをすることで、より良い行動を予測を優先しつつ、状態の予測の恩恵も取り入れられることを期待し、追加実験を行いました。
実装
元の実験とほぼ同じですが、state lossの計算部分に重みを加えます。
- loss = loss_a + loss_o
+ w = 0.5 # state lossの重み。0.5, 0.25, 0.125, 0.0625で設定
+ loss = loss_a + loss_o * w結果
最初の実験と同様、評価施行は20回行い、累積報酬の平均plotと最終的に獲得した合計報酬は以下のようになりました。

| w=0.0 | w=0.0625 | w=0.125 | w=0.25 | w=0.5 | w=1.0 |
|---|---|---|---|---|---|
| 2,279 | 3,131 | 4,455 | 2,719 | 1,798 | 1,067 |
baselineはw=0.0、use_stateはw=1.0に相当します。
state lossに重みをかけると、性能がよくなっているように見えます。
重みと性能の関係を見るために、横軸に重み、縦軸に最終獲得報酬を取り、エラーバー付きでグラフを書いてみたら以下のようになりました。
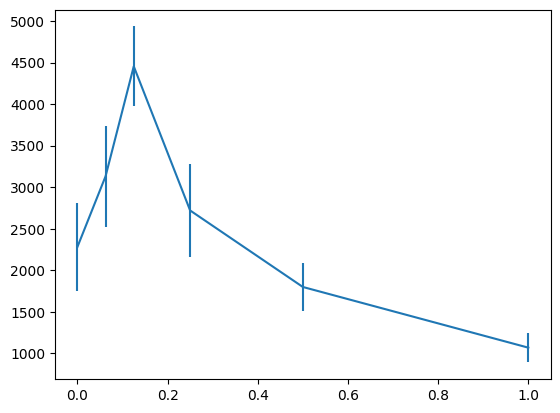
w=0.125あたりにピークがありそうにみえますね。
おわりに
本記事ではオフライン強化学習手法の一つであるDecision Transformerの精度向上のための試行錯誤の一つとしてstate lossの追加の結果を共有させていただきました。結果、state lossをそのまま追加しても性能は逆に下がってしまいましたが、state lossに重み付けして追加することで、性能向上させることができました。
今回のHalf Cheetahの環境はstateが17次元、actionが6次元だったので、他の割合の環境だとどうなるのか、その割合とstate lossにかける重みの違いなどを検証してみたいです。
またDecision Transformerはaction, stateに加えてreturn-to-go(その時点での累積報酬)も入出力に含まれているので、こちらのlossを計算するとどういう結果になるのかも気になります。
引き続き実験を続けていきたいと思います。
最後までお読みいただきありがとうございました!
余談
本記事は最近話題のChatGPT(GPT 3.5-turbo)にレビュー、修正案を出してもらいながら書かせていただきました。言葉遣いが思いつかなかった場合に提案してもらったり、説明不足な点などをその場で指摘してもらえて非常に便利でした。これからも可能な限り積極的に活用していきたいです。




