はじめに
こんにちは、AIチームの杉山です。前回の私の記事ではチャットボットなどの自動応答システムにおけるOOD(out-of-domain)の問題と、関連する研究を紹介しました。今回の記事では、その中で触れたID-OOS(in-domain but out-of-scope)についての紹介と、関連する研究としてEMNLP2022のIndustry Truckに採択されたDistinguish Sense from Nonsense:Out-of-Scope Detection for Virtual Assistants[1]という論文を紹介します。なお、こちらの論文はIBM Watson, Apple所属の共著となっており、実プロダクトで適用・検証を行なっていることが報告されています。
チャットボットや音声アシスタントにおけるID-OOS
まず、前回の記事よりOODについて説明した箇所を引用します。
testチャットボットや音声アシスタントなどのユーザーからの入力クエリに対して回答する自動応答システムでは、大きくEnd-to-End型とパイプライン型が存在します。現時点では制御の柔軟性などの理由からエンタープライズ用途においては一般的にパイプライン型が用いられることが多く、その場合は入力クエリの意図(インテント)を推定し、推定された意図に対応する応答を選択して返答します。
意図推定モデルは意図の信頼度スコアだけでなく、入力クエリがシステムの対象外(OOD)である可能性も出力することが期待されます。
入力クエリがOODと判断できると、問い返しなどを行って質問の明確化を行ったり、「分かりませんでした、別の言い方でお願いします」のようにフォールバック応答することでタスクを完了に近づける手段を取ることができます。
OODの検出は2クラス分類タスクとしてモデル化することができ、システムの対象外および対象内(in domain、 以降ID)の2カテゴリに分類することで実現できます。良いUXを与えたりユーザーを失望させずQAシステムとして信頼を得るためには、回答できる質問には正しく回答しつつOOD検出器の精度を保つというトレードオフを達成することが重要になります。
このように、実際の自動応答プロダクトを提供する際には、ユーザーからのクエリがシステムとして回答できるかどうかを判別できることが重要で、それにより回答可能な範囲(ドメイン)外である場合には、fallbackして言い換えを依頼したりオペレーターにエスカレーションするなどしてUXを保つことが期待できるため、これまで様々な研究が行われています。
次に、以下のように用語を定義します。
in-domain(ID), out-of-domain(OOD): 自動応答システムが扱うと思われる問い合わせの範囲の内外。企業用カスタマーサポート向けチャットボットであれば対象のサービスに関する事柄などがID、「今何時?」のような雑談や提供していないサービスに関する問い合わせなどがOODにあたる。
in-scope(IS): 自動応答システムが回答可能な範囲
out-of-scope(OOS): 自動応答システムが回答不能な範囲(先日の論文ではOOD)
また、プロダクトを運用していく上ではオペレーターへのエスカレーションなどの人間の介入を抑えてシステムだけで解決できる割合(論文ではcontainment rate)を高めることが重要です。containment rateは実際にプロダクトを運用してからでないと計測できないため、オフライン指標としてIS/OOSの分類精度などを用います。しかし、実世界にプロダクションされたサービスでは、ID/OODのバランスが大きく偏っていたりノイズが含まれていたりするなど、より細分化した問題を考慮する必要があります。
加えて、実際のカスタマーからの入力は、ISはもちろん、一部のいたずらや攻撃などを除きOOSにおいてもIDであることが一般的です。
そのようなOOSクエリは、異なるドメインに属する比較的容易なOOSクエリであるout-of-domain OOS(OOD-OOS)に対して、in-domain OOS(ID-OOS)と呼ばれます。[2]
そのため、自動応答システムにおいては、ISなクエリとの意味的重複が高くても(ドメインが同じでも)、正しくID-OOSを検出することが重要となりますが、OOS検出のShared Taskなどではこの点が考慮されていません。よく行われるようなクエリの意味的埋め込みを用いたIS/OOSの2クラス分類ではドメインが同じである性質上分類が難しいため、実際のプロダクトにおいてはこの点を注視したアルゴリズムが必要になります。
エンティティとOOS検出
エンティティはユーザーのクエリから名詞を特定するために設計され、自動応答システムが適切に対応するために重要です。
学術的にはあまり研究されていませんが、実際には以下にいくつか例を示すように注意深く設計する必要があります。
専門用語
学習に用いる一般的なコーパスの語彙から外れた特別な用語をエンティティとして定義することで、意味のわからない単語を含む文章と区別するようなOOS検出方法が必要となります。
同義語
OOS検出アルゴリズムは、同じエンティティの同義語が多数あっても、同様の検出スコアを生成することが期待されます。
数値
日付、数値、時間などの一般的なエンティティ(システムエンティティ)は、幅広い概念をカバーするために必要ですが、システムエンティティに万能なソリューションはありません。例えば、数字のシステムエンティティ「11」は、ドメイン固有の用語「オペレーティングシステムWindows 11」や「iPhone 11」の一部である可能性があるため、OOS検出アルゴリズムはこれらのシステムエンティティについて文脈に基づいて決定する必要があります。
OOS検出アルゴリズム
OOS検出アルゴリズムは大きく1段階/多段階の2種類に分けられます。
1段階OOS検出
すべてのISクラスとOOSクラスを一緒に使用し、入力クエリがISクラスの1つに属するか、もしくはOOSであるかを決定するための単一のモデルを訓練する方式で、大きく2つの方針があります。
多クラス分類
このアプローチでは、ISクラスと並んでOOSの例を追加クラスとして扱い、IS意図検出とOOS検出の両方の多クラス分類モデルを学習します[3][4]。実際には、このアプローチはOOSクラスの分類において学習データにoverfitする可能性があり、未見のOOSクエリにうまく一般化できない可能性があります。また、大幅なクラス不均衡が存在する場合、失敗する可能性が高くなります。
出力分布を利用したIS分類
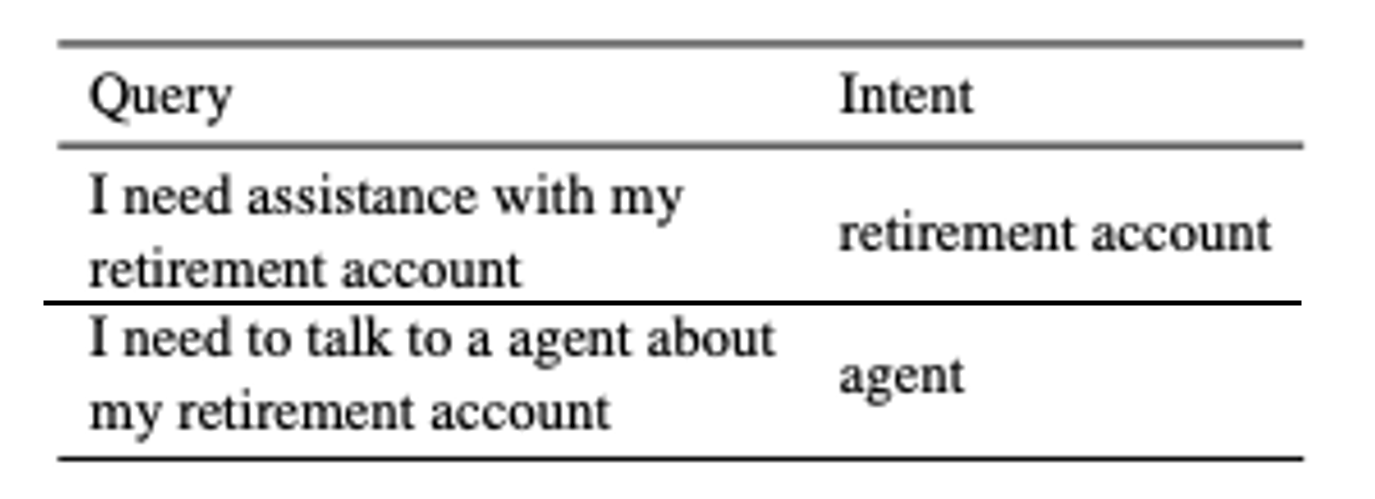
このタイプの手法は、Anomaly DetectionのようにOOSクエリに対して低い最大確率または高いエントロピーの確率ベクトルを出力する分類器をISデータで訓練します[5]。しかし、実際の訓練データには表1に示すようにシステムを誤解させ不必要な人間の介入を増加させるような意味的に重複したインテントを有していることが多いという問題があります。
多段階OOS検出
多段階OOS検出方式では、まずクエリがISかOOSかを2クラス分類器で判定し、OOSでなければ次にISのインテントのうち、どれが最も近いかを判断します。
2クラス分類(IS/OOS)
IS/OOSのデータを使って2クラス分類器を学習し、ユーザーのクエリがOOSかISかを判別します。OOSの訓練データがない場合、1クラス分類器や他の教師なし手法で置き換えることができます。
IS分類+内部(隠れ状態)表現による教師なし手法
ISクラスのデータに基づいて分類器を訓練し、IS分類器の内部表現(ニューラルネットワークの隠れ層の結合など)を、オートエンコーダーなどの教師なしOOS検出アルゴリズムに利用する。
提案手法
この論文では、先に述べた他のアプローチの問題を軽減しシステムの性能を向上させるために、多段階OOSの改善策を提案しています。
提案手法:Binary Classification(IS/OOS) discounting on In Scope scoresは、OOS分類を以前の定式化と同様に2クラス分類問題として扱いますが、OOS検出アルゴリズムの分類スコアを最終的なISスコアを割引するために使用します(詳細は後述)。
OOS分類はISとOOSの両方の訓練例(ラベルがある場合)の文埋め込みに基づく距離ベースのアプローチで、学習時には先述したエンティティの前処理を行った後に、文の埋め込みを行います。各IS例について、その文埋め込みと対応する意図クラスの平均埋め込みの線形結合を用いて、コサイン類似度による近似最近傍検索を行います。その際最近傍サンプルとのコサイン距離をOOSスコアとして使用し、以下のようにIS分類器からの出力を割り引きます。
最近傍がOOSの場合、対応する最近傍距離に追加の定数を追加し、信頼度をより割り引くようにします。
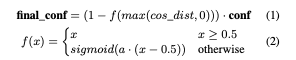
ベンチマークデータセット
提案手法の有効性を評価するために、表2のデータセットを用いて実験を行います。
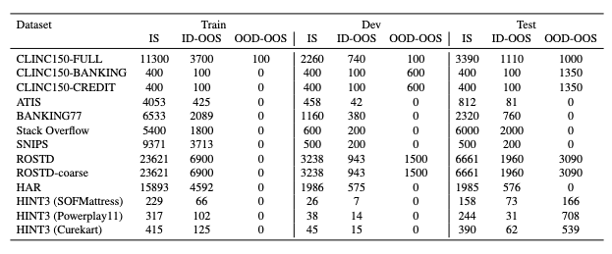
ID-OOS検出に関する手法の性能を評価するために、すべてのデータセットにID-OOS例が含まれるようにする操作として、ISの例しかないデータセットについては、ランダムにISのインテントを選んでOOSとして扱い、これらのインテントのデータ数が学習データセット全体の約25%になるようにしています。その他詳細な操作については元論文の付録A.1をご覧ください。
実験結果
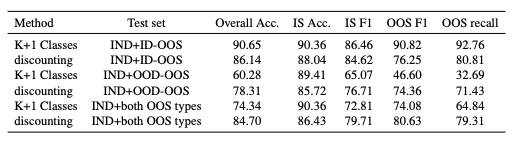
提案手法と従来手法を比較するために、ベンチマークデータセットで実験を行った結果が表3で、提案手法はほとんどのメトリクスで従来手法を上回る結果となっています。

表4はすべてのデータセットについてID-OOS/OOD-OOSを区別した際の、マルチクラス定式化と提案手法を比較した結果です。(IND+both OOS typesは表3の実験設定と同様)
提案手法は、ID-OOSでは同程度の性能を保ちながら、OOD-OOSに対してはより良く一般化できていると考えられます。実際のアプリケーションでは、運用前の学習時に顧客から提供されるID-OOSは限られていますが、アルゴリズムはオーバーフィットすることなく両方のタイプで良い性能を示すことが期待できます。
終わりに
今回の記事では、タスク指向対話システムにおけるout-of-scope (OOS)の問題設定と、新しい検出手法を紹介しました。問題設定が自動応答システムを用いたビジネスを前提としていることもあり、Chatbot/Voicebotを提供している身としてとても参考になりました。
また、今回の紹介の趣旨からは外れるため割愛しましたが、論文中では実サービスに適用した際のオンライン評価や、運用を鑑みたモデルの計算効率とスケーラビリティについての言及があるなど、実際のプロダクトで自動応答システムを提供する著者ららしい検証もなされており、そちらの面でも学びがありました。
以上、ここまで読んでいただきありがとうございました。
参考
[1] Distinguish Sense from Nonsense: Out-of-Scope Detection for Virtual Assistants
[2] Are Pre-trained Transformers Robust in Intent Classification? A Missing Ingredient in Evaluation of Out-of-Scope Intent Detection
[3] Out-of-Scope Intent Detection with Self-Supervision and Discriminative Training
[4] OutFlip: Generating Out-of-Domain Samples for Unknown Intent Detection with Natural Language Attack
[5] D2U: Distance-to-Uniform Learning for Out-of-Scope Detection




