こんにちは
AIチームの戸田です
本記事ではオフライン強化学習手法の一つであるDecision Transformerの精度向上のための試行錯誤の結果を共有したいと思います。
今回の内容は長期的な取り組みになりそうなので、シリーズ化しています。前回の記事は以下になります。実験の背景やDecision Transformer自体についてはこちらをご参照いただければと思います。
- Decision Transformer 精度向上実験① 〜state lossの有効性についての検証〜
- Decision Transformer 精度向上実験② 〜複数環境でのstate lossの検証〜
前回までの実験ではaction lossに一定の重み付けをした値を超えないようにstate lossを追加することで、異なった環境であっても安定した精度改善が見込めることがわかりました。
元々最適化しているaction lossや前回実験したstate lossに加えて、Decision Transformerはreturn-to-go(その時点で期待される終端状態での報酬和)も入出力に含まれているので、こちらのlossを計算するとどういう結果になるのかを検証した結果を本記事で共有します。
実験
これまでと同様、Edward Beeching氏が公開してくれているDecision Transformer向けの学習データ(half cheetah, hopper, walker2)を利用して実験してみたいと思います。
学習コードはhuggingfaceが公開しているこちらのnotebookをベースに作ります。
state lossと同様、action lossに一定の重み付けをした値を超えないようにreturn-to-go lossを追加するようにし、重みの範囲を探索しました。
コード修正箇所
return-to-goのloss計算を追加するためTrainableDTクラスのforwardのloss計算部分を以下のように変更します。
- loss = torch.mean((action_preds - action_targets) ** 2) # 元のloss計算(actionのみ)
+ loss_a = torch.mean((action_preds - action_targets) ** 2) # actionのloss
+ loss_r = torch.mean((return_preds - return_targets) ** 2) # return-to-goのloss
# action lossにかける重み。1.0, 0.5, 0.25, 0.125, 0.0625, 0.0の範囲で探索
+ w = 0.5
# return-to-go lossをaction lossに一定の重み付けをした範囲を超えないようにclippingする
+ loss_r = torch.clamp(loss_r, max=loss_a.item() * w)
+ loss = loss_a + loss_r # actionとreturn-to-goのlossを足す結果
これまでの実験と同様に、横軸にreturn-to-go lossをclippingするための基準に使うaction lossへのせる重み、縦軸に累積報酬の平均と標準誤差をバーで加えたグラフを示します。
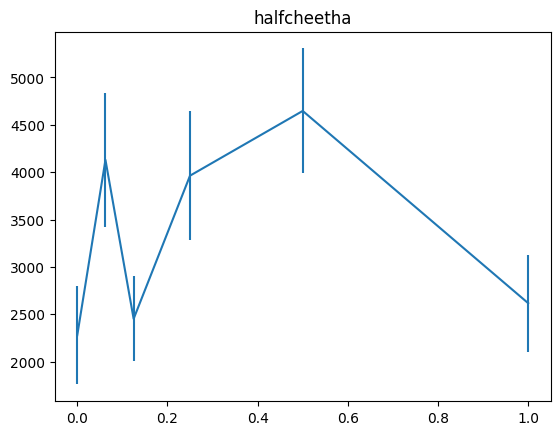
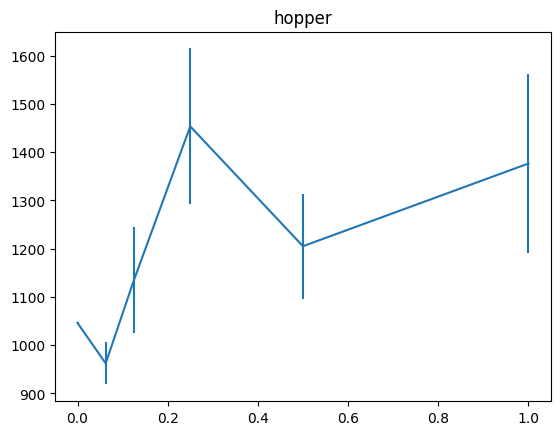
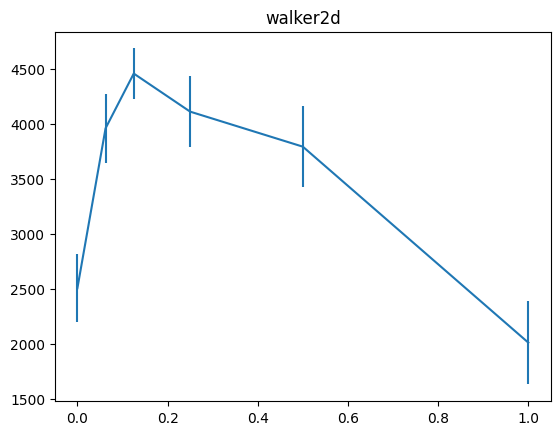
state lossの時は重みw=0.125付近で、どの環境もstate lossを使わない時のほぼ2倍の累積報酬になっていたのですが、return-to-goの場合は、w=0.25の時にそれがきているようです。
考察
state lossの時も見られた傾向なのですが、hopperは他の2つの環境に比べて、return-to-go lossを大きめにとっても精度が向上し続ける傾向にあります。actionの次元数をみてみると
- half cheetah: 6次元
- hopper: 3次元
- walker2: 6次元
と次元数が少なく、またhopperは他タスクと比べてepisode end条件が厳しいため、episodeが途切れやすいという特徴があります(参考動画)。もっと多くの環境を試してみないとわかりませんが、こう言った特徴が関係しているのではないかと考えています。
おわりに
本記事ではオフライン強化学習手法の一つであるDecision Transformerの精度向上のための試行錯誤の一つとして、return-to-go loss追加の結果を共有させていただきました。
state lossと同様、action lossを基準として一定の重み付けをした範囲を超えないようにreturn-to-go lossを追加することで精度改善が見込めることがわかりました。
今後はstate lossとreturn-to-go lossを同時に加えた場合どうなるのか、また今回はタスクの練度が高いexpertのデータを使いましたが失敗したデータを混ぜたケースなどもどうなるのか検証したいです。
最後までお読みいただきありがとうございました!




