
こんにちは、AIチームの戸田です。
LLMの隆盛に伴い、近年注目を集めているRAG(Retrieval-Augmented Generation)は問い合わせに対して、FAQなどの知識ベースの情報を参照しながらLLMに回答を生成させる質問応答のフレームワークの一種です。
RAGは関連情報を検索するRetrieverと、それに基づいて回答を生成するGeneratorの2つのモジュールで構成されます。ChatGPTが注目を集めている現在、Generatorに関心が行きがちですが、私はRetrieverの方が全体の性能に大きな影響を与えると考えています。Retrieverが適切な情報を取得できなければ、たとえ最先端のGeneratorを備えていても、その能力は十分に発揮されないからです。
本記事では以前作成したFAQ評価データを使って、代表的なベクトルベースのRetrieverの比較を行ってみようと思います。
比較手法
さまざまなベクトル化手法があるのですが、今回は以下の3つの手法を試したいと思います。
OpenAI Ada
AdaはOpenAIの提供するEmbedding(ベクトル化)モデルの一つで、LangChainやLlamaIndexなどの多くのLLMフレームワークのRetrieverにおいて、デフォルト設定としてよく使われています。
import openai
text = {ベクトル化対象テキスト}
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=text
)
vec = response['data'][0]['embedding']Japanese SimCSE
SimCSEは対照学習(Contrastive Learning)によって、従来の事前学習モデルより良いベクトル表現を得られるように学習されたモデルになります。特にJapanese SimCSEはこちらの論文で提案された日本語で学習されたSimCSEになります。今回検証に利用するモデルはJapaneseEmbeddingEvalでJGLUEの性能が最も良いcl-nagoya/sup-simcse-ja-largeを利用します。以下のようにSentenceTransformersを介して簡単にベクトル化を実現することができます。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('cl-nagoya/sup-simcse-ja-large')
text = {ベクトル化対象テキスト}
vec = model.encode(text)TF-IDF
TF-IDFは古典的な文章特徴量です。インターネット上に多くの解説記事がありますので、本記事では詳しく説明しません。今回はscikit-learnのTfidfVectorizerをデフォルトパラメータで利用し、日本語分かち書きにはjanomeを利用しました。
from sklearn.feature_extraction.text import TfidfVectorizer
from janome.tokenizer import Tokenizer
t = Tokenizer(wakati=True)
def wakati(text):
tokens = t.tokenize(text)
return " ".join(list(tokens))
corpus = {検索対象文章のlist}
queries = {問い合わせ文章のlist}
corpus = [wakati(i) for i in corpus]
vectorizer = TfidfVectorizer()
faq_vecs = vectorizer.fit_transform(corpus)
queries = [wakati(i) for i in queries]
query_vecs = vectorizer.transform(queries)評価
上記3つのベクトル化手法でRetrieverの評価を行います。評価するデータセットは、以前公開させていただきました、
LLMを利用したFAQ検索の評価データセットの作成〜その2〜
こちらの記事で作成したデータセットを使います。データセットはhuggingface hubにアップロードしており、以下のような形で読み込むことができます。
from datasets import load_dataset
# LLMで生成したユーザーの想定質問
query_dset = load_dataset("ai-shift/ameba_faq_search")
# 検索対象のFAQデータ
faq_dset = load_dataset("ai-shift/ameba_faq_search", data_files={"faq": "target_faq.csv"})FAQデータにはTitleとContentの2つの要素がありますが、今回はこの2つを結合したものを検索対象としました。
精度検証
各手法で問い合わせをベクトル化し、同じくベクトル化したFAQとのcos類似度を計算することで、問い合わせに対する正しい解答となるFAQを予測します。以下にベクトル化以降で共通となる処理を示します。検証するスコアはPrecision At N です(N = 1 or 3 or 5)。
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
test_dset = query_dset['test'] # testデータで評価
faq_ids = np.array(faq_dset['faq']['ID'])
query_vecs = {ベクトル化されたクエリ群}
faq_vecs = {ベクトル化されたFAQ}
predicts = []
for idx, d in tqdm(enumerate(test_dset), total=test_dset.num_rows):
sim = cosine_similarity(query_vecs[idx, ].reshape(1, -1), faq_vecs)[0] # cos類似度の計算
rank = sim.argsort()[::-1] # 類似度の降順でソート
p = np.where(d["ID"] == faq_ids[rank])[0][0] # 予測では正しいFAQが何位か
predicts.append(p)
predicts = np.array(predicts)
p_at_1 = ((predicts + 1) <= 1).mean()
p_at_3 = ((predicts + 1) <= 3).mean()
p_at_5 = ((predicts + 1) <= 5).mean()
print(f"{p_at_1=:.4}, {p_at_3=:.4}, {p_at_5=:.4}")各手法の結果を以下にまとめます。
| P@1 | P@3 | P@5 | |
| OpenAI Ada | 0.5006 | 0.6953 | 0.7730 |
| Japanese SimCSE | 0.3608 | 0.4994 | 0.5603 |
| TD-IDF | 0.5544 | 0.7491 | 0.8435 |
意外ですが、古典的なTF-IDFを使った手法が最も良い精度を示しています。これは検索対象であるFAQの文章と問い合わせ文の長さが大きく異なるからではないかと考えました。試しにそれぞれの文章の長さをヒストグラムにしてみると以下のようになりました。
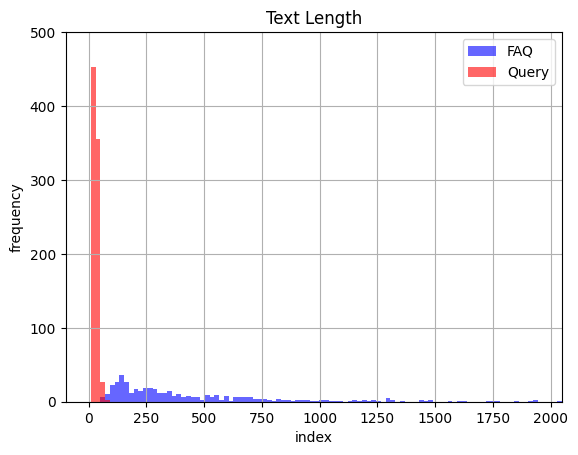
確かに文章の長さに大きな乖離が見られることが確認できました。
LlamaIndexなどに実装されているベクトルベースのRetrieverでは、これを回避するために検索対象の文章を一定の長さに区切って検索対象(チャンク)として格納する、という手法をとっています。これはFAQのように整理されていないPDF文章などを丸投げすることができるという利点もあるのですが、一方で文章構造を考慮できないので、解答部分の文章が切れてしまったり、前後の文脈を考慮すると本来は関係ない文章が類似文として扱われてしまう、といった問題も起こり得ます。どちらか片方の手法にこだわるのではなく、検索対象文章に応じて手法の切り替えや組み合わせなどが必要なのではないかと考えています。
ちなみにこの辺りの課題感はABEJAさんのTechBlogにわかりやすくまとめていただいているので、より深掘りしたい方はこちらを参照いただければと思います。
おわりに
本記事では近年注目を集めているRAGの重要な構成要素であるRetrieverについて、ベクトルベースの手法を以前作成したFAQ評価データを使って比較してみました。
Retrieverには今回試した手法の他にもKnowledgeGraphの仕組みを使ったものや、取得したものをリランキングする手法(Retrieve and Reranking)もあり、まだまだ検証する余地はありそうです。また先日公開されましたOpenAIのKnowledge Retrievalも性能が良いと噂なので、こちらも比較してみたいです。
最後までお読みいただきありがとうございました!




