
こんにちは、AIチームの戸田です
本記事はAI Shift Advent Calendar 2023の8日目になります
以前、FAQ検索におけるベクトルベースのRetrieverの比較を行いましたが、本記事ではその続編として、ベクトルベースのRetrieverを特定のドメインに適応するように学習して、精度が改善するのかを見てみたいと思います。
学習について
一言にRetrieverの学習といっても、検索対象の文章の整形だったり、類義語の辞書登録など様々な手法が考えられますが、今回は特にニューラルネットワークベースのベクトル化モデルにおいて、用例を使ってベクトル空間をタスクのドメインに寄せる学習について検証してみようと思います。
前回扱ったJapanese SimCSEのように手元にベクトル化モデルをダウンロードできる手法とOpenAI AdaのようにAPIを利用してベクトルを取得する手法の両方について、それぞれ実際に学習して精度の変化を見てみます。
事前準備
評価には以前作成したAmebaブログのFAQ検索評価データを利用します。
from datasets import load_dataset
# LLMで生成したユーザーの想定質問
query_dset = load_dataset("ai-shift/ameba_faq_search")
# 検索対象のFAQデータ
faq_dset = load_dataset("ai-shift/ameba_faq_search", data_files={"faq": "target_faq.csv"})ベクトル化モデルをダウンロードできる場合
手元にベクトル化モデルをダウンロードできる場合、モデルを学習させる手法として代表的なものは、ドメインテキストでMLM(masked-language model)などのpre-trainの追加学習を行うものや、ContrastiveLossを使うものがありますが、今回はMultipleNegativesRankingLossを利用したいと思います。この手法は負例を複数使用するため、埋め込み空間内での類似性と非類似性を、他の手法より良く捉えることができると言われています。学習手法の詳細についてはこちらの論文やこちらの実装などが参考になると思います。
まずはデータセットを整形します。
from torch.utils.data import DataLoader
from sentence_transformers import InputExample
from sentence_transformers.evaluation import InformationRetrievalEvaluator
BATCH_SIZE = 8
faq_df = faq_dset["faq"].to_pandas()
# 学習用データ
examples = []
for d in query_dset['train']:
row = faq_df.query(f"ID=='{d['ID']}'").iloc[0]
example = InputExample(texts=[d["Query"], row.Title]) # 検索対象はTitleとする
examples.append(example)
loader = DataLoader(
examples, batch_size=BATCH_SIZE
)
# 評価用データ
corpus = {row.ID: row.Title for _, row in faq_df.iterrows()} # 検索対象はTitleとする
queries, relevant_docs = {}, {}
for i, d in enumerate(query_dset["validation"]):
qid = f"query_{i:04}"
relevant_docs[qid] = [d["ID"]]
queries[qid] = d["Query"]
evaluator = InformationRetrievalEvaluator(queries, corpus, relevant_docs, show_progress_bar=True)以前の記事ではTitleとContextを連結したものを検索対象としていましたが、今回は計算リソースの都合上、Titleのみにしています。
このデータセットを使ってMultipleNegativesRankingLossを使ったRetrieverのベクトル表現を学習していきます。今回もJapaneseEmbeddingEvalでJGLUEの性能が最も良いcl-nagoya/sup-simcse-ja-largeをベースモデルとします。
from sentence_transformers import SentenceTransformer
from sentence_transformers import losses
MODEL_NAME = 'cl-nagoya/sup-simcse-ja-large'
EPOCHS = 2
WARMUP_RATE = 0.1
model = SentenceTransformer(MODEL_NAME)
loss = losses.MultipleNegativesRankingLoss(model)
warmup_steps = int(len(loader) * EPOCHS * WARMUP_RATE)
model.fit(
train_objectives=[(loader, loss)],
epochs=EPOCHS,
warmup_steps=warmup_steps,
output_path='exp_finetune',
show_progress_bar=True,
evaluator=evaluator,
evaluation_steps=50,
)パラメータは決めうちです。対象テキストをTitleに絞っているのでGPUでなくても実行できると思います。
APIを利用してベクトルを取得する場合
OpenAI AdaのようにAPIを利用してベクトルを取得する場合は、モデルの重みを更新するような学習をすることはできません。そこで取得したベクトルを1層のLinear Adapterに通すようにし、そのLinear Adapterの重みを学習することで、ベクトル表現をドメインに寄せていこうというアプローチをとることになります。こちらはLlamaIndexのEmbeddingAdapterFinetuneEngineという機能で簡単に実装できます。
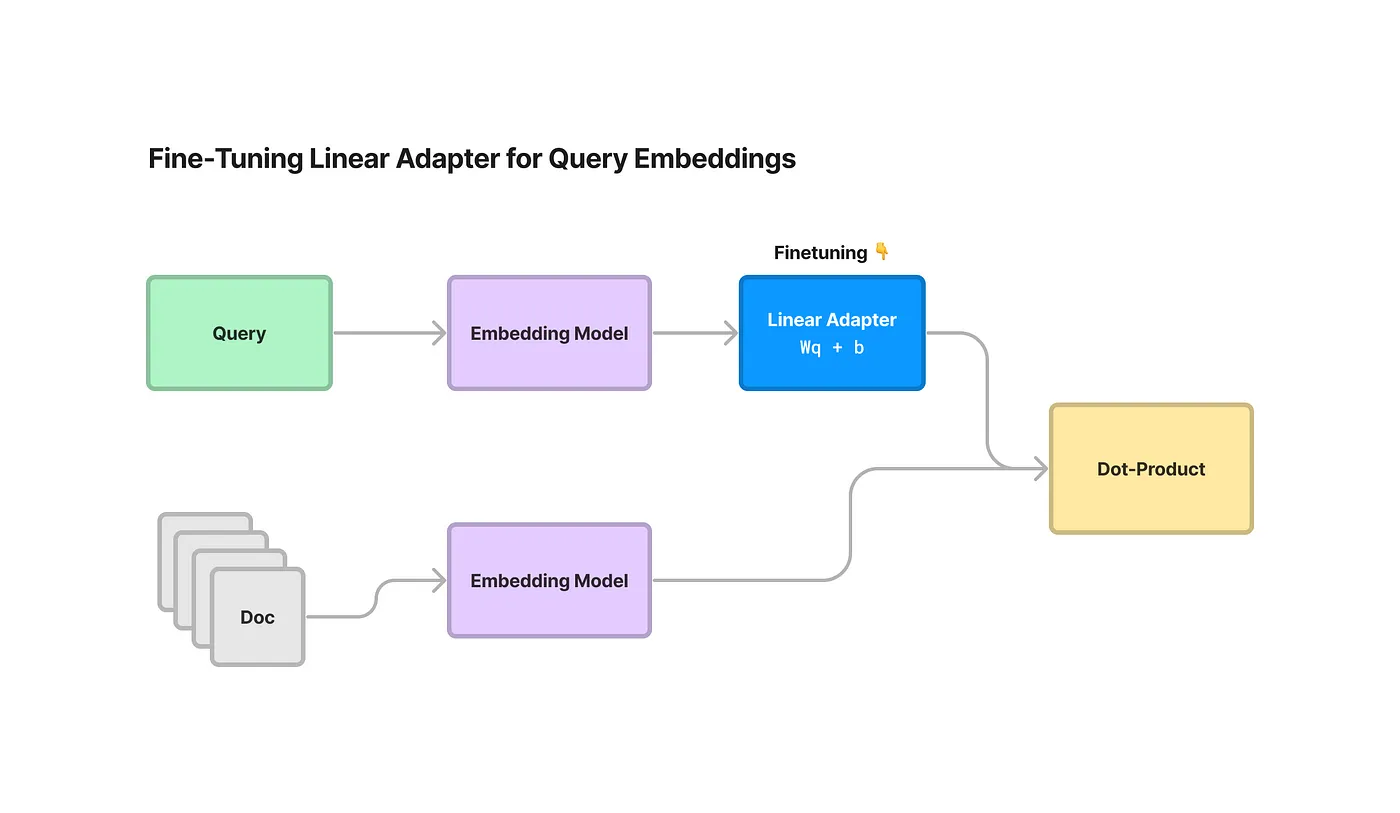
学習コードは以下のようになります。
from llama_index.embeddings import OpenAIEmbedding
from llama_index.finetuning.embeddings.common import EmbeddingQAFinetuneDataset
from llama_index.finetuning import EmbeddingAdapterFinetuneEngine
# 環境変数にOpenAI APIのKeyを設定しておく
# データセットの定義
corpus = {row.ID: row.Title for _, row in faq_df.iterrows()} # 検索対象はTitleとする
queries, relevant_docs = {}, {}
for i, d in enumerate(query_dset["train"]):
qid = f"query_{i:04}"
relevant_docs[qid] = [d["ID"]]
queries[qid] = d["Query"]
train_dataset = EmbeddingQAFinetuneDataset(corpus=corpus, queries=queries, relevant_docs=relevant_docs)
# モデルの定義
base_embed_model = OpenAIEmbedding()
finetune_engine = EmbeddingAdapterFinetuneEngine(
train_dataset,
base_embed_model,
model_output_path="./tuning_ada",
epochs=4,
verbose=True,
)
# 学習
finetune_engine.finetune()評価結果
それぞれの手法の学習前と後の結果は以下のようになりました。比較するための精度は前回と同様、Precision at Nです。
| P@1 | P@3 | P@5 | |
| Japanese SimCSE | 0.3608 | 0.4994 | 0.5603 |
| Japanese SimCSE (学習) | 0.4397 | 0.6022 | 0.6667 |
| OpenAI Ada | 0.3704 | 0.5137 | 0.5735 |
| OpenAI Ada (学習) | 0.5221 | 0.7145 | 0.7957 |
ベクトル化モデルをダウンロードできるケースでも、APIを利用するケースでも精度が向上していることがわかりました。特にAdaの向上はすごいですね。
おわりに
本記事ではベクトルベースのRetrieverのドメイン適応による精度改善の比較に取り組みました。Linear Adapterを追加する手法はAdaのようなfine-tuningに対応していないモデルにも利用でき、学習コストも低いので積極的に活用していきたいです。
AI Shift の開発チームでは、AI チームと連携して AI/LLM を活用したプロダクト開発を通し、日々ユーザのみなさまにより素晴らしい価値・体験を届けるべく開発に取り組んでいます。
AI Shift ではエンジニアの採用に力を入れています!この分野に少しでも興味を持っていただけましたら、カジュアル面談でお話しませんか?(オンライン・19 時以降の面談も可能です!)
【面談フォームはこちら】
明日は開発責任者をしている青野の記事が公開される予定です。
最後までお読みいただきありがとうございました!




