
こんにちは、AIチームの二宮です。
この記事はAI Shift Advent Calendar 2023の11日目の記事です。
本記事では、OpenAIのAPIを使ってRAG(Retrieval Augmented Generation) を実装し、画面上でプロンプトを設定して対話してみます。その後、エンジニアが行う実装とプロンプト作成業務を分離する方法について紹介します。
背景
カスタマーサポートにおけるRAGの活用
ChatGPTの登場により、カスタマーサポート分野でも積極的にその活用が進んでいます。
現在、特に注目されているRAGは、自社情報などの任意の情報(本記事ではKnowledge DBと記します)を検索して得られた文書を生成時に活用することができます。
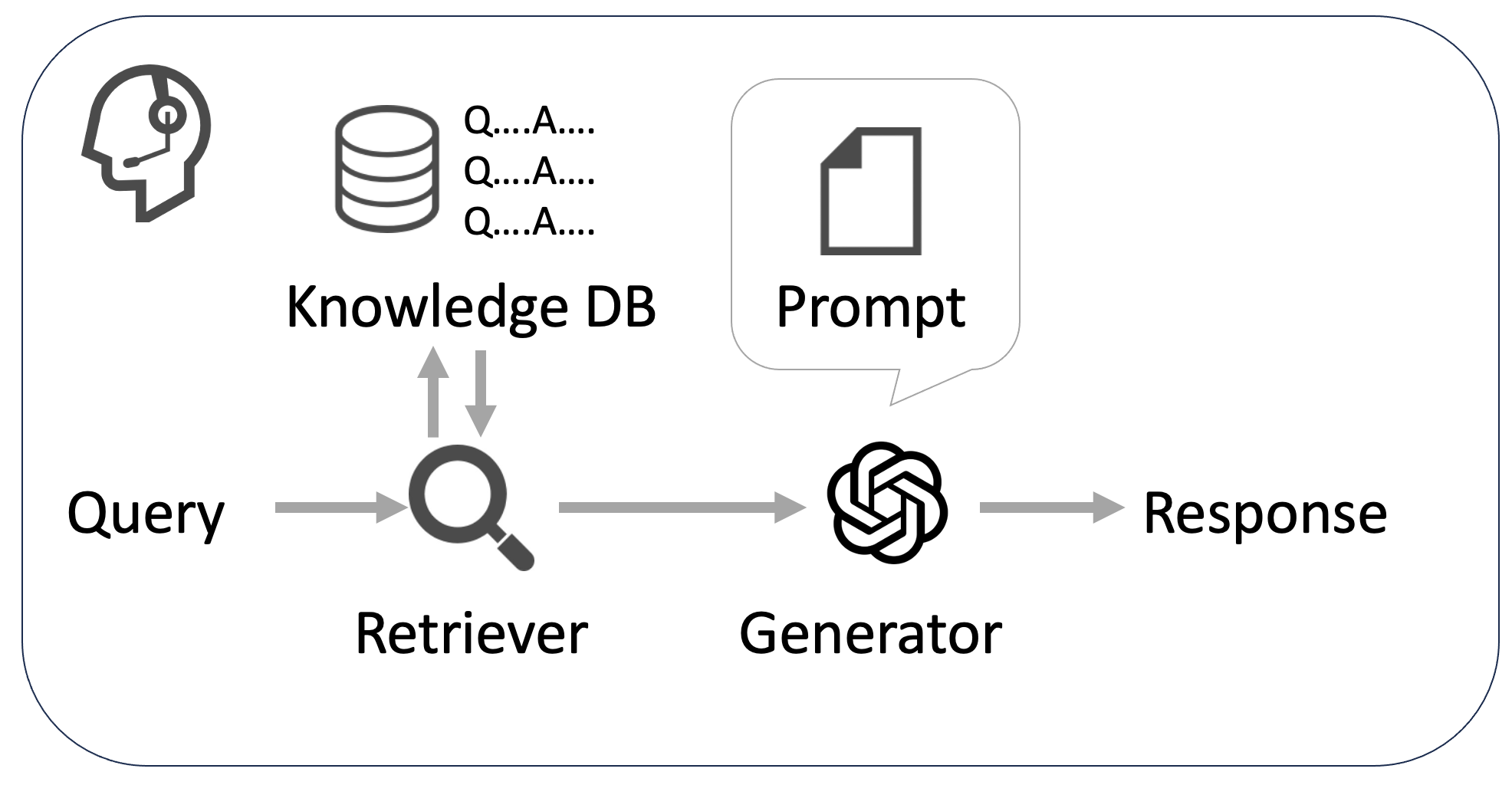
RAGは、情報検索部分(Retriever)と回答生成部分(Generator)から構成されています。Retrieverは入力に関連する情報をKnowledge DBから取得し、それをもとにGeneratorが回答を生成します。この時Generatorはプロンプトという指示文が与えられており、それに沿った生成を行います。
ChatGPTは最新情報を学習していなかったり、自社情報に乏しかったりするため、カスタマーサポートでは社内マニュアルや自社のホームページ情報などに基づいて回答するチャットボットとして活用することが考えられ、弊社でもお客様の情報を用いてRAGの効果を検証しています。
チャットボットのデモ
RAGの実装
今回は以前のブログで取り上げたAmebaのFAQに関するデータを用いて、カスタマーサポートの簡易的なチャットボットを作ってみます。
まずは必要なモジュールを読み込みます。
pip install openai
pip install langchain
pip install chromadb
pip install gradio
pip install datasets
pip install tiktokenRetrieverはテキストのベクトル化にOpenAIのEmbeddingモデル、ベクトルデータベースにはChromaを使い、LangChainを用いると以下のように実装できます。
from langchain.vectorstores import Chroma
from langchain.document_loaders import DataFrameLoader
from langchain.embeddings.openai import OpenAIEmbeddings
class ChromaRetriever:
def __init__(self):
self.embeddings = OpenAIEmbeddings(api_key="<YOUR_OPENAI_API_KEY>")
self.index = Chroma(
persist_directory="./",
embedding_function=self.embeddings,
)
def create_index(self, df):
loader = DataFrameLoader(df, page_content_column="Title")
documents = loader.load()
self.index = Chroma.from_documents(documents, self.embeddings, persist_directory="./")
def retrieve(self, query):
self.index = Chroma(
persist_directory="./",
embedding_function=self.embeddings,
)
return self.index.similarity_search(query, k=3)
retriever = ChromaRetriever()今回はAmebaのFAQに関するデータをKnowledge DBとして利用します。このデータはよくある質問集の質問と答えのペアが含まれますが、今回は単純にそれらを改行で連結してChromaに登録します。
from datasets import load_dataset
query_dset = load_dataset("ai-shift/ameba_faq_search")
faq_dset = load_dataset(
"ai-shift/ameba_faq_search", data_files={"faq": "target_faq.csv"}
)
df = faq_dset["faq"].to_pandas()
df["body"] = df["Title"] + "\n" + df["Content"]
retriever.create_index(df)次に、GeneratorはOpenAIのgpt-3.5-turboを利用します。
from openai import OpenAI
class OpenAIGenerator:
def __init__(self):
self.client = OpenAI(api_key="<YOUR_OPENAI_API_KEY>")
def generate(self, query, history, documents, prompt):
documents_str = "\n---\n".join(
[document.page_content for document in documents]
)
prompt = prompt.replace("#DOCUMENTS#", documents_str)
messages = [{"role": "system", "content": prompt}]
for h in history:
if h[0] is not None:
messages.append({"role": "user", "content": h[0]})
if h[1] is not None:
messages.append({"role": "assistant", "content": h[1]})
messages.append({"role": "user", "content": query})
response = self.client.chat.completions.create(
model="gpt-3.5-turbo",
temperature=0.7,
messages=messages,
)
return response.choices[0].message.content
generator = OpenAIGenerator()最後に、RetrieverとGeneratorを順に実行するRAGの関数を定義します。そして、Gradioを使ってUIを表示してみます。
import gradio as gr
def rag(query, history, prompt):
documents = retriever.retrieve(query)
response = generator.generate(query, history, documents, prompt)
history.append([query, response])
return query, history, documents
with gr.Blocks() as demo:
with gr.Row():
with gr.Column(scale=0.3):
prompt = gr.TextArea(label="プロンプト", lines=35)
with gr.Column(scale=0.7):
with gr.Row():
with gr.Column(scale=0.7):
chatbot = gr.Chatbot(label="チャット", height=450)
with gr.Column(scale=0.3):
documents = gr.TextArea(label="検索結果", lines=20)
with gr.Column():
msg = gr.TextArea(label="入力")
with gr.Row():
with gr.Column(scale=0.5):
btn = gr.Button(value="送信", variant="primary")
btn.click(
rag,
[
msg,
chatbot,
prompt,
],
[msg, chatbot, documents],
)
with gr.Column(scale=0.5):
clear = gr.ClearButton([msg, chatbot, documents], value="クリア")
demo.launch(server_name="0.0.0.0")プロンプトを変えながらRAGを試す
それでは、ブラウザ上で0.0.0.0を表示し、プロンプトに以下を設定して対話してみます。
(#DOCUMENTS#はRetrieverで検索された文書に置換されます。)
カスタマーサポートのオペレーターとして、以下の情報にのみ基づいて回答してください。
---
#DOCUMENTS#
---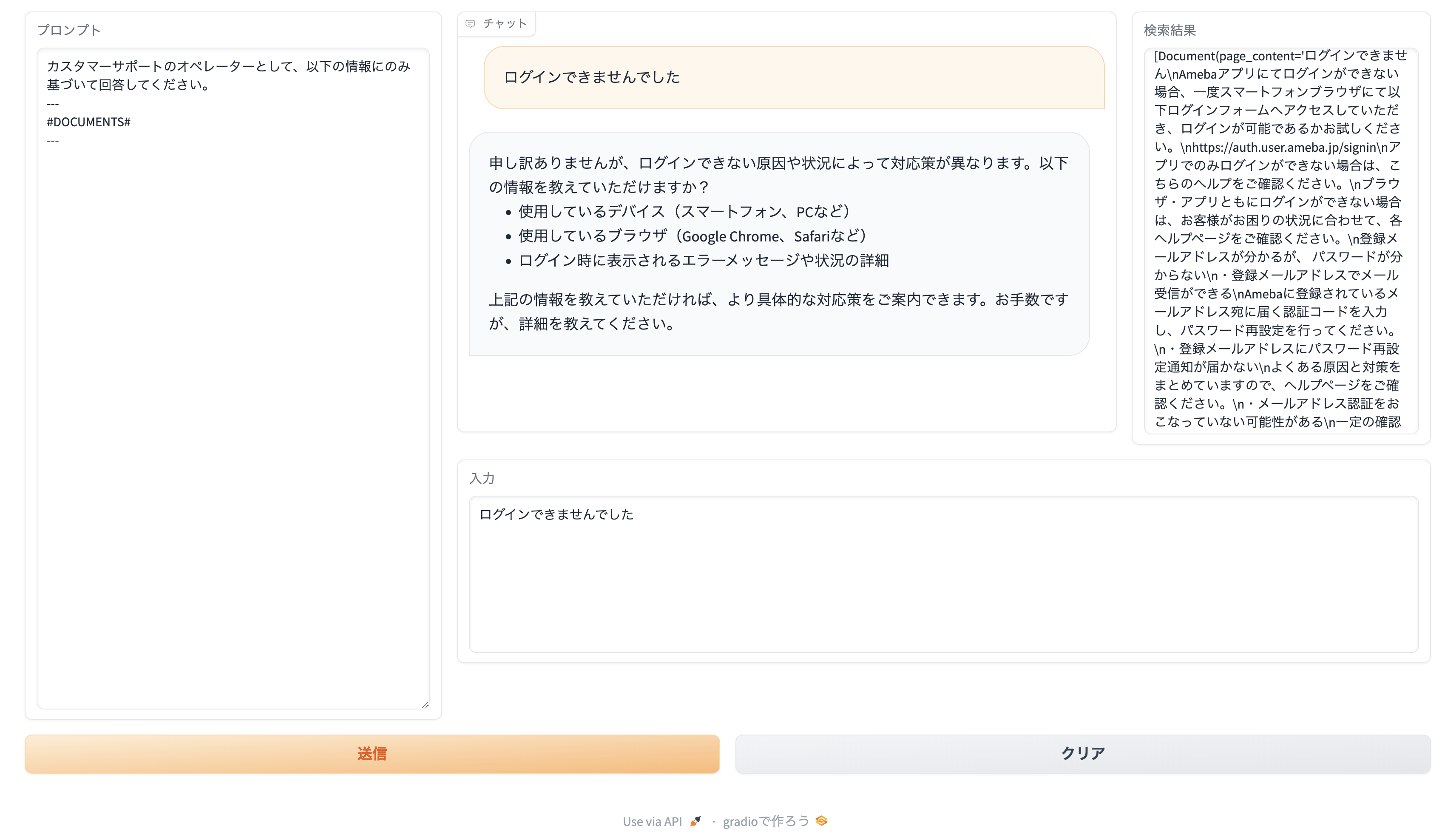
上手く検索された内容に基づいて回答することを確認できました。Retrieverの検索結果を確認すると、どの情報を元に回答したのかがわかります。
また、動作検証を繰り返し行う中でプロンプトを編集したい場合があります。今回はプロンプトに以下を追加して実行してみます。
可能な限り短文で伝えてください。すると、以下のような応答になりました。
Amebaアプリにログインできない場合は、スマートフォンブラウザにて以下のログインフォームへアクセスしてみてください。https://auth.user.ameba.jp/signin
ログインができるか試してみてください。このようにプロンプトを変えながら対話をすることでRAGの効果検証を素早くできます。
ここまでに行ったRAGのデモと類似した内容は、OpenAI Playgroundでも試すことが可能です。ただし、使用するモデルやKnowledge DBを必要に応じて変更したり、ログを出しながら処理を確認したりする際には、今回のようなデモが有益であると考えています。
また、今回は特別な処理を加えずに、基本的なRAGを試しました。しかし、RAGには精度や速度の面で多くの改善案が考えられます。以下にその例を挙げます。
- 他の検索手法やモデルを用いる
- 対話履歴も用いて検索する
- Knowledge DBで扱うデータを変更する
- 入出力前後に特定の処理を加える
- OpenAIのFunction CallingやAssistants APIを用いる
- Streaming処理を行う
- マルチモーダルな入出力にする
実装とプロンプト作成業務の分離
PoCを通した経験
今回のデモではユーザーが画面上からプロンプトを変更できるようにしました。この利点として、プロンプトの設計をエンジニアでない方でも行えるようになる点が挙げられます。
これまで弊社ではRAGの実装とプロンプトの作成をエンジニアが行っておりました。しかし、契約先ごとに予想される質問は多様で、それぞれにおいて十分な動作検証とそれに基づくプロンプトの修正が必要となります。しかし、これらを限られたエンジニアのみで行っていると、プロンプトの作成に関する知見が蓄積されず、エンジニアが技術的な課題に取り組むことができない状態となっていました。
設計担当者の任命
これを考慮し、弊社ではLLMに関する設計を専門とする担当者を任命しました。その方にはプロンプトとKnowledge DBの修正を担当していただきました。
なぜKnowledge DBまで修正する必要があるかというと、RAGの動作検証時にプロンプトの修正だけでは不十分な事例が多々存在したためです。例えば、特定のフレーズを発言しないようにしたいが、Knowledge DBに記載されている場合はそのフレーズを生成してしまうことがありました。これはより高性能なモデルに変更することで改善される場合もあるのですが、事業上は費用の観点からそのモデルを選択しなければならない場合もあります。
実装とプロンプト・Knowledge DBの作成業務を分離することで、以下のメリットがあったと考えています。
- 設計の担当者によりプロンプトとKnowledge DBの作成に伴う知見を蓄積することができる
- エンジニアはより技術的な課題に専念できる
- 設計の担当者が契約先の要望を直接ヒアリングして、そのままプロンプトの改善に活かせる
特に3点目について、設計の担当者が要望をヒアリングすることができれば、プロンプトの修正にそのまま活かせるため、認識のずれによる手戻りも小さくなると考えています。
スプレッドシートを用いた設計
まず、エンジニアは初期設計としてプロンプトとKnowledge DBをスプレッドシートに記入します。その後、担当者にはそれらを編集してもらいました。そして、担当者が記入した内容はPython側から以下のように呼び出されます。詳細はこちらの記事を参考にさせていただきました。
from oauth2client.service_account import ServiceAccountCredentials
scope = [
"https://spreadsheets.google.com/feeds",
"https://www.googleapis.com/auth/drive",
]
credentials = ServiceAccountCredentials.from_json_keyfile_name(
"<YOUR_CREDENTIALS_PATH>", scope
)
sheet_name = "sheet_name"
client = gspread.authorize(credentials)
sh = client.open_by_key("<YOUR_SPREADSHEET_ID>")
worksheet = sh.worksheet(sheet_name)スプレッドシートを選択した理由は、エンジニアではない作業者にとって使いやすいツールだったためです。弊社ではエンジニアだけでなく営業の方もスプレッドシートを日常的に利用しているため、導入するハードルが低かったことが挙げられます。さらに、スプレッドシートには編集履歴が残るため、データの復元も可能です。動作検証と修正を繰り返し行う必要があるため、この点は重要視しました。
以上が、実装とプロンプト等の作成業務を分離する取り組みについての紹介になります。ただし、これらの取り組みは一概に全ての状況に適用可能なものではなく、弊社の事業状況などを考慮した結果になります。例えば、LLMやその周辺技術がより高精度で低コストに利用できるようになれば、Knowledge DBの修正は不要かもしれません。またプロンプトの作成業務を外部に委託する選択肢もあります。
最後に
弊社では、LLMを用いたプロダクトの開発に力を注いでいます。その開発体制をさらに向上させるための方法を、今後も積極的に探求していくつもりです。将来的にLLMに関する設計業務がどの程度必要なのかを予測することは難しいですが、契約いただいたお客様と真剣に向き合い、お客様の課題を少しでも解消できるようなプロダクトの開発に尽力します。
ここまでお読みいただきありがとうございました。
今回記したRAGの設計に加え、RAGの自動評価の活用につきまして、12/13~12/14に開催される対話システムシンポジウムで発表いたします。そちらもご確認いただけますと幸いです。
AI Shiftではエンジニアの採用に力を入れています!
少しでも興味を持っていただけましたら、カジュアル面談でお話しませんか?
(オンライン・19時以降の面談も可能です!)
【面談フォームはこちら】
明日はAIチームの二宮より、12/13~12/14に開催される対話システムシンポジウムで発表いたします、RAGの自動評価の活用についてご紹介いたします。
どうぞよろしくお願いいたします。




