こんにちは、AI Shiftの東です。 この記事はAI Shift Advent Calendar 2023の7日目の記事です。
本記事では、Cloud Run Jobsとfaster-whisperを使って簡易的な音声認識システムを作ります。
はじめに
Whisperはオープンソースで公開されている汎用的な音声認識モデルで、実行環境を構築すれば自由に利用可能です。また、APIの形式でも提供されており、気軽に利用することもできますが、社内の音声データを入力する際にAPIを使うには以下の点で課題があります。
- データのプライバシーの問題
- Azure OpenAI ServiceのAPIの利用制限
弊社で収集・管理している音声データは基本的にユーザー・ボット(またはオペレーター)間の通話記録であり、住所や氏名、声紋情報などの個人情報が多く含まれます。OpenAIが提供している(エンタープライズ向けの)APIでは、入力されたデータは学習に利用されない設定になっています。しかし、入力データは最大30日間保存され、不正利用がないか監視を行う等の目的で社員によって確認される可能性があり、セキュリティ面を気にされるクライアントの方の導入障壁になってしまいます。
そのため、WhisperやGPT-3.5/4をはじめとするOpenAIのサービスを利用する際は、不正利用監視の設定をオフにできるAzure OpenAI Service(以下、Azure)上で管理されたAPIの利用が候補として挙げられます。
しかし、現時点ではAzureのWhisper APIは一部のリージョンでしか公開されておらず、1分間に利用できる回数も大幅に制限されているため、多くの音声データを処理するにはまだ現実的な選択肢ではありません。
以上の理由から、多くの個人情報を含む音声データに対し、Whisperによる音声認識を行うには実行環境を整備する等の設計作業が必要になります。本記事では、Google Cloud Platform(以下、GCP)が提供するマネージドなサービスであるCloud Run Jobsを用いてWhisperによる簡易的な音声認識システムを作成し、推論速度及び費用面の検証をしていきます。
また、Whisperは高速な推論を可能にするCTranslate2というライブラリを用いて再実装されたfaster-whisperを利用します。
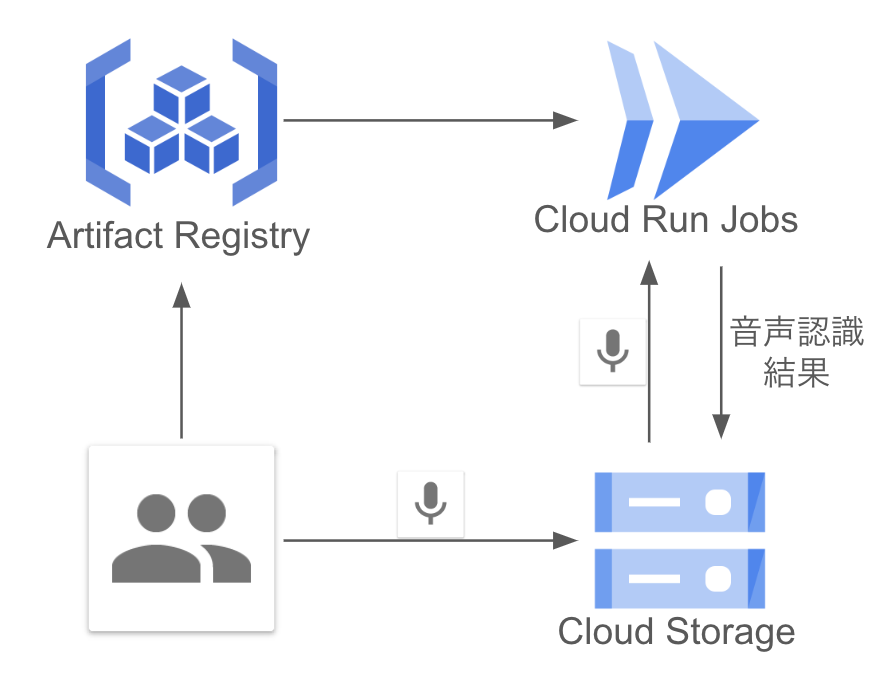
GCPの設定、準備
まずは音声データと認識結果を格納するためのバケットを作成します。
gcloud storage buckets create gs://${BUCKET}次に、今回作成するDockerコンテナを格納するためにArtifact Registry上にリポジトリを作成します。
gcloud artifacts repositories create ${REPOSITORY} --repository-format=docker \
--location=${LOCATION} --description=${DESCRIPTION}続いて、Cloud Run Jobsを起動するためのコンテナを作成します。今回はCloud Buildを用いてローカル環境のデータをビルドし、 Artifact Registry リポジトリに保存するようにします。実装は後述しますが、ファイル構成は以下のようになります。
├── src
│ ├── Dockerfile
│ ├── cloudbuild.yaml // Cloud Build用の設定ファイル
│ └── main.py // 実行スクリプトFROM python:3.10.6-slim
RUN apt-get update && apt-get install -y \
build-essential \
gcc \
git \
ffmpeg \
&& rm -rf /var/lib/apt/lists/*
# 必要なライブラリのインストール
RUN pip install --upgrade pip && \
pip install -r google-cloud-storage==2.10.0 pandas==2.1.0 \
transformers[torch]==4.33.0 faster-whisper==0.8.0
# 実行ファイルのコピー
ENV APP_HOME /app
WORKDIR $APP_HOME
COPY main.py ./
# Whisperのモデル変換
RUN ct2-transformers-converter --model openai/whisper-large-v2 --output_dir whisper-large-v2-int8 \
--copy_files tokenizer.json --quantization int8
CMD ["/usr/local/bin/python3", "main.py"]steps:
- name: 'gcr.io/cloud-builders/docker'
args: [ 'build', '-t', '${LOCATION}-docker.pkg.dev/${PROJECT}/${REPOSITORY}/${IMAGE}:latest', '.' ]
options:
machineType: 'E2_HIGHCPU_32'
images: ['${LOCATION}-docker.pkg.dev/${PROJECT}/${REPOSITORY}/${IMAGE}:latest']作業用ディレクトリ(src)直下でCloud Buildを実行し、コンテナを作成します。
gcloud builds submit --config cloudbuild.yaml .最後に、保存されたアーティファクトを用いてJobの作成、実行を行います。
gcloud run jobs create ${JOB} \
--image '${LOCATION}-docker.pkg.dev/${PROJECT}/${REPOSITORY}/${IMAGE}:latest' \
--region ${LOCATION} \
--set-env-vars BUCKET=${BUCKET} \
--task-timeout 3600s \
--cpu ${CPU_NUM} --memory ${MEMORY_SIZE} \
--execute-now実装
import io
import os
import pandas as pd
from google.cloud import storage
from faster_whisper import WhisperModel
INCOMING_PREFIX = "incoming"
PROCESSED_PREFIX = "processed"
def speech2text(blob, model):
audio_data = blob.download_as_bytes()
segments, info = model.transcribe(
io.BytesIO(audio_data),
language="ja",
task="transcribe",
vad_filter=True,
without_timestamps=True,
)
processed = []
for segment in segments:
processed.append({"start": segment.start, "end":segment.end, "transcription":segment.text})
df = pd.json_normalize(processed)
return df
def main():
# 環境変数の取得
bucket_name = os.getenv("BUCKET")
# モデルの読み込み
model = WhisperModel("whisper-large-v2-int8", device="auto", compute_type="int8", local_files_only=True)
client = storage.Client()
bucket_obj = client.bucket(bucket_name)
for blob in client.list_blobs(bucket_name, prefix=f"{INCOMING_PREFIX}/"):
# フォルダの場合はスキップ
if blob.name.endswith("/"):
continue
# faster-whisperを用いた音声認識
df = speech2text(blob, model)
# 処理後結果をprocessedフォルダに格納
bare_name = blob.name[len(INCOMING_PREFIX)+1:].rsplit(".", 1)[0]
csv_new_name = f"{PROCESSED_PREFIX}/csv/{bare_name}.csv"
# 結果の保存(CSV)
csv_blob = bucket_obj.blob(csv_new_name)
csv_blob.upload_from_string(df.to_csv(index=False), 'text/csv')
if __name__ == "__main__":
main()
今回の実装では、バケット内の指定のフォルダ(incoming)内の音声データを一つずつ処理し、指定したフォルダ(processed)に認識結果を格納するようにしています。
speech2text()ではGCSから取得した音声データを受け取り、認識結果をdataframeとして返し、main()では認識結果をcsvファイルに変換し結果をGCSに格納します。
今回の実装では考慮していませんが、Cloud Run Jobsでは同じタスクを実行するインスタンスの数を指定して並列で処理することができます。各インスタンスにはCLOUD_RUN_TASK_INDEXという環境変数が与えられるので、そのインデックスを使用して異なる音声ファイルを割り当てることで、効率的に音声認識が行えます。
実行結果
サンプルデータとして1分間の長さの音声データを用いて実行速度、費用の計測を行いました。インスタンスのCPU数、メモリサイズを変更して比較した結果、以下のようになりました。
| CPU数/メモリサイズ | 実行時間(秒) | 金額 |
| 1CPU/4GB | 155 | 0.0040$ |
| 2CPU/4GB | 75.8 | 0.0048$ |
| 2CPU/8GB | 91.5 | 0.0048$ |
| 4CPU/4GB | 44.6 | 0.0036$ |
| 4CPU/8GB | 65.3 | 0.0057$ |
| 4CPU/16GB | 84.8 | 0.0088$ |
| 8CPU/8GB | 34.0 | 0.0060$ |
| 8CPU/16GB | 33.8 | 0.0054$ |
| Azure OpenAI Service | 6.53 | 0.0060$ |
実行速度はAPIに遠く及びませんが、推論コストはAPI単価を下回る設定がいくつか見受けられました。
もちろん音声データ内の音声/非音声の割合によっても計測結果に変動は起こり得ますが、1日に数回程度バッチ処理を行い、かつ認識結果が確定するまでのタイムラグにある程度余裕を持たせられるタスクであれば、今回の構成で比較的低コストで処理を行えそうです。
さいごに
ここまで読んでいただきありがとうございました。
AI Shift では、AI チーム、開発チームが連携して AI/LLM を活用したプロダクト開発を行い、ユーザのみなさまにより素晴らしい価値・体験を届けるべく日々開発に取り組んでいます。
AI Shift ではエンジニアの採用に力を入れています!少しでも興味を持っていただけましたら、カジュアル面談でお話しませんか?(オンライン・19 時以降の面談も可能です!)
【面談フォームはこちら】
明日の Advent Calendar 8 日目の記事は、AIチームの戸田による記事の予定です。こちらもよろしくお願いいたします。




