
こんにちは、AIチームの戸田です
近年注目を集めている大規模言語モデル、ChatGPTやClaudeなどのAPIから利用できるサービスはもちろんですが、最近はMetaのLlama2などのオープンモデル、つまりLocalにダウンロードして使うことのできるモデルの開発も活発です。
オープンモデルを試すには強力なGPU環境が必要です。例えばLlama2 70Bモデルを動かすとなると、GPUのメモリは80GB以上は必要になってきます。しかし現在GPUは不足していると言われており、ハードウェアはもちろんのこと、クラウドサービスでもなかなかA100のような十分なスペックを持つGPUを確保することが困難です。量子化などのテクニックはありますが、70Bクラスになるとこれにも限界があります。
私が以前参加したKaggleのコンペティション、LLM Science Examではsimjeg氏によって、LLMの層ごとに推論処理を行うことで、メモリ16GBのT4上でもPlatypus2-70B-instructの推論を行う手法の提案がありました。
airllmはこのアプローチを参考にし、シンプルなインターフェースで使えるようにしてくれたライブラリです。理論上GPUのメモリはなんと4GBでよいと言われています。
今回はこのairllmを使ってT4上でmeta-llama/Llama-2-70b-chat-hfの推論を試してみたいと思います。
インストール
pipで簡単にインストールできます。airllmは量子化も組み合わせることができるので、bitsandbytesも一緒にインストールしておくと良いです。
pip install -U airllm bitsandbytesモデルの読み込み
基本的なインターフェースはtransformersのAutoModel.from_pretrainedと同様で、モデルIDを指定して読み込みを行います。
from airllm import AirLLMLlama2
model = AirLLMLlama2(
"meta-llama/Llama-2-70b-chat-hf",
compression='4bit',
hf_token="<自身のhuggingface tokenを設定>",
delete_original=True,
)AutoModel.from_pretrainedにない要素があるので説明します。
- compression: 4bitか8bitでモデルの量子化を指定することができます。デフォルトはNoneで、量子化なしになります。
- hf_token : Llama2のようにモデルのダウンロードにhuggingfaceトークンが必要な場合はここで設定します。
- delete_original : Trueに設定すると、ダウンロードしたオリジナルのhuggingfaceのモデルは削除して、airllm用に変換されたモデルのみを保持するようになります。
この他にも上記では設定していないオプション引数があるので、詳細はリポジトリのREADMEをご覧になってください。
気をつけなければならないのは、GPUのメモリはT4で十分ですが、モデル自体を保存するディスク容量は確保する必要があるということです。加えてLlamaベースのモデルしかサポートしていないので、Llama2やMistralは動作しますが、Falconのような異なるアーキテクチャのモデルには使えないようです。
推論
推論もtransformersと同様のインターフェースで行うことができます。
まずは入力文章のトークナイズを行いましょう。日本の首都を訪ねる質問に加えて、huggingfaceのブログを参考に、[INST]のような特殊文字を加えています。
input_text = """<s>[INST] Where is the capital of Japan? [/INST]"""
input_tokens = model.tokenizer(
[input_text],
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=64,
padding=False
)続けてモデルへの入力と生成をし、生成された文章を出力します。
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=10,
use_cache=True,
return_dict_in_generate=True
)
output = model.tokenizer.decode(generation_output.sequences[0][len(input_tokens['input_ids'][0]):])
print(output) # The capital of Japan is Tokyo. Located「The capital of Japan is Tokyo. Located (訳: 日本の首都は東京です。位置は、、、)」という生成結果となり、きちんと答えられているように見えます。
なお生成中のGPUの使用率をnvidia-smiコマンドで確認したところ、3GBほどとなっていたので、確かに4GBのGPUメモリで動作するな、と思いました。
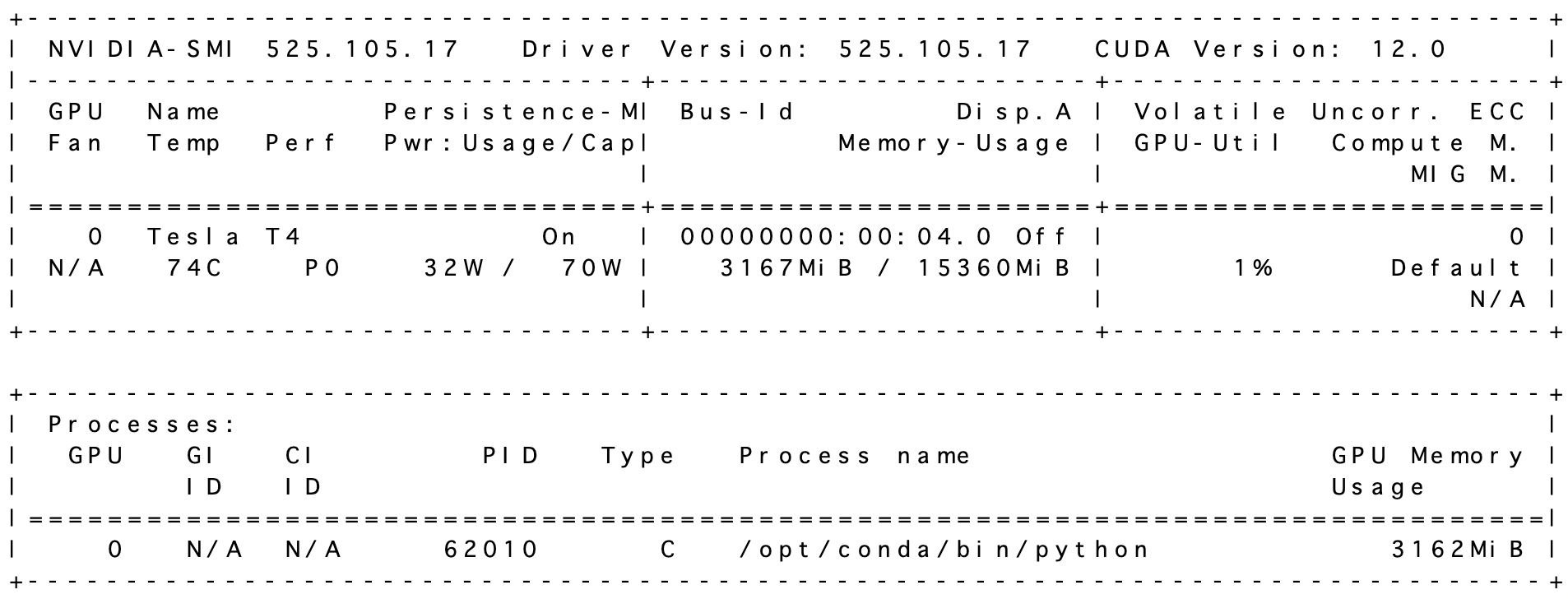
ただこの辺は入力する文章長によっても変動すると思うので、やはり16GBほどは確保しておいた方がよさそうです。
さて、気になる推論速度ですが、1層ずつ処理を行っていくのでとても遅いです。私の環境では1トークンを推論するのに大体7~8分ほどかかりました。
応用
一応T4上では動かせたものの、1トークンを生成するのに8分もかかるとなると、適用先を考えるのが難しいかもしれません。ここでまたsimjeg氏による活用アイディアがあるので、応用例として一つ挙げたいと思います。
アイディアはLLMをZero Shotテキスト分類器として使う、と言ったものです。例えば極性分類を行う際は、以下のようなプロンプトを入力すると、最初の1トークンのみ確認すれば分類を行うことができると思います。
今日は朝から電車が遅延して最悪だ、、、
この文章はポジティブな内容ですか?
"Yes"か"No"かで答えてください。このようにプロンプトを工夫して、最初の1トークン目に回答がくるようにして、1トークンだけ生成することで、LLMをZero-Shot文章分類器として活用することができます。ちなみにsimjeg氏はプロンプトを工夫することで、例えばA, B, C, Dのような4択問題のような多値分類問題も解かせることができることを言及しています。
検証
本ブログで何度か(1、2、3、4)検証につかったことのあるNatural Language Processing with Disaster Tweetsのデータを使って検証してみたいと思います。
ライブラリの読み込みとデータの読み込みを行います。学習データを50件サンプリングしたものをテストデータとします。
import torch
import pandas as pd
import numpy as np
from sklearn.metrics import f1_score
train_df = pd.read_csv("train.csv")
test_df = train_df.sample(50, random_state=0)
targets = test_df["target"].values
texts = test_df["text"].values"Yes"のトークンと"No"のトークンのIDを取得します。本来であれば最も確度の高いトークンを取得しますが、LLMがプロンプトを考慮しきれず、Yes/No以外の出力がされる場合もあるので、YesとNoのトークンの出力確率を比較して、確度の高い方を回答とすることにします。
yes_token = model.tokenizer("Yes")["input_ids"][1]
no_token = model.tokenizer("No")["input_ids"][1]
pred_id = [no_token, yes_token]各テストデータに対して予測を行います。airllmは通常のforwardパスでも使うことができます。
predicts = []
for text in tqdm(texts):
prompt = (
f"<s>[INST] "
f"You are predicting whether a given tweet is about a real disaster or not.\n"
f"Please answer with 'Yes' or 'No'.\n\n"
f"### tweet\n"
f"{text}"
f" [/INST] "
)
input_tokens = model.tokenizer(
[prompt],
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=128,
padding=False
)
with torch.no_grad():
out = model(input_tokens['input_ids'].cuda())
predicts.append(out[0].cpu()[0, -1, pred_id].numpy())
predicts = np.stack(predicts)予測が終わったら精度を計算します。
score = (predicts.argmax(1) == targets).mean()
print(score) # 0.84私の環境ではaccuracy=0.84となりました。
ちなみに以前敵対的学習手法の比較を行った際のBestスコアがAWPをつかった時の0.814でした。評価データが異なるので、一概に比較することはできませんが、それでも今回の手法はかなり高精度な分類器と言えるのではないでしょうか。
おわりに
本記事ではairllmを使ってT4上で70B LLMの推論を試してみました。
推論は可能だったものの、かなり時間がかかることがわかり、応用方法としてプロンプトを工夫してZero-Shotテキスト分類器として使う方法を検証しました。
やはり時間はかかるので、使い所は難しいですが、バッチ処理などで時間はあまり気にしないけど、学習データがない状況などでは役に立つかもしれません。我々も検討していきたいです。
最後までお読みいただきありがとうございました!




