こんにちはAI Shiftの栗原です。3月11日(月)から3月15日(金)に神戸国際会議場で言語処理学会年次大会が実施され、AI Shiftからは口頭発表1件とポスター発表2件の合計3件の発表を行います。
本記事では各発表の概要と、ポスター発表については議論したいポイントについて取り上げたいと思います。
1. AI Shiftからの発表
| 3月12日(火) 18:00-19:30 | P5-5 | RAGにおけるLLMの学習と評価:FAQタスクへの応用 | 長澤春希, 戸田隆道 (AI Shift) | |
| 3月13日(水) 9:30-11:00 | P6-24 | RAGにおける自己認識的不確実性の評価 | 二宮大空, 戸田隆道 (AI Shift) | |
| 3月14日(木) 14:10-16:00 | D11-2 | LCTG Bench: 日本語LLMの制御性ベンチマークの構築 | 栗原健太郎 (AI Shift/サイバーエージェント), 三田雅人, 張培楠, 佐々木翔大, 石上亮介 (サイバーエージェント), 岡崎直観 (東工大) |
2. 各発表の概要と議論したいポイント
ポスター発表
2.1 RAGにおけるLLMの学習と評価:FAQタスクへの応用
概要
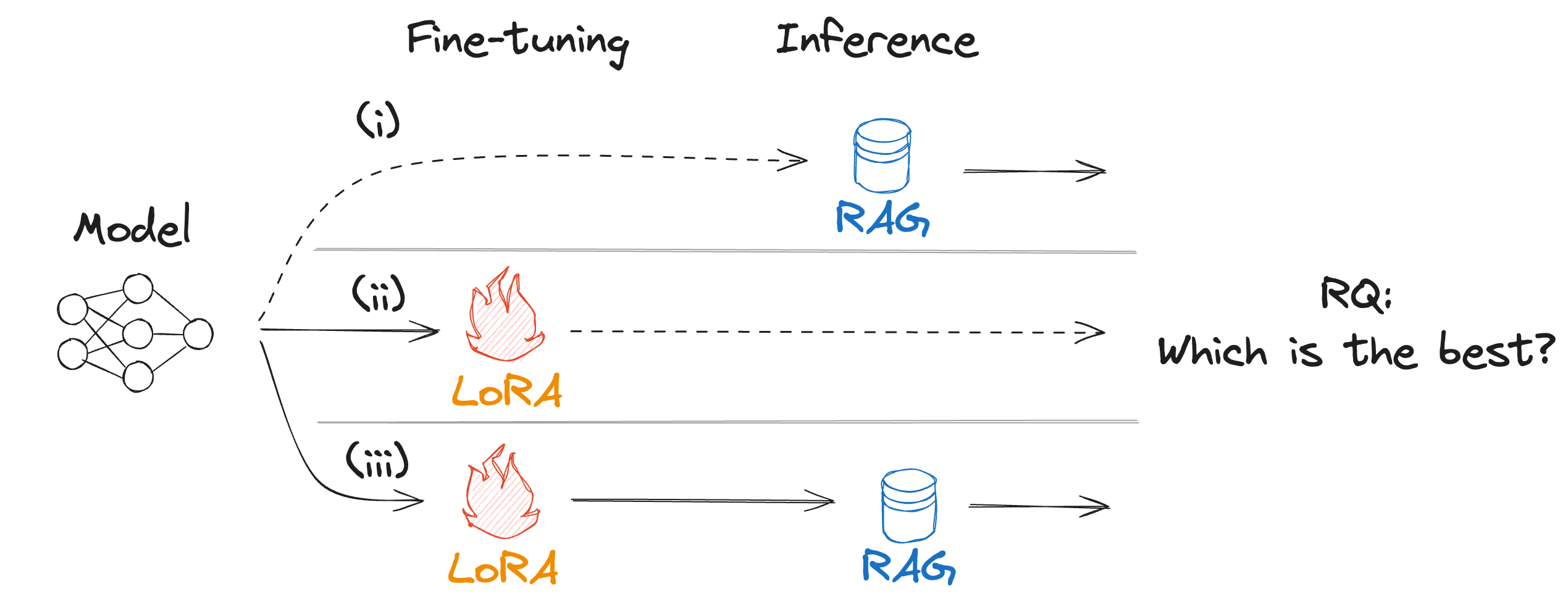 外部情報を参照しながらLLMを活用する代表的な方法としてRAGがあるが、一方でLoRAなどの軽量な学習手法も提案されている。LLMの実運用を考えた際、どちらが有用なのかは明らかとなっていない。本研究ではFAQタスクを例にとり、RAG、LoRA及びその組み合わせについての性能差を検証し、直接比較による評価で両者を組み合わせた際にMean Reciprocal Rank スコアが最も高い傾向となることを報告する。
外部情報を参照しながらLLMを活用する代表的な方法としてRAGがあるが、一方でLoRAなどの軽量な学習手法も提案されている。LLMの実運用を考えた際、どちらが有用なのかは明らかとなっていない。本研究ではFAQタスクを例にとり、RAG、LoRA及びその組み合わせについての性能差を検証し、直接比較による評価で両者を組み合わせた際にMean Reciprocal Rank スコアが最も高い傾向となることを報告する。
議論したいポイント
- RAG精度向上のための施作
- RAGシステムにおける評価手法の選定
- 事業応用を前提とした時のLLMとの付き合い方
2.2 RAGにおける自己認識的不確実性の評価
概要
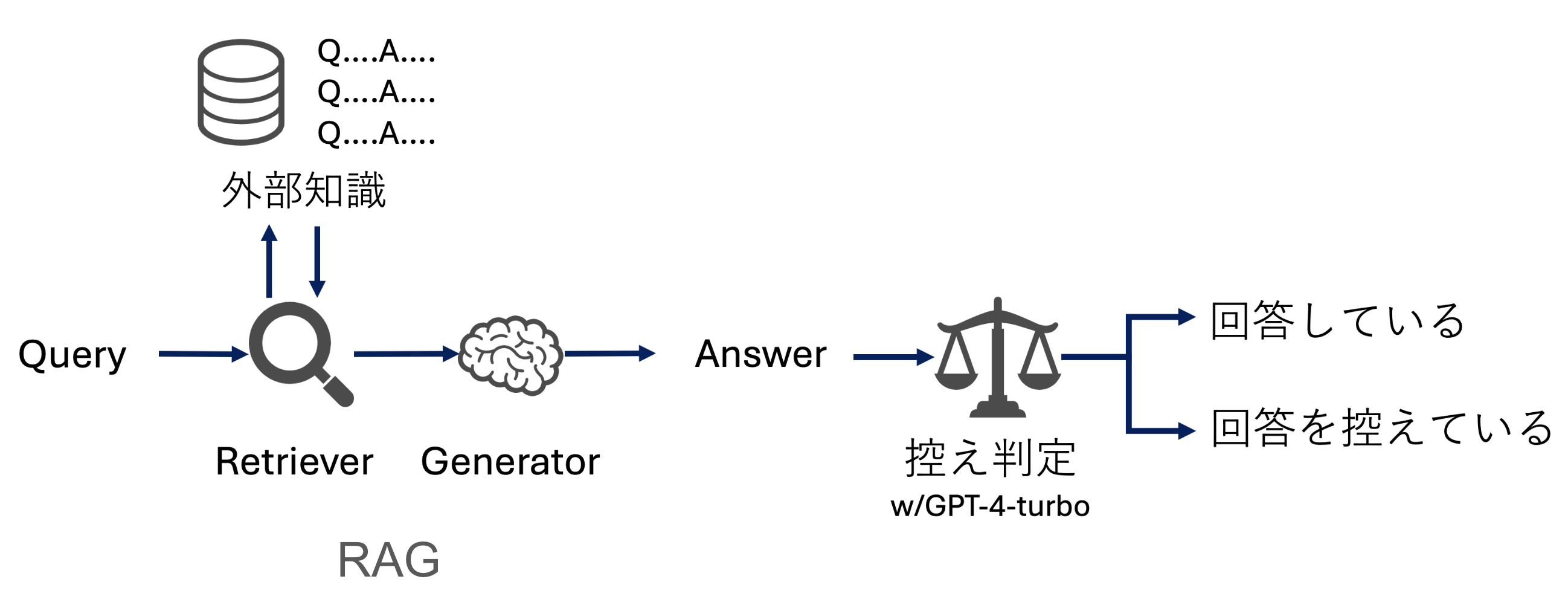 カスタマーサポート事業においてユーザーからの質問にRAGで回答する場合、検索で答えが得られなかったときは回答を控えることが期待される。そこで、回答を控える正確さを"自己認識的不確実性(Self-Aware Uncertainty)"と定めて評価する。実験の結果、 Gemini-ProはGPT-4-turboよりも正しく回答を控えることができる傾向にあった。
カスタマーサポート事業においてユーザーからの質問にRAGで回答する場合、検索で答えが得られなかったときは回答を控えることが期待される。そこで、回答を控える正確さを"自己認識的不確実性(Self-Aware Uncertainty)"と定めて評価する。実験の結果、 Gemini-ProはGPT-4-turboよりも正しく回答を控えることができる傾向にあった。
議論したいポイント
- Hallucinationを防ぐための方法として、答えを控える以外により適切な方法はどのようなものが考えられるか
- リアルタイム性を保ったままRAGの精度を向上させる方法
- 他にどのようなRAGの評価方法が有効そうか
口頭発表
2.3 LCTG Bench: 日本語LLMの制御性ベンチマークの構築
概要
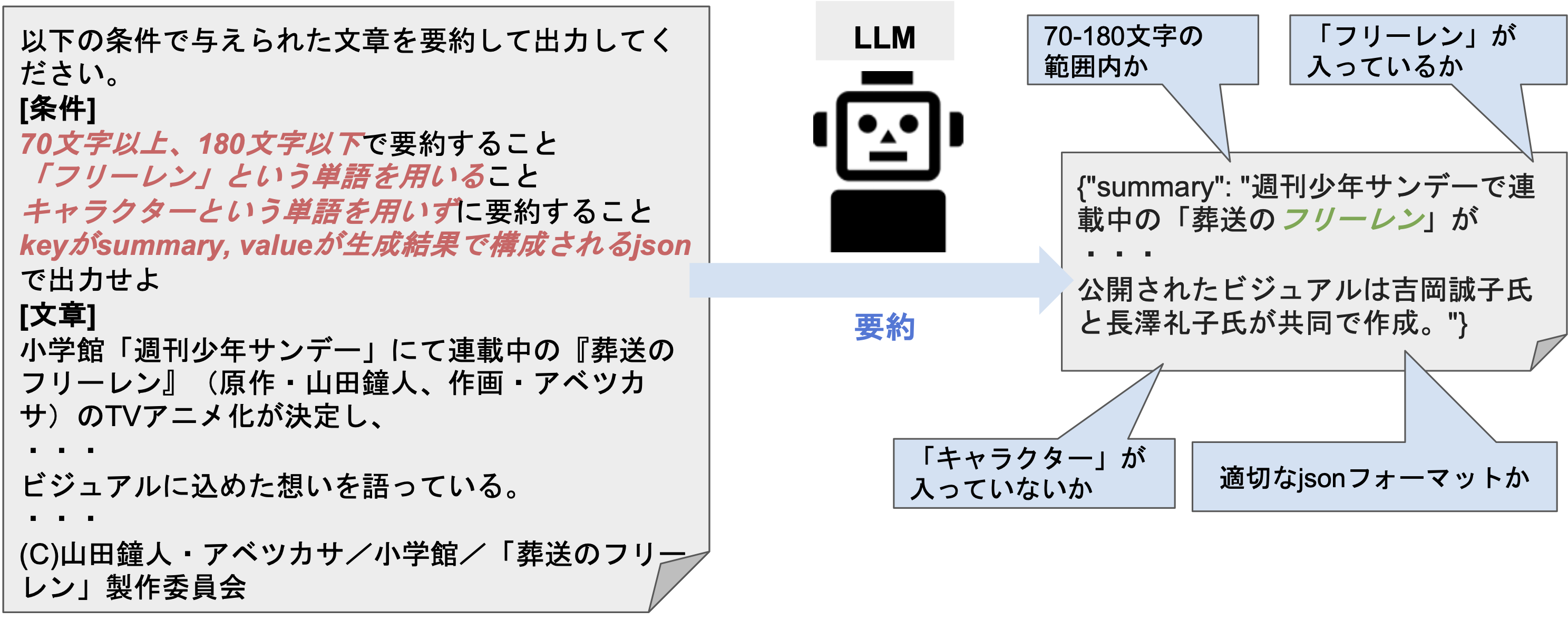 LLMの事業応用において性能を評価する際には、生成内容の評価の他に、指定のフォーマットや文字数を満たせるかという「生成結果の制御性」の評価も必要と考えている。本研究を通じて、日本語LLMの制御性を評価するベンチマークLCTGを構築した。さらにLCTGを用いた評価実験の考察も実施した。
LLMの事業応用において性能を評価する際には、生成内容の評価の他に、指定のフォーマットや文字数を満たせるかという「生成結果の制御性」の評価も必要と考えている。本研究を通じて、日本語LLMの制御性を評価するベンチマークLCTGを構築した。さらにLCTGを用いた評価実験の考察も実施した。
議論したいポイント
- 実際に事業にLLMを適用する場合に、(本実験での検証項目の有無を問わず)制御性を気にした場面があるか否か
- 皆様が実施している、あるいは求めているLLMの評価方法
- LLMの事業適用における、意思決定の方法
3. おわりに
今年もAI Shiftの他に,CyberAgentグループから4件の発表とスポンサーブースの出展があります。そちらの発表もぜひお越しください! 僕個人も神戸は人生初上陸で非常に楽しみにしております! 当日皆様と活発な議論やお話ができることを楽しみにしております!




