1. はじめに
こんにちは。AIチームの友松です。
2024年3月11日(月)〜3月15日(金)に神戸国際会議場で行われた言語処理学会第30回年次大会で、弊社からポスター発表で2件、口頭発表で1件の発表を行いました。
昨年は4年ぶりのオフライン(+オンラインのハイブリッド)開催&沖縄開催ということもあり、盛り上がりを見せておりましたが、今回の神戸開催における統計情報は投稿数599(昨年は577), 参加者数2045(昨年は1828, ※除当日参加者)となり過去最大となったようです。

2. 各発表資料と発表内でのディスカッション
2.1 RAGにおける自己認識的不確実性の評価
発表情報
P6:ポスター 3月13日(水) 9:30-11:00
P6-24 ○二宮大空, 戸田隆道 (AI Shift)発表資料

ディスカッション
- Q: Retrieverによる検索が成功するかどうかを事前にわかっていれば回答を控える方法を考える必要はないのではないですか?
- A: 実運用時には検索が成功するかどうかは事前にはわかりません。今回の実験では、RAGのGeneratorにおける回答を控える能力を計測するために、Retrieverの検索は全て事前に行なっておき、実験データの検索の正誤を元に分割しています。しかし、推論時には検索の正誤に関する情報が与えられないので、正しく回答を控えるためには、Generatorで処理する必要があります。
- Q: Retrieverで得られた情報も使うことで回答すべきか控えるべきかの判断が高精度に行えるのではないか?
- A: そうだと思います。例えば、検索時に得られた類似度の値はその情報の信頼性を表しているものと捉えることも考えられるので、Generatorが情報を判断する上で非常に有効だと考えられます。今後試してみたいと思います。
- Q: 推論時にも回答をするか回答を控えるかの二値分類の処理をすると良いのではないか?
- A: そうだと思います。今回の実験では試せませんでしたが、Generatorで処理する前に、回答を控えるかどうかを二値分類タスクとしてLLMに解かせることで精度向上する可能性があります。今後試してみたいと思います。
2.2 RAGにおけるLLMの学習と評価:FAQタスクへの応用
発表情報
P5:ポスター 3月12日(火) 18:00-19:30
P5-5 ○長澤春希, 戸田隆道 (AI Shift)発表資料
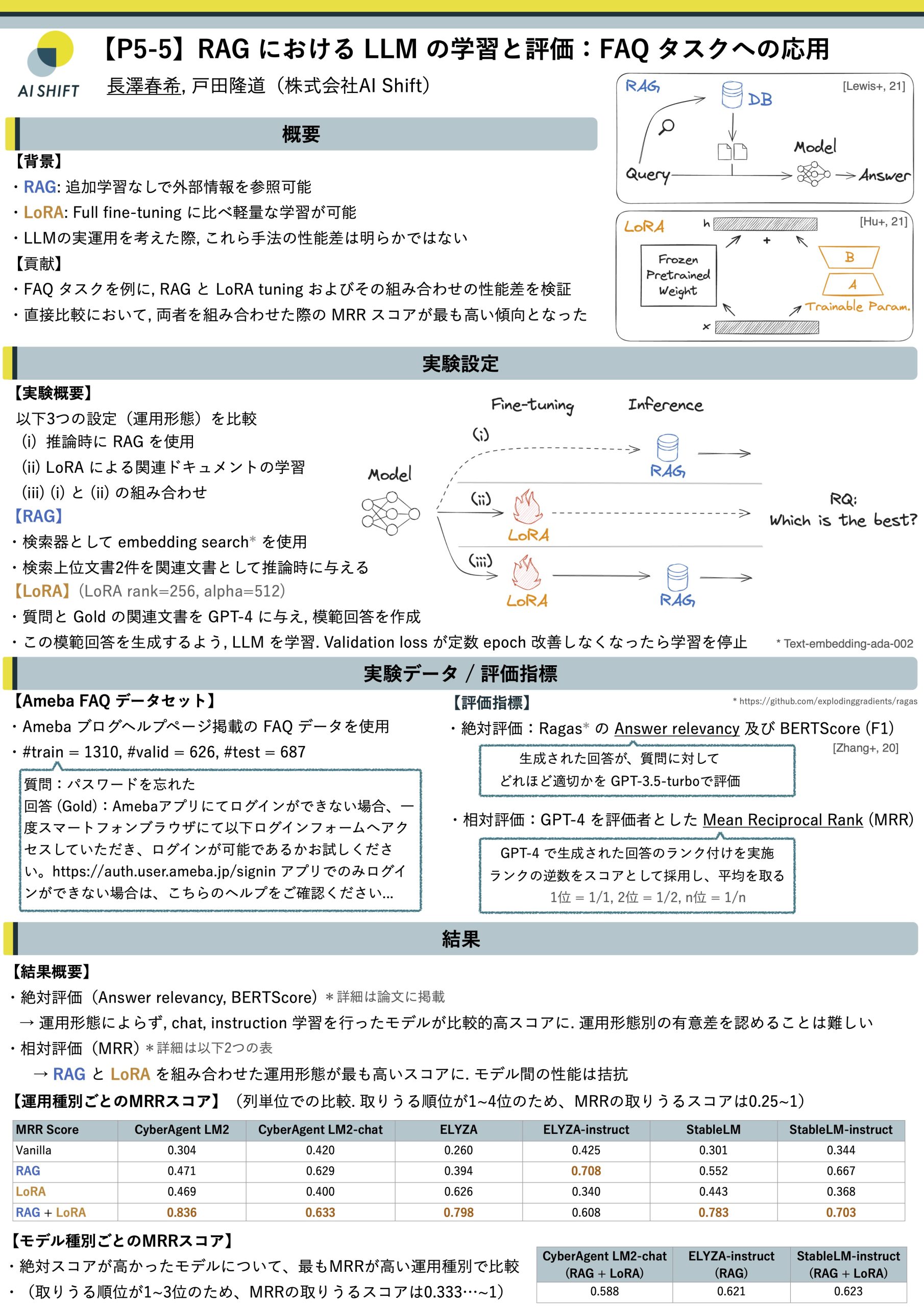
ディスカッション
- Q: Retriever の性能が気になる
- A: 今回は retriever の性能は評価の対象外としていました。ただそれぞれの条件で与える関連文書は全て共通のものとしています。
- Q: RAGのみ, LoRAのみ, RAG+LoRA のそれぞれの運用において、それぞれを最適化した際の性能上限が気になる
- A: 今回は比較的 naive な設定での比較となっていました。それぞれを最適化させた場合、またそれぞれにおける質的な振る舞いは変化することが予測されます。
- Q: 他ドメインデータでの結果が気になる
- A: 先の最適化の話と関連し、各種設定での性能はデータセットによって変わるものだと予見されます。特に事業応用を考える場合は、様々な運用方法を考えて、実際に試してみる姿勢が重要であると推察されます。
- Q: LoRA のランクが大きいように思われる
- A: 経験則的に、LoRAのランク設定は目的に応じて適宜変更することが肝要であると考えられ、今回のように新規に知識を獲得させるような場合では、少し大きめに設定しないとうまくいかないことがありました。
- Q: LoRA は出力スタイルのチューニング、RAG は外部情報参照というそれぞれの得手不得手があると考えられる。今回のように "対決" させるのではなく長所を組み合わせることが大事なのでは?
- A: 大変鋭い指摘でした。このような組み合わせはより柔軟なニーズ対応を可能にするアプローチであると考えられるので、大変参考になりました。
2.3 LCTG Bench: 日本語LLMの制御性ベンチマークの構築
発表情報
D11:テーマセッション1:人間と計算機のことばの評価(3) 3月14日(木) 14:10-16:00
D11-2 ○栗原健太郎 (AI Shift/サイバーエージェント), 三田雅人, 張培楠, 佐々木翔大, 石上亮介 (サイバーエージェント), 岡崎直観 (東工大)ディスカッション
- Q: 生成品質の評価ではGPT-4を使っているようですが,GPT-4からは文章が出力されるのでは。どのようにしてスコアに最終的に変換しましたか。
- A: GPT-4の出力が「適切」「不適切」のいずれかになるようにプロンプトを作成しました。
- Q: 今回の項目の他に検討した項目はあるのでしょうか?
- A: 今回採用したフォーマットの制御性の定義が「余計なものを出力しない」だったのですが、検討した内容の一つに「json形式で出力できるか」というものがありました。ただ、こちらは日本語LLMにとって非常に難易度が高いタスクだったので実施しないこととしました。
- Q: 2値では判断が難しいものものに拡張される予定はあるのでしょうか? (例えばスタイル(positive-negative, polite-rude)など
- A: positive-negativeは過去に検討した項目の一つで、拡張の可能性もあると思います!positive-negative程度であればJGLUEのMARC-jaなどのスコアから多くの言語モデルで容易に回答できると言えるので、考えておりました。polite-rudeでも判別が高精度でできるという調査があれば検討の余地あるかと思います。
- Q: たとえば,IFEvalのようにフォーマットの制御性(※)を多様化したうえで,制御対象の数を2個以上にすると,難易度を調節できるかもしれないと感じました.
- A: 難易度調整の話は没になりましたが構想にありました。当初の構想の原案として、制御性を1つのみ、2つ組み合わせ、3つ以上というようなレベル分けを検討していたのですが、2つ以上から日本語LLMにとっての難易度が極端に上がりまともなスコアを得られないというのが予備実験を実施した手応えでしたので、制御性1つのみ(つまり最も簡単なレベルのみ)というデザインになりました。
- Q: 達成条件が明確ではない制御への拡張(例えば、小学生が理解できるようにして)について、お考えがあれば教えてください。(そういうものを作りたいなと思っていたのでした。また議論させてください。)
- A:
小学生が理解できるようにしてこのような達成条件が不明瞭なものを納得感のある形で評価するのは今のところ難しいなと感じています。(それこそGPT-4などの高性能とされているLLMによる評価が主流?)従来のBERTベースのモデルが容易に回答可能な分類のレベルであれば、ある程度達成条件が曖昧になってもいいと考えています!(今回はコードベースで判別できるくらい明確になるよう設計しました)
- A:
- Q: もし根本的な限界 = 指示チューニングでは改善不能な特徴なのだとしたら,制御性を調べるタスクとしてあまり妥当ではないのかもしれないとも思いましたが,わかりません.
- A: この点については、インストラクションチューニングで改善できるのかは確かに不明ですね。ただ、文字数の制御性自体は関心が強いだろうという認識であり、GPT-4でも現状難しい項目となっていますが、いつの日かより強いLLMが出たその日にこのベンチマークを使って、「今まで難しかった文字数も制御できるようになった!」みたいな議論ができると面白いのかなと思っています。妥当性はともかくとして、設けるべき観点の一つかなと考えています。
3. 2023年度言語処理学会最優秀論文賞
会期中に、弊社所属の栗原 健太郎主著の「JGLUE: 日本語言語理解ベンチマーク」が2023年度言語処理学会最優秀論文賞を受賞しました。※研究内容は弊社での取組みではなく、学生時代の研究になります。
また、研究内容について、招待論文で発表を行いました。
4. おわりに
昨年の沖縄で開催された言語処理学会では「緊急パネル:ChatGPTで自然言語処理は終わるのか?」のようなセッションが企画されたり、そのセッションが行われた夜にOpenAI社からGPT-4が発表されたりとNLPがこれからどうなっていくかというところに非常に注目が集まっていましたが、ChatGPTで自然言語処理は終わっておらず過去最大の開催となりました。生成AIに絡んだデータセットの構築、生成AIの挙動に関する検証、生成AIの評価に関する研究が多かったのが印象的でした。
毎度になりますが、このような素晴らしい学会を開催頂いた運営の皆様に感謝申し上げます。
来年は長崎開催が発表され、来年もAI Shiftから発表ができるように日々の活動をしていこうと思います。





