こんにちは。
AIチームの干飯(@hosimesi11_)です。今回はAI Shiftで取り組んでいる新規サービスであるAI Messenger Summaryの機械学習パイプラインと、Proof of Concept(PoC)から実際のプロダクトへと展開する過程についてご紹介します。
AI Messenger Summaryとは
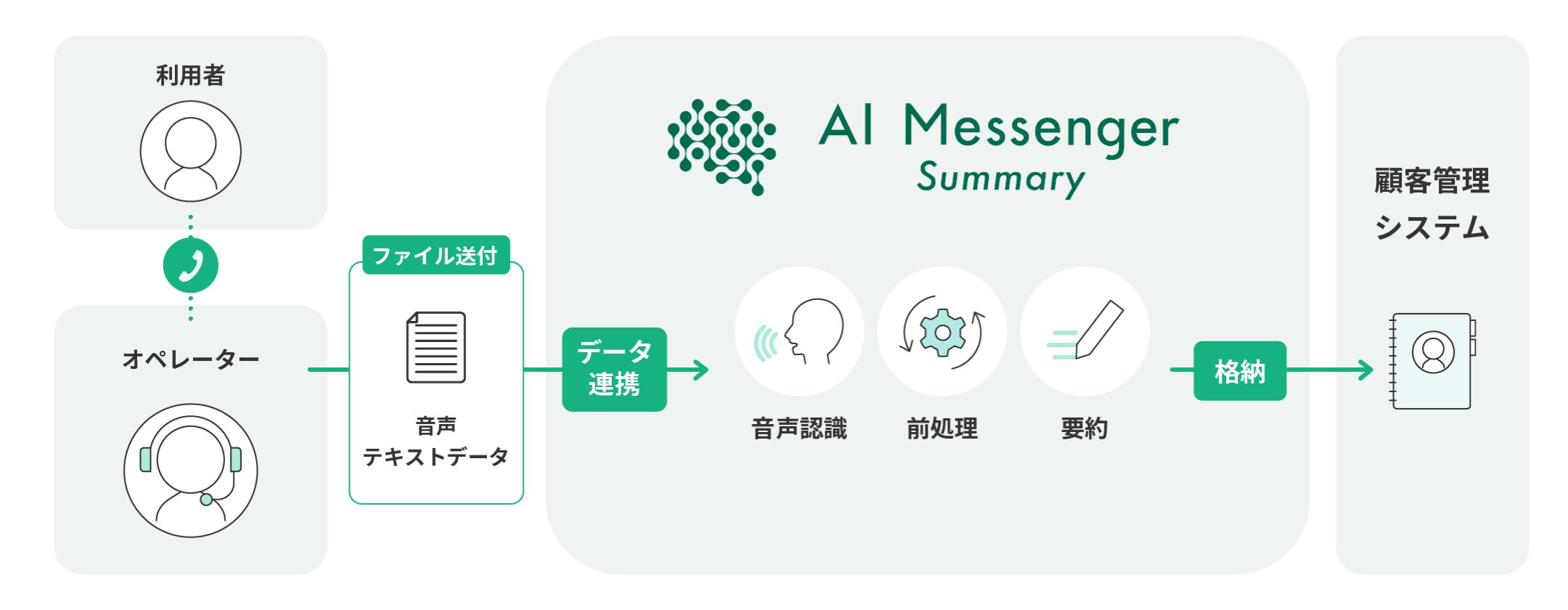
AI Messenger Summaryはコールセンター事業における、会話内容の要約サービスになります(プレスリリース)。コールセンターでは、顧客との会話内容をまとめるアフターコールワークに多くの時間が割かれるという課題があります。この状況を解決するため、オペレーターと顧客の会話データや録音データを音声認識し、大規模言語モデル(LLM)で処理して要約し、導入企業に合わせたフォーマットで出力するようなサービスとなっています。要約の他、応対品質評価やラベリングなど複数のタスクに対応しています。
初期の課題感
AI Messenger Summaryでは、各企業ごとの要約が実現可能かどうかを判別するために、PoC(Proof of Concept)フェーズを設けていました。
初期ではGradioを使った一つのサーバ内で、音声認識や要約処理など全ての処理を同期的に行っていました。処理の例として以下のようなものがあります。
- 音声ファイルアップロード
- 前処理
- 音声認識
- 後処理
- 要約
元々データサイエンティスト一人で環境を整備しており、PoC初期では十分な機能を果たせていましたが、導入企業が増えてくるにつれ徐々に課題感が出てきました。音声認識のパラメータの変更や、前処理の変更、複数のプロンプトの試行など個社ごとに試行錯誤する必要があります。また処理の特性上、一ファイルの一回の実行に数十分から数時間かかる場合もあります。PoCを行う企業が増えるにつれ、PoCの負担はさらに増すことが予想されました。
PoCの負担を下げつつ、素早くMVP(Minimum Viable Product)としてリリースできるようにするため、開発フェーズを以下の2つに定義し、段階的に達成するように進めることにしました。
Phase 1. PoCの負担削減と高速化
Phase 2. 実プロダクト実装
プロジェクトの進め方
Phase 1
Phase 1では、PoCの負担削減と高速化にだけ観点を置き、リッチな構成は取らないようにすることで実装コストを大幅に下げました。具体的には、要約処理などの画面に関係のない処理の中心をCloud Run Jobsに載せて処理を分離しました。これによって下記のことが可能になりました。
- 複数音声ファイルの処理を並列で同時実行
- 処理を分離し、画面から非同期で実行
- slackへの失敗通知
処理のリトライや細かい部分での並列実行にworkflowツールを導入したかったのですが、スピード感とPhase 2の実プロダクト実装を踏まえて、スコープ外としました。また今のUIであるGradioはリプレイスされることが予期されたため、手をつけずにジョブの分離に注力しました。

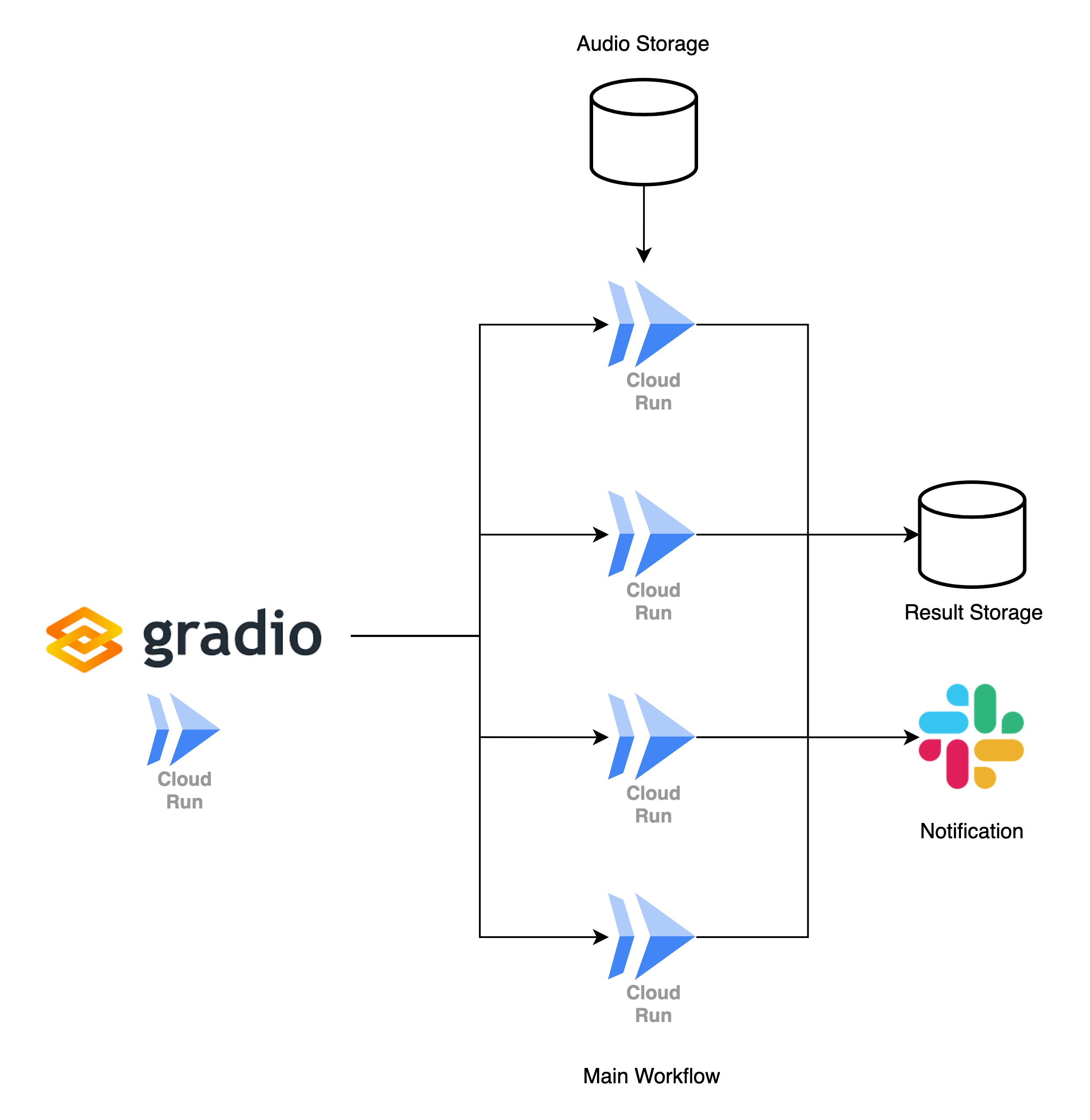
PoCの高速化をしつつ、この段階から実プロダクトの設計も開始しました。こうすることで、大部分の実装を本番時にそのまま再利用でき、実プロダクトのリリースまでの時間を短縮することができました。
Phase 2
Phase 2は実プロダクトの実装になります。実プロダクトでは各企業のCTI(Computer Telephony Integration)やCRM(Customer Relationship Management)と自動連携することになります。さらにPoCの処理も全てこのシステムに載ってくることが予期されました。本番運用とPoCの処理の共通化を考慮するとリトライ処理なども完備したかったため、ワークフローツールを導入しました。インフラ基盤とセットでワークフローツールをいくつか検討しました。
インフラ基盤とワークフローツールの選定
ここでは以下のような方針を採用することを避けました。
- 流行っているという理由での技術選定
- 必要以上にリッチな構成
- ML独自のツールの採用
これらの方針を避ける理由は次の通りです。
- プロダクト立ち上げなのでシンプルで管理しやすいシステムを目指したい
- ML独自のツールでは運用もMLエンジニアが全て見る必要があり、ソフトウェアエンジニアと共同して運用できない
そのため、以下を選定の基準としました。
- 達成したい目的を整理し、それを実現できる点
- ソフトウェアエンジニアと共同で運用できる点
AI ShiftではクラウドサービスとしてGoogle Cloudを採用しており、ほとんどのアプリケーションがGKE上で動作しています。インフラ基盤の選定に関して、元々は素早く立ち上げるためにCloud Run Jobsを使用する予定でしたが、ワークフローツールとの兼ね合いや音声認識などをGPU上で動かしたい場面が想像できたため、既に動いているGKEを選定しました。他のものに比べて初期実装コストが少し高いですが、チームとしての運用の知見やアセットがある点も含めて選定しました。
ワークフローツールの選定に関しては社内の別プロダクトの方にもヒアリングしつつ、柔軟性や既存システムとの相性、運用ノウハウの点からArgo Workflowsを選定しました。AI ShiftがArgo CDをCDツールとして使用していることも、ソフトウェアエンジニアと一緒に運用する上で大きな利点となりました。
上記を含めて、Phase 2(プロダクト)のインフラ構成は以下になります。

機械学習パイプラインの構築
AI Shiftの本番環境のGKEの管理にはKustomizeが使用されているため、検証が終わり次第デプロイするまでの差分を減らすため、ローカルでもKustomizeを使用しました。本番ではCTIなどと自動連携し、PubSubへのパブリッシュをトリガーにワークフローを動かしたかったため、Argo Eventsも使用しています。
Argo Workflowsとは
Kubernetes 上で並列ジョブを調整するためのオープンソースのワークフローツールです。柔軟なDAGを組むことができます。
Argo Eventsとは
Kubernetes 用のイベント駆動型ワークフロー実行ツールで、Webhook・MQなど様々なツールに対応しています。Sensor、EventSource、EventBusの3つのコンポーネントからなります。
Google Cloudリソースの作成
まずは、以下のようにTerraformで必要なGoogle Cloudのリソースを作成しています。
Argo Workflows
# External IP for Argo Workflows
resource "google_compute_global_address" "argo_workflows_external_ip" {
name = "argo-workflows-server-ip"
address_type = "EXTERNAL"
ip_version = "IPV4"
project = var.project
}
# DNS Zone
data "google_dns_managed_zone" "dns_zone" {
name = "dns-zone"
project = var.project
}
# DNS Record for Argo Workflows
resource "google_dns_record_set" "argo_workflows" {
project = var.dns_management_project
name = "sample.${data.google_dns_managed_zone.dns_zone.dns_name}"
type = "A"
ttl = 300
managed_zone = data.google_dns_managed_zone.dns_zone.name
rrdatas = [google_compute_global_address.argo_workflows_external_ip.address]
lifecycle {
ignore_changes = [rrdatas]
}
}
# Access Policy for Argo Workflows
resource "google_compute_security_policy" "argo_workflows_policy" {
name = "${var.env}-argo-workflows-policy"
rule {
action = "deny(403)"
priority = "2147483647"
match {
versioned_expr = "SRC_IPS_V1"
config {
src_ip_ranges = ["*"]
}
}
description = "Default"
}
rule {
action = "allow"
priority = "1001"
match {
versioned_expr = "SRC_IPS_V1"
config {
src_ip_ranges = [ "xxx" ]
}
}
description = "Allow IP Ranges"
}
}
# History DB for Argo Workflows
resource "google_sql_database" "argo_workflows_db" {
name = "$argo_workflows_db"
instance = var.db_instance_name
charset = "utf8mb4"
collation = "utf8mb4_general_ci"
project = var.project
}
# Service Account for Argo Workflows
resource "google_service_account" "argo_workflows_sa" {
account_id = "argo-workflows-sa"
display_name = "argo workflows service account"
}
# Attach secret manager accessor to Service Account for Argo Workflows
resource "google_project_iam_member" "workflows_secret_manager_iam" {
project = var.project
role = "roles/secretmanager.secretAccessor"
member = "serviceAccount:${google_service_account.argo_workflows_sa.email}"
}
# Attach pub/sub publisher to Service Account for Argo Workflows
resource "google_project_iam_member" "workflows_pubsub_publisher_iam" {
project = var.project
role = "roles/pubsub.publisher"
member = "serviceAccount:${google_service_account.argo_workflows_sa.email}"
}
# Attach storage object admin to Service Account for Argo Workflows
resource "google_project_iam_member" "workflows_storage_iam" {
project = var.project
role = "roles/storage.objectAdmin"
member = "serviceAccount:${google_service_account.argo_workflows_sa.email}"
}
# Attach artifact registry writer to Service Account for Argo Workflows
resource "google_project_iam_member" "workflows_artifact_registry_iam" {
project = var.project
role = "roles/artifactregistry.writer"
member = "serviceAccount:${google_service_account.argo_workflows_sa.email}"
}
# Attach service account token creator to Service Account for Argo Workflows
resource "google_project_iam_member" "workflows_service_account_token_creator_iam" {
project = var.project
role = "roles/iam.serviceAccountTokenCreator"
member = "serviceAccount:${google_service_account.argo_workflows_sa.email}"
}
# Attach cloud sql client to Service Account for Argo Workflows
resource "google_project_iam_member" "workflows_cloudsql_client_iam" {
project = var.project
role = "roles/cloudsql.client"
member = "serviceAccount:${google_service_account.argo_workflows_sa.email}"
}
# Attach Workload Identity to Service Account for Argo Workflows
resource "google_service_account_iam_binding" "argo_workflows_workload_identity" {
service_account_id = google_service_account.argo_workflows_sa.name
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:${var.project}.svc.id.goog[argo-workflows/argo-workflows-sa]"]
}
# Bucket for Argo Workflows Log
resource "google_storage_bucket" "argo_workflows_logs_bucket" {
name = "argo-workflows-logs"
location = var.region
project = var.project
force_destroy = true
}
Argo Events
# Argo Eventsのservice account
resource "google_service_account" "argo_events_sa" {
account_id = "argo-events-sa"
display_name = "用のargo events用のservice account"
}
# Attach pub/sub subscriber to Service Account for Argo Events
resource "google_project_iam_member" "pubsub_subscriber_iam" {
project = var.project
role = "roles/pubsub.subscriber"
member = "serviceAccount:${google_service_account.argo_events_sa.email}"
}
# Attach pub/sub viewer to Service Account for Argo Events
resource "google_project_iam_member" "pubsub_viewer_iam" {
project = var.project
role = "roles/pubsub.viewer"
member = "serviceAccount:${google_service_account.argo_events_sa.email}"
}
# Attach service account token creator to Service Account for Argo Events
resource "google_project_iam_member" "workflows_service_account_token_creator_iam" {
project = var.project
role = "roles/iam.serviceAccountTokenCreator"
member = "serviceAccount:${google_service_account.argo_events_sa.email}"
}
# Attach Workload Identity to Service Account for Argo Events
resource "google_service_account_iam_binding" "argo_events_workload_identity" {
service_account_id = google_service_account.argo_events_sa.id
role = "roles/iam.workloadIdentityUser"
members = ["serviceAccount:${var.project}.svc.id.goog[argo-events/argo-events-sa]"]
}
Argo Workflowsのインストール
Argo WorkflowsをGKEに構築していきます。(一部抜粋)
まず、以下のページからinstall.yamlをダウンロードし、kustomizeの配下におきます。
https://github.com/argoproj/argo-events/releases
ConfigMapを作成します。ここでは、ワークフローの履歴をMySQLに入れるための設定をしています。また、GCSにもログが上がるように設定しています。
ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: workflow-controller-configmap
namespace: argo-workflows
data:
parallelism: "10"
namespace: argo-workflows
resourceRateLimit: |
limit: 10
burst: 1
persistence: |
archive: true
archiveTTL: 10d
skipMigration: false
connectionPool:
maxIdleConns: 100
maxOpenConns: 100
nodeStatusOffLoad: true
mysql:
host: xxxxx
port: 3306
database: xxxx
tableName: argo_workflows
userNameSecret:
name: argo-workflows-secret
key: MYSQL_USER
passwordSecret:
name: argo-workflows-secret
key: MYSQL_PASSWORD
artifactRepository: |
archiveLogs: true
gcs:
bucket: sample-log-bucket
keyFormat: "argo\
/{{workflow.creationTimestamp.Y}}\
/{{workflow.creationTimestamp.m}}\
/{{workflow.creationTimestamp.d}}\
/{{workflow.name}}\
/{{pod.name}}"
Service Account
ここで、Google Cloud側で作成済みのサービスアカウントとKubernetesのサービスアカウントを紐付けます。
apiVersion: v1
kind: ServiceAccount
metadata:
name: argo-workflows-sa
namespace: argo-workflows
annotations:
iam.gke.io/gcp-service-account: sample-gcp-service-account
Deployment
Deploymentの定義をします。ここでは--auth-modeはclient、server、ssoが対応しています。
apiVersion: apps/v1
kind: Deployment
metadata:
name: argo-server
namespace: argo-workflows
spec:
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
selector:
matchLabels:
app: argo-server
template:
metadata:
labels:
app: argo-server
spec:
serviceAccountName: argo-workflows-sa
terminationGracePeriodSeconds: 60
nodeSelector:
cloud.google.com/gke-nodepool: sample-node-pool
containers:
- name: argo-server
args: ["server", "--secure=false", "--auth-mode=sso"]
ports:
- containerPort: 2746
livenessProbe:
httpGet:
path: /
port: 2746
scheme: HTTP
initialDelaySeconds: 3
periodSeconds: 30
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
readinessProbe:
httpGet:
path: /
port: 2746
scheme: HTTP
initialDelaySeconds: 3
periodSeconds: 30
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- sleep 10Service
apiVersion: v1
kind: Service
metadata:
name: argo-server
namespace: argo-workflows
annotations:
cloud.google.com/neg: '{"ingress":true}'
spec:
type: ClusterIP
selector:
app: argo-server
ports:
- name: argo-workflows-ui
port: 80
targetPort: 2746
protocol: TCP
Ingress
Ingressを作成します。ここでは先ほどTerraformで作成済みのExternal IPや、DNSレコードを設定します。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: argo-server-ingress
namespace: argo-workflows
annotations:
kubernetes.io/ingress.global-static-ip-name: sample-ip-name
networking.gke.io/managed-certificates: sample-certificates
spec:
defaultBackend:
service:
name: argo-server
port:
number: 80
rules:
- host: sample-domain
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: argo-server
port:
number: 80これらをapplyすることで、Argo Serverが起動し、Argo UIが表示されます。
Argo Events
Argo EventsをGKEに構築していきます。(一部抜粋)
まず、以下のページからinstall.yamlをダウンロードし、kustomizeの配下におきます。
https://github.com/argoproj/argo-events/releases
EventBus
EventBusを定義します。
apiVersion: argoproj.io/v1alpha1
kind: EventBus
metadata:
name: argo-events-bus
namespace: argo-events
spec:
jetstream:
version: 2.9.12
replicas: 3
nodeSelector:
cloud.google.com/gke-nodepool: sample-node-pool
streamConfig: |
maxAge: 24h
settings: |
max_file_store: 1GB
startArgs:
- "-D"
EventSource
EventSourceを作成します。ここでは先ほどTerraformで作成した、ワークフローをキックする際に使用するPub/Subを指定します。
apiVersion: argoproj.io/v1alpha1
kind: EventSource
metadata:
name: gcp-pubsub
namespace: argo-events
spec:
eventBusName: argo-events-bus
type: pubsub
template:
serviceAccountName: argo-events-sa
spec:
nodeSelector:
cloud.google.com/gke-nodepool: sample-node-pool
pubSub:
workflow-trigger:
jsonBody: true
projectID: sample-project
topic: sample-topic
subscriptionID: sample-topic-sub
Sensor
どのワークフローをキックするかを定義します。ここで、dependenciesはEventSourceと名前を合わせる必要があります。
apiVersion: argoproj.io/v1alpha1
kind: Sensor
metadata:
name: pubsub-sensor
namespace: argo-events
spec:
template:
serviceAccountName: argo-events-sa
eventBusName: argo-events-bus
dependencies:
- name: sample-trigger-dependency
eventSourceName: gcp-pubsub
eventName: workflow-trigger
triggers:
- template:
name: trigger-template
k8s:
operation: create
source:
resource:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: workflow-
namespace: argo-workflows
spec:
serviceAccountName: argo-workflows-sa
workflowTemplateRef:
name: sample-workflow
arguments:
parameters:
- name: config
valueFrom:
path: /event
parameters:
- src:
dependencyName: sample-trigger-dependency
dataKey: body
dest: spec.arguments.parameters.0.value
これらをapplyすることで、Argo Events用のpodが作成されます。
Workflowの本体のデプロイ
Argo Events経由でワークフローをキックしたいため、今回はWorkflowTemplateを用いて機械学習のワークフローを定義します。
大まかな処理は以下のようになります。
- 前処理
- 音声認識
- 後処理
- 要約
- 結果格納
はじめにentrypoint-jobを定義し、inputやファイルによってワークフローを切り替えるために判定用のjobを一つ入れています。
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: sample-workflow
namespace: argo-workflows
spec:
templates:
- name: main-job
nodeSelector:
cloud.google.com/gke-nodepool: sample-node-pool
inputs:
parameters:
- name: config
steps:
- - name: entrypoint-job
templateRef:
name: entrypoint-job
template: entrypoint
arguments:
parameters:
- name: config
value: "{{inputs.parameters.config}}"
- - name: main-job
templateRef:
name: main-job
template: main-audio
- name: exit-handler-job
steps:
- - name: slack-notification
templateRef:
name: slack-notification-job
template: slack-notification
when: "{{workflow.status}} != Succeeded"
arguments:
parameters:
- name: title
value: "{{workflow.name}}が失敗しました"
:
実際の処理やロジックは割愛しますが、高速化のため複数ステップで並列化させています。また、処理の内容によってはGPUを使用したいため、nodeSelectorによってインスタンスを分けています。
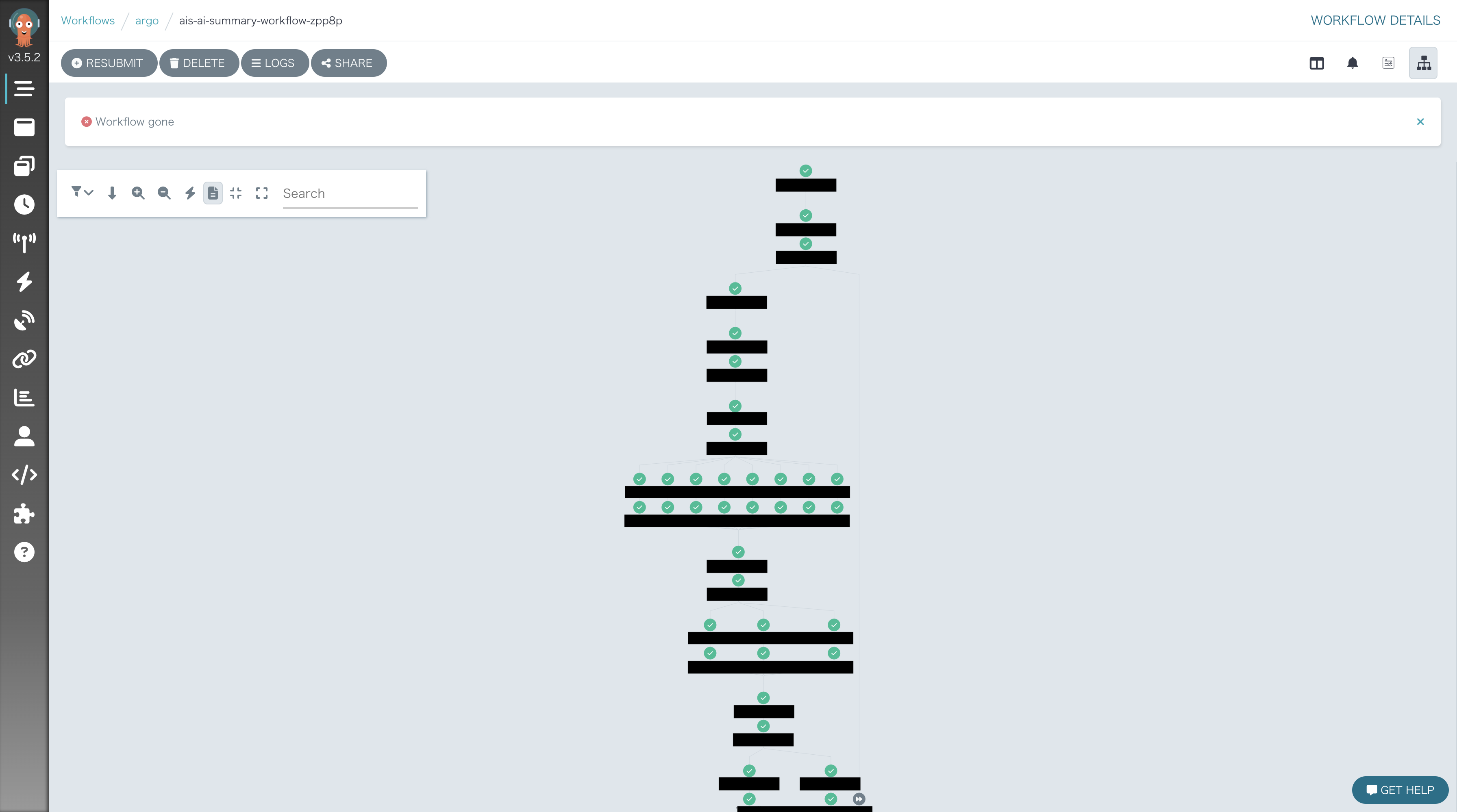
構築したワークフロー
今回構築したワークフローの全体像は以下のようになっています。音声を扱うのでMLロジックが盛りだくさんですが、柔軟なワークフローを組むことができます。
おわりに
本記事では新規プロダクトであるAI Messenger Summaryのプロジェクトの進め方と、機械学習パイプラインについて紹介しました。AI Messenger Summaryでは機械学習パイプラインにArgo Workflowsを導入しました。すでにKubernetesを運用している方にとっては選択肢になりうると思います。
最後までお読みいただきありがとうございました!





{kind=link}