こんにちは、AIチームの友松です。前回はElasticsearchにanalysis-sudachiを組み込み、挙動を確認するところまで書きました。今回はさらにベクトル検索機能を追加し、両方を組み合わせて使用します。
ベクトル化サーバーの構築
ベクトル化検索にはBERTを用います。
こちらの記事を参考にさせていただきました。
https://github.com/Hironsan/bertsearch
https://qiita.com/shimaokasonse/items/97d971cd4a65eee43735
ベクトル化サーバでは文章をrequestとして送るとBERTのベクトルが返却されます。ベクトル化サーバーはbert-as-serviceによって実現します。最終的なディレクトリ構造は以下のようになります。elasticsearch部分は前回の記事と同じ構成です。ここではbertservingについて導入手順を書いていきます。
.
├── bertserving
│ ├── Dockerfile
│ ├── entrypoint.sh
│ └── model
│ ├── bert_config.json
│ ├── bert_model.ckpt.data-00000-of-00001
│ ├── bert_model.ckpt.index
│ ├── bert_model.ckpt.meta
│ ├── graph.pbtxt
│ ├── vocab.txt
│ ├── wiki-ja.model
│ └── wiki-ja.vocab
├── docker-compose.yml
├── es
│ ├── Dockerfile
│ ├── analysis-sudachi-elasticsearch7.3-1.3.1.zip
│ ├── sudachi.json
│ └── system_full.dic
└── index.json日本語学習済みモデルの取得
学習済みモデルをダウンロードし、bertserving/modelに配置します。bert-as-serviceのファイル名に合わせるためにrenameします。
mv model.ckpt-1400000.index bert_model.ckpt.index
mv model.ckpt-1400000.meta bert_model.ckpt.meta
mv model.ckpt-1400000.data-00000-of-00001 bert_model.ckpt.data-00000-of-00001また、語彙ファイルの<unk>タグをbert-as-serviceの形式である[UNK]に変更します。
cut -f1 wiki-ja.vocab | sed -e "1 s/<unk>/[UNK]/g" > vocab.txt最後にBERTの設定ファイル(bert_config.json)を追加します。
{
"attention_probs_dropout_prob" : 0.1,
"hidden_act" : "gelu",
"hidden_dropout_prob" : 0.1,
"hidden_size" : 768,
"initializer_range" : 0.02,
"intermediate_size" : 3072,
"max_position_embeddings" : 512,
"num_attention_heads" : 12,
"num_hidden_layers" : 12,
"type_vocab_size" : 2,
"vocab_size" : 32000
}bert-as-serviceの起動
日本語学習済みモデルの準備ができたので、Dockerfileと起動スクリプト, docker-compose.ymlの設定をします。
bertserving/Dockerfile
FROM tensorflow/tensorflow:1.12.0-py3
RUN pip install -U pip
RUN pip install --no-cache-dir bert-serving-server
RUN mkdir /app
COPY entrypoint.sh /app
WORKDIR /app
ENTRYPOINT ["/bin/sh", "/app/entrypoint.sh"]
CMD []bertserving/entrypoint.sh
bert-servingの起動スクリプトです。
arguments一覧はこちらから確認できます。
#!/bin/sh
bert-serving-start -num_worker=4 -max_seq_len=None -model_dir /modeldocker-compose.yml
前回作成したdocker-compose.ymlを修正してbert-servingとelasticsearchを同時に起動できるようにします。
version: '3'
services:
bertserving:
build: ./bertserving
ports:
- "5555:5555"
- "5556:5556"
volumes:
- ./bertserving/model:/model
elasticsearch:
build: es
ports:
- 9200:9200
environment:
- discovery.type=single-node
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
expose:
- 9300
ulimits:
nofile:
soft: 65536
hard: 65536bert-as-serviceはメモリを多く使用するので、Docker for Macを使用している場合デフォルトの割り当てでは起動できませんでした。dockerの設定で割り当てメモリを増やしてください。
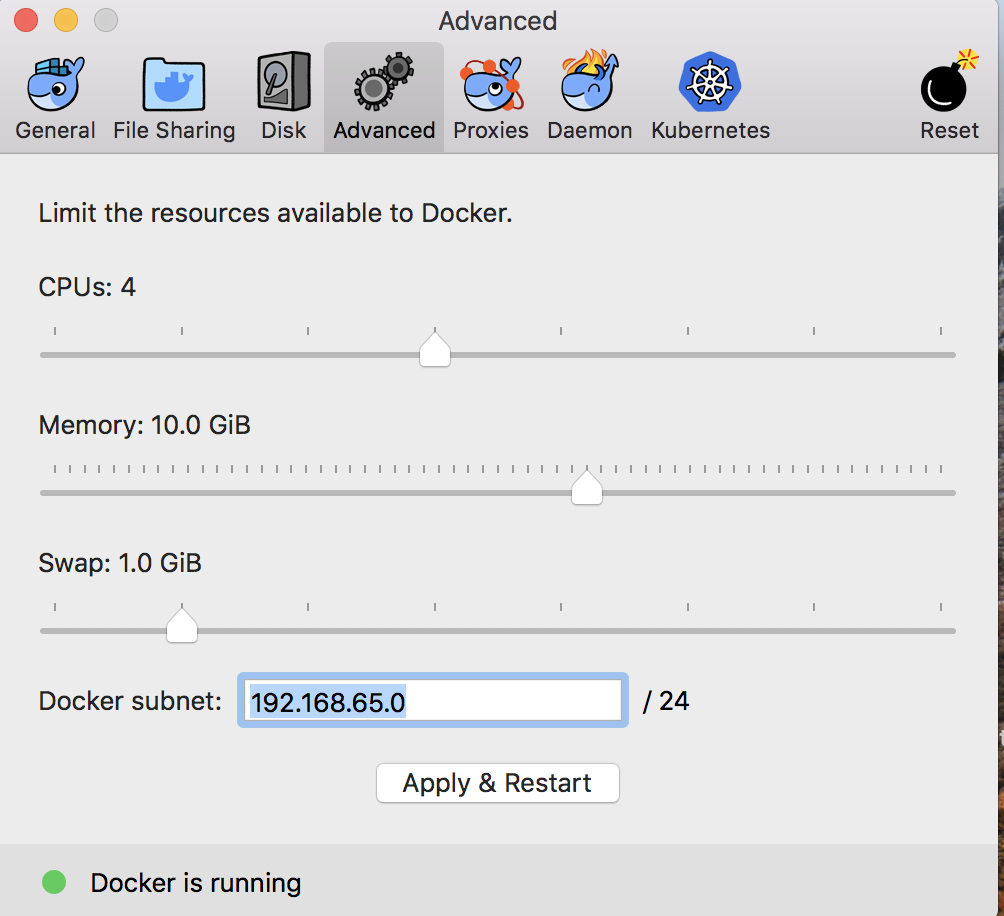
ここまで準備ができたら起動します。
docker-compose upベクトル化サーバの確認
pythonからベクトル化サーバにリクエストを送ってベクトルが返ってくるのを確認します。
pip install bert-serving-client
pip install sentencepiece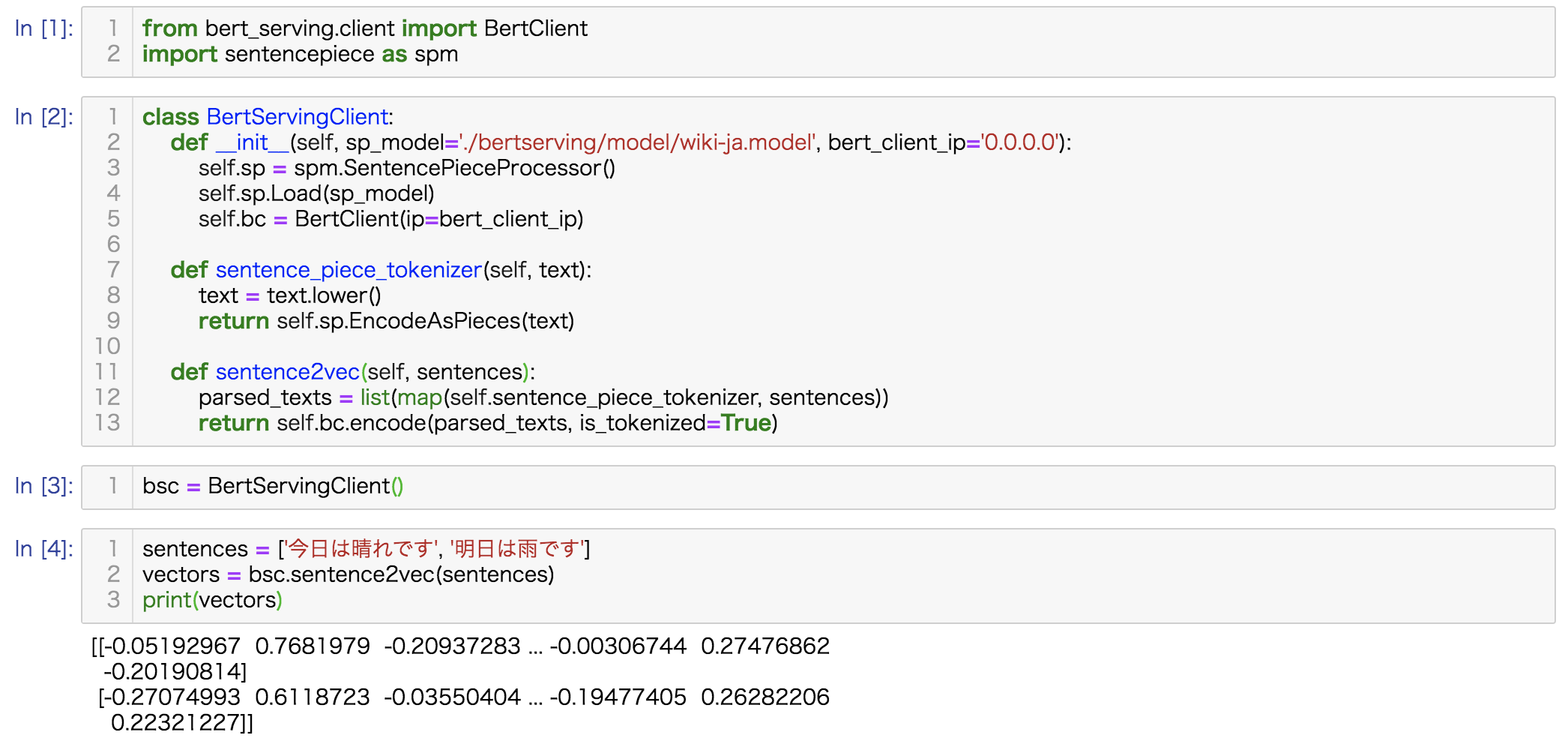
2つのsentenceに対してそれぞれベクトルが返ってきているのがわかります。
以下コードになります。
from bert_serving.client import BertClient
import sentencepiece as spm
class BertServingClient:
def __init__(self, sp_model='./bertserving/model/wiki-ja.model', bert_client_ip='0.0.0.0'):
self.sp = spm.SentencePieceProcessor()
self.sp.Load(sp_model)
self.bc = BertClient(ip=bert_client_ip)
def sentence_piece_tokenizer(self, text):
text = text.lower()
return self.sp.EncodeAsPieces(text)
def sentence2vec(self, sentences):
parsed_texts = list(map(self.sentence_piece_tokenizer, sentences))
return self.bc.encode(parsed_texts, is_tokenized=True)
bsc = BertServingClient()
sentences = ['今日は晴れです', '明日は雨です']
vectors = bsc.sentence2vec(sentences)
print(vectors)indexの登録とinsert
sudachiとbertによる文章ベクトルを組み合わせた検索を行うために前回のindex.jsonを以下のように変更します。検索に使うプロパティとしてanalysis_sudachiによってスコアを測るtext_sudachi, ベクトル検索用のフィールドとしてvectorを用意します。
{
"settings": {
"index": {
"similarity": {
"tf": {
"type": "scripted",
"script": {
"source": "double tf = Math.sqrt(doc.freq); double norm = 1/Math.sqrt(doc.length); return query.boost * tf * norm;"
}
}
},
"analysis": {
"tokenizer": {
"sudachi_tokenizer": {
"type": "sudachi_tokenizer",
"mode": "search",
"discard_punctuation": true,
"resources_path": "/usr/share/elasticsearch/plugins/analysis-sudachi/",
"settings_path": "/usr/share/elasticsearch/plugins/analysis-sudachi/sudachi.json"
}
},
"analyzer": {
"sudachi_analyzer": {
"tokenizer": "sudachi_tokenizer",
"type": "custom",
"char_filter": [],
"filter": [
"sudachi_part_of_speech",
"sudachi_ja_stop",
"sudachi_baseform"
]
}
}
}
}
},
"mappings": {
"dynamic": "true",
"_source": {
"enabled": "true"
},
"properties": {
"text_sudachi": {
"type": "text",
"analyzer": "sudachi_analyzer",
"search_analyzer": "sudachi_analyzer",
"similarity": "tf"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}indexの準備ができたら、indexの作成とdocumentの挿入を行います。
from bert_serving.client import BertClient
import sentencepiece as spm
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
class BertServingClient:
def __init__(self, sp_model='./bertserving/model/wiki-ja.model', bert_client_ip='0.0.0.0'):
self.sp = spm.SentencePieceProcessor()
self.sp.Load(sp_model)
self.bc = BertClient(ip=bert_client_ip)
def sentence_piece_tokenizer(self, text):
text = text.lower()
return self.sp.EncodeAsPieces(text)
def sentence2vec(self, sentences):
parsed_texts = list(map(self.sentence_piece_tokenizer, sentences))
return self.bc.encode(parsed_texts, is_tokenized=True)
es = Elasticsearch(['localhost'], port=9200, use_ssl=False, verify_certs=False)
index='index'
index_file = 'index.json'
with open(index_file) as f:
source = f.read().strip()
print(es.indices.create(index, source)) # indexの登録
bsc = BertServingClient()
texts = [
'今日は晴れです',
'明日は雨です',
'今日は暑いです',
'明日は涼しいです'
]
vectors = bsc.sentence2vec(texts)
docs = [
{
'text_sudachi': text,
'vector': vector.tolist(),
'_index': index
}
for text, vector in zip(texts, vectors)
]
bulk(es, docs) # bulk insert文書検索
登録した文書に対して検索をかけます。
検索の際にどの項目を採用するかはrequestの時に選択できます。
今回はanalysis_sudachiのみを使った場合, vectorのみを使った場合、両方合わせて使った場合の3パターンを試します。
import pandas as pd
from collections import OrderedDict
def search_with_vector(query, es, index):
query_vector = bsc.sentence2vec([query])[0].tolist()
script_query = {
"script_score": {
"query": {"match_all": {}},
"script": {
"source": "(cosineSimilarity(params.query_vector, doc['vector']) + 1.0)/2",
"params": {"query_vector": query_vector}
}
}
}
response = es.search(
index=index,
body={
"size": 10,
"query": script_query,
"_source": {"includes": ["text_sudachi"]}
}
)
return pd.DataFrame([
OrderedDict({
'text_sudachi': row['_source']['text_sudachi'],
'score': row['_score']
}) for _, row in pd.DataFrame(response['hits']['hits']).iterrows()])
def search_with_sudachi(query, es, index):
response = es.search(
index=index,
body={
"query": {
"match": {
"text_sudachi": query
}
}
}
)
return pd.DataFrame([
OrderedDict({
'text_sudachi': row['_source']['text_sudachi'],
'score': row['_score']
}) for _, row in pd.DataFrame(response['hits']['hits']).iterrows()])
def search_with_sudachi_and_vector(query, es, index):
query_vector = bsc.sentence2vec([query])[0].tolist()
script_query = {
"script_score": {
"query": {
"match": {
"text_sudachi": query
}
},
"script": {
"source": "_score + (cosineSimilarity(params.query_vector, doc['vector']) + 1.0)/2",
"params": {"query_vector": query_vector}
}
}
}
response = es.search(
index=index,
body={
"query": script_query,
"_source": {"includes": ["text_sudachi"]}
}
)
return pd.DataFrame([
OrderedDict({
'text_sudachi': row['_source']['text_sudachi'],
'score': row['_score']
}) for _, row in pd.DataFrame(response['hits']['hits']).iterrows()])以下に3種類の比較画像をのせます。
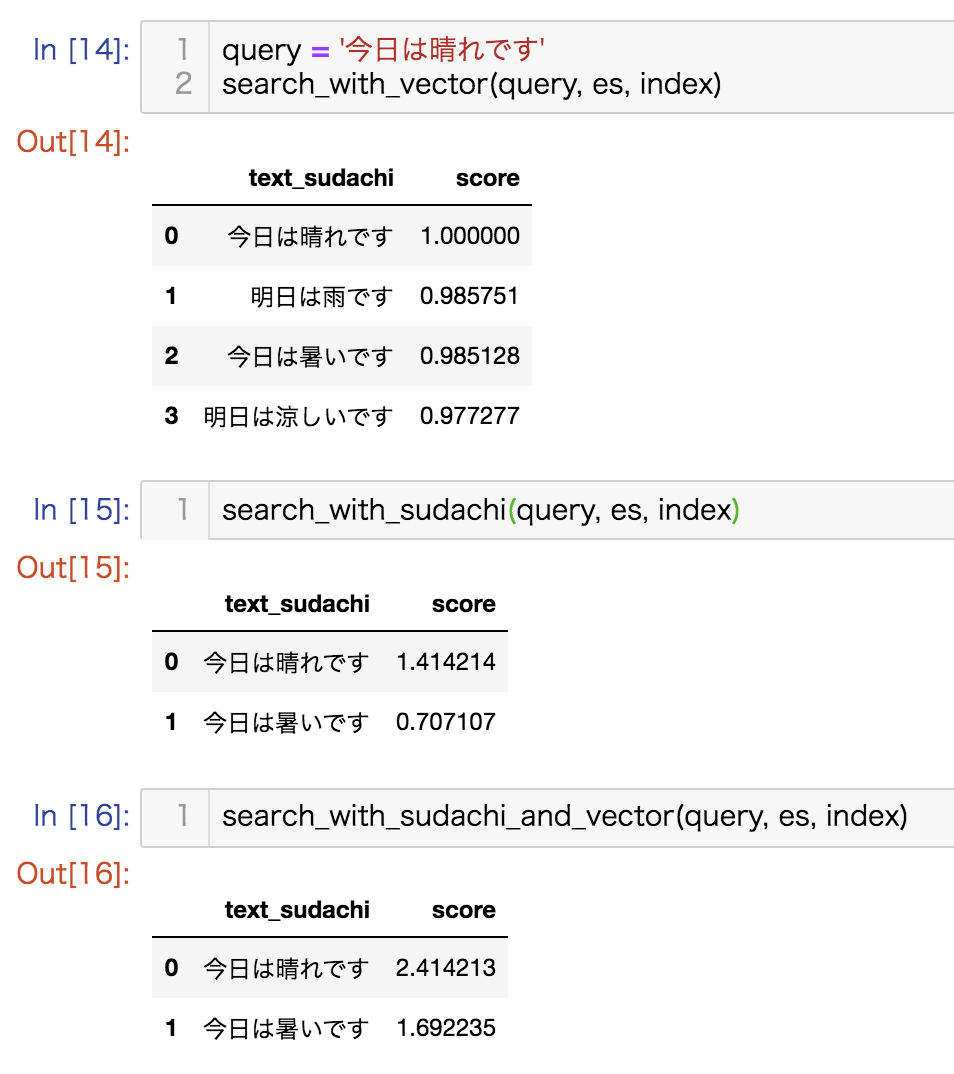
ここまでで、analysis_sudachiとvector検索を併用するために行う手順を書きました。今回はそれぞれで求めたスコアを単純に足し合わせることによって実現しましたが、実際には両スコアに対する重み付けのチューニングが必要となります。AI Shiftでも今後精度向上のための取り組みを試していきたいと思います。




