こんにちは。AIチームの干飯(@hosimesi11_)です。今回はAI Shiftの新規サービスであるAI Messanger SummaryのMLパイプラインの監視についてまとめたいと思います。
具体的にはExitHandlerで外部ツールとの連携をしつつ、詳細なメトリクスの監視はGoogle Cloud Managed Service for Prometheus + Cloud Monitoringで構成しました。
事前情報
AI Messenger Summaryとは
AI Messenger Summaryはコールセンターにおける、オペレーターと顧客の会話内容の要約サービスになります(プレスリリース)。コールセンターでは、会話内容をまとめるといったアフターコールワークに多くの時間が割かれるという課題があります。この状況を解決するため、AI Messenger Summaryはオペレーターと顧客の会話データや録音データを音声認識し、大規模言語モデル(LLM)で処理して要約し、導入企業に合わせたフォーマットで出力するようなサービスとなっています。
MLパイプラインの構成
MLを扱う音声認識やLLMを使った要約処理をStepとみなし、全ての実行をワークフローツールで制御しています。Argo Workflowsをワークフローツールとして使用し、並列化やリトライを制御しています。1つのワークフローに対する処理のステップ数はワークフローによりますが、10~20ステップほどあります。
Argo Workflowsの構成は以下を参考にしてください。
https://www.ai-shift.co.jp/techblog/4380
インフラ基盤
AI Messenger Summaryのインフラ基盤にはGoogle Cloudを採用しています。アプリケーションはGKE上に構築しています。
AI Messenger Summaryにおける監視
元々の監視体制
立ち上げ期のプロダクトのため、開発を行うエンジニアは数人程度で、監視に関してはソフトウェアエンジニア 1人、MLエンジニア 1人で監視していました。
そのため監視項目はあまりリッチにはせず、最低限のJobの成否とサーバーエラーのみをモニタリングしていました。ここでは通常のCloud LoggingのアラートとArgo WorkflowsのExitHandlerというものを使い、ステータスの連携とSlackへの通知を実行していました。ExitHandlerは成功または失敗に関係なく、ワークフローの最後に常に実行されるテンプレートです。
ExitHandlerの使用例としては以下のようなものがあります。
- ワークフロー実行後のリソースの削除
- Slackへのワークフローの成否の通知
- retry制御や他ワークフローとの連携
具体的には以下のように使用し、Slack通知とPubSubへのステータス通知をしていました。
Slack通知用のWorkflowTemplateです。
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: slack-notification-step
namespace: sample-namespace
spec:
serviceAccountName: sample-sa
templates:
- name: slack-notification
nodeSelector:
cloud.google.com/gke-nodepool: sumple-node-pool
inputs:
parameters:
- name: status
- name: title
- name: env
- name: url
- name: workflow-id
- name: duration
- name: config
- name: message
script:
command:
- sh
image: sample-image
source: |
FAILURE_MESSAGES=$(echo {{inputs.parameters.message}} | awk -F"[,:}]" '{for(i=1;i<=NF;i++){if($i~/'message'\042/){print $(i+1); exit}}}' | tr -d '"')
PAYLOAD="{\"title\":\"{{inputs.parameters.title}}\",\"config\":\"{{inputs.parameters.config}}\",\"duration\":\"{{inputs.parameters.duration}}s\",\"id\":\"{{inputs.parameters.workflow-id}}\",\"status\":\"{{inputs.parameters.status}}\",\"env\":\"{{inputs.parameters.env}}\", \"url\":\"{{inputs.parameters.url}}\", \"message\":\"$FAILURE_MESSAGES\"}"
curl -X POST -H 'Content-type: application/json' --data "$PAYLOAD" $SLACK_WEBHOOK_URLSlack通知の実際の画面です。
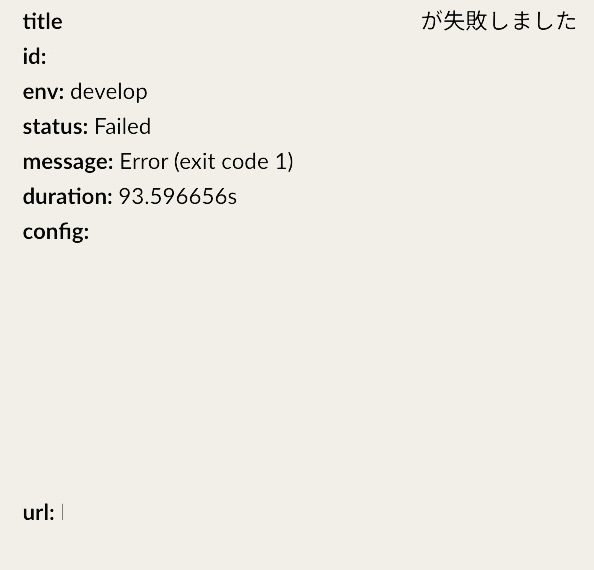
slack_notification
監視に関する課題
しかしSlack通知のステップで落ちた場合、通知が上手くいかないといった課題がありました。ログの場所やアラートの探し方も属人化していたため、チームで運用できる状況になっていませんでした。
ワークフロー自体が動いていない時やArgo Serverの負荷が上がってエラーになった場合にも気付けないため、これらも監視できるようなシステムを作ることに決めました。またエラーではありませんが、特定のステップで時間がかかりすぎてユーザーの操作に影響をきたしている場合なども気付ける必要があります。
監視に必要な項目の洗い出し
システム運用についてのゴールを以下と定めました。
- 明確な指標を持ち、その指標の変動に迅速に対応できる監視システムを構築する。
- 個々の運用者に依存せず、複数人でシステムを効率的に運用できるようにする。
監視システムを設計するために、まず必要な監視項目を洗い出しました。全てのメトリクスを監視すると、重要なデータが見落とされる可能性があるため、必要なメトリクスを厳選することが求められました。また、少人数での運用を実現するためにも、この選別作業は重要でした。そこで、ビジネスにおける重要度が高い項目を中心に、必須とオプションの2つに分けてメトリクスをリスト化しました。これにより、監視すべき重要な項目を明確にし、効率的なシステム運用を実現することを目指しました。
- マスト
- Argo Workflows Server自体のエラー
- Argo Workflows Serverのリソース使用量
- Workflowの成否
- Workflowの実行数
- Workflowの実行時間(平均・中央・最大・最小・95%tile)
- Workflowのリソース使用量
- オプション
- ステップごとの成否
- ステップごとの実行時間
- ステップごとのリトライ回数
- ステップごとのリソース使用量
- ワークフローのリトライ回数
上記を満たすようなツール選定、モニタリング方法を調査しました。
ツール選定
ワークフローの監視ツール選択の基準としては以下の3つの観点で考えました。
- 上記の監視項目を達成できるか
- 運用コスト
- 金銭コスト
この観点で調査すると候補は以下になりました。
- ログ取得
- Dashboard(アラート)
モニタリング基盤自体に運用工数を割きたくなかったため、ログ取得部分はDatadog AgentかManaged Prometheusに絞りました。どちらもやりたいことを達成できますが、結果的にGoogle Cloudで完結してコストが安く、運用がしやすいGoogle Cloud Managed Service for Prometheus + Cloud Monitoringを使用しました。
GKEではManaged Prometheusは、以下のバージョンでデフォルトで有効になっています。
- GKE v1.25以降を実行しているGKE Autopilot クラスタ
- GKE v1.27以降を実行しているGKE Standard クラスタ
AI Shiftでは、ソフトウェアエンジニアが主にCloud Monitoringをシステム監視に利用しています。このため、MLエンジニアも同様にCloud Monitoringを使用することで、全員が使い慣れたツールで運用できることを目指しました。
Managed Prometheus + Cloud Monitoringでの監視
Cloud Monitoringとは
Cloud Monitoringはアプリケーションとインフラストラクチャのパフォーマンス、可用性、健全性の可視化を提供します。取得したメトリクスに対して閾値を設けることでアラートを上げたり、外部ツールとの連携も可能になります。
Google Cloud Managed Service for Prometheusとは
Prometheusは、オープンソースのシステム監視とアラートツールです。Google Cloud Managed Service for PrometheusはフルマネージドなPrometheusでMonarchアーキテクチャ上に構築されています。料金も安く、100万サンプルで0.06ドル程度になっています。Argo Workflowsではデフォルトでworkflow-controllerの/metricsからPrometheus形式のメトリクスを吐き出しています。
Argo Workflowsのメトリクス
Argo WorkflowsがPrometheus形式で取れるメトリクスには以下の2種類があります。
- コントローラメトリクス
- カスタムメトリクス
コントローラメトリクス
コントローラメトリクスはコントローラの状態を通知するメトリクスであり、サーバの状態等を自動的に<host>:9090/metricsに吐き出します。
現在取れるメトリクスは以下のとおりです。
cronworkflows_triggered_total- CronWorkflowが実行された回数
gauge- 各フェーズで現在クラスター内にあるワークフローの数
error_count- コントローラによって発生した特定のエラーの数
k8s_request_total- Kubernetes API に送信された API リクエストの数
k8s_request_duration- 各タイプのリクエストにかかった時間
is_leader- コントローラがリーダーかどうか
log_messages- コントローラによってログレベル別に発行されたログメッセージの数
operation_duration_seconds- ワークフローの操作の所要時間
pods_gauge- ワークフローによって作成されたポッドの数
pod_missing- 実行されなかったポッドの数
pod_pending_count- 保留状態にされたポッドの数
pods_total_count- コントローラによってスケジューリングされたポッドの数
queue_adds_count- コントローラ内のキューへ追加された数
queue_depth_gauge- キューに溜まってる数
queue_duration- キュー内のイベントを捌くのにかかる時間
queue_latency- キュー内のイベントが処理されるまでにかかる時間
queue_longest_running- キューで最も長く実行されている秒数
queue_retries- キュー内でメッセージが再試行された回数
queue_unfinished_work- まだ処理されていないキュー項目の数
total_count- 処理されているワークフローの数
version- コントローラのメタデータ。属性はこちら
workers_busy_count- 処理中のキューのワーカー数
workflow_condition- それぞれのステータスのワークフローの数
workflowtemplate_runtime- 各ワークフローテンプレートの実行時間
workflowtemplate_triggered_total- 各ワークフローテンプレートの実行数
Prometheusの他、OpenTelemetryへのメトリクスの出力が可能です。
カスタムメトリクス
カスタムメトリクスはユーザー側で定義できる一連のワークフローの状態を通知するメトリクスです。ステップごとの実行時間などはこちらで定義することになります。
Argo Workflowsの設定
Argo WorkflowsのメトリクスをPrometheusに出力しようと思うと、PodMonitoringと呼ばれるCRDを定義する必要があります。Cluster全体のPodをモニタリングしたい場合はClusterPodMonitoringを使うことができます。
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: argo-workflows-monitoring
namespace: sample-namespace
spec:
selector:
matchLabels:
app: workflow-controller
endpoints:
- port: metrics
interval: 30s
timeout: 10s
metricRelabeling:
- action: keep
regex: sample.*
sourceLabels: [__name__]設定としてはmetricsのエンドポイントに30秒ごとにメトリクスを取りに行ってます。ここで重要になるのはmetricRelabelingです。こちらを設定しない場合、全てのメトリクスを取得してPrometheusに送ってしまうので想定以上にコストがかかる可能性があります。こちらで取りたいメトリクスのみに絞って取ることをおすすめします。
そしてWorkflow ControllerのConfigMapにモニタリングに関する設定を追加します。
下記ではmetricsのTTL(Time To Live)を10分としています。
apiVersion: v1
kind: ConfigMap
metadata:
name: workflow-controller-configmap
namespace: sample-namespace
data:
metricsConfig: |
enabled: true
metricsTTL: "10m"そして、カスタムメトリクスを取りたいため、各WorkflowTemplateにmetricsプロパティを追加します。こちらではステップごとの実行時間と実行の成否、リトライ数をメトリクスとして送っています。
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: sample-step
namespace: sample-namespace
spec:
serviceAccountName: sample-sa
templates:
- name: sample-step
nodeSelector:
cloud.google.com/gke-nodepool: sample-node-pool
inputs:
parameters:
- name: task-config
container:
image: image_uri
command: ["python", "main.py"]
metrics:
prometheus:
- name: step_duration
help: duration of current step
labels:
- key: template_name
value: sample-step
gauge:
value: "{{workflow.duration}}"
- name: step_result
help: result of step executed lastly
labels:
- key: template_name
value: sample-step
- key: status
value: "{{workflow.status}}"
gauge:
value: "1"
- name: step_retry_count
help: retry count of step
labels:
- key: template_name
value: sample-step
gauge:
value: "{{retries}}"これらをapplyするだけで自動的にCloud Monitoring上からメトリクスを取れるようになるので、そこからはPromQL等で可視化していくことになります。
作成したダッシュボード
上記を設定後作成したダッシュボードは以下のようになりました。月2ドル前後で必要なメトリクスの監視ができているため、コスト的にも納得できるものになりました。
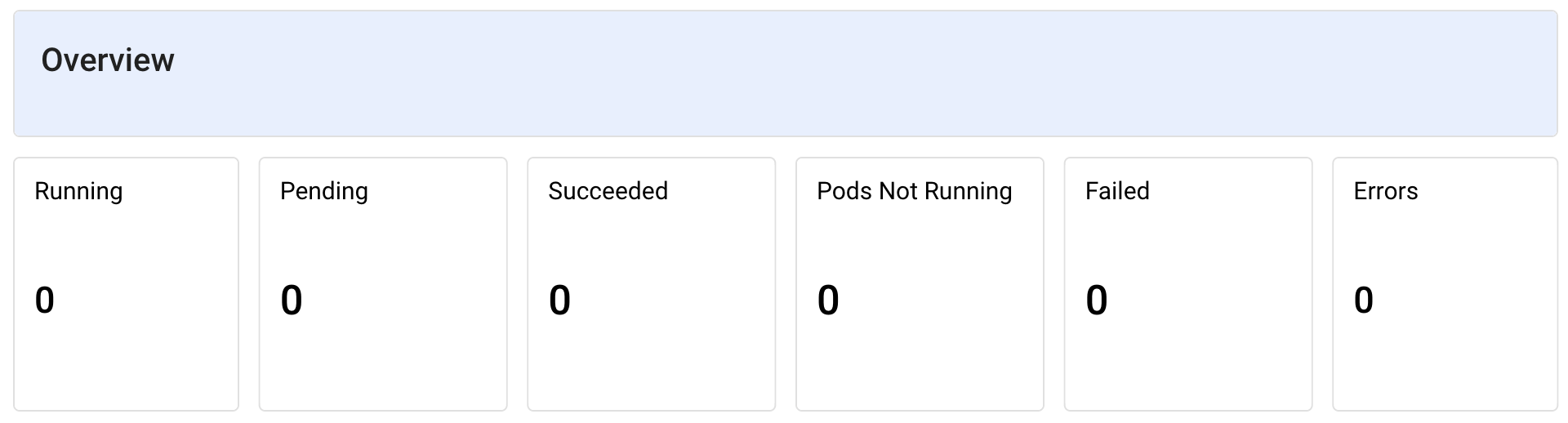
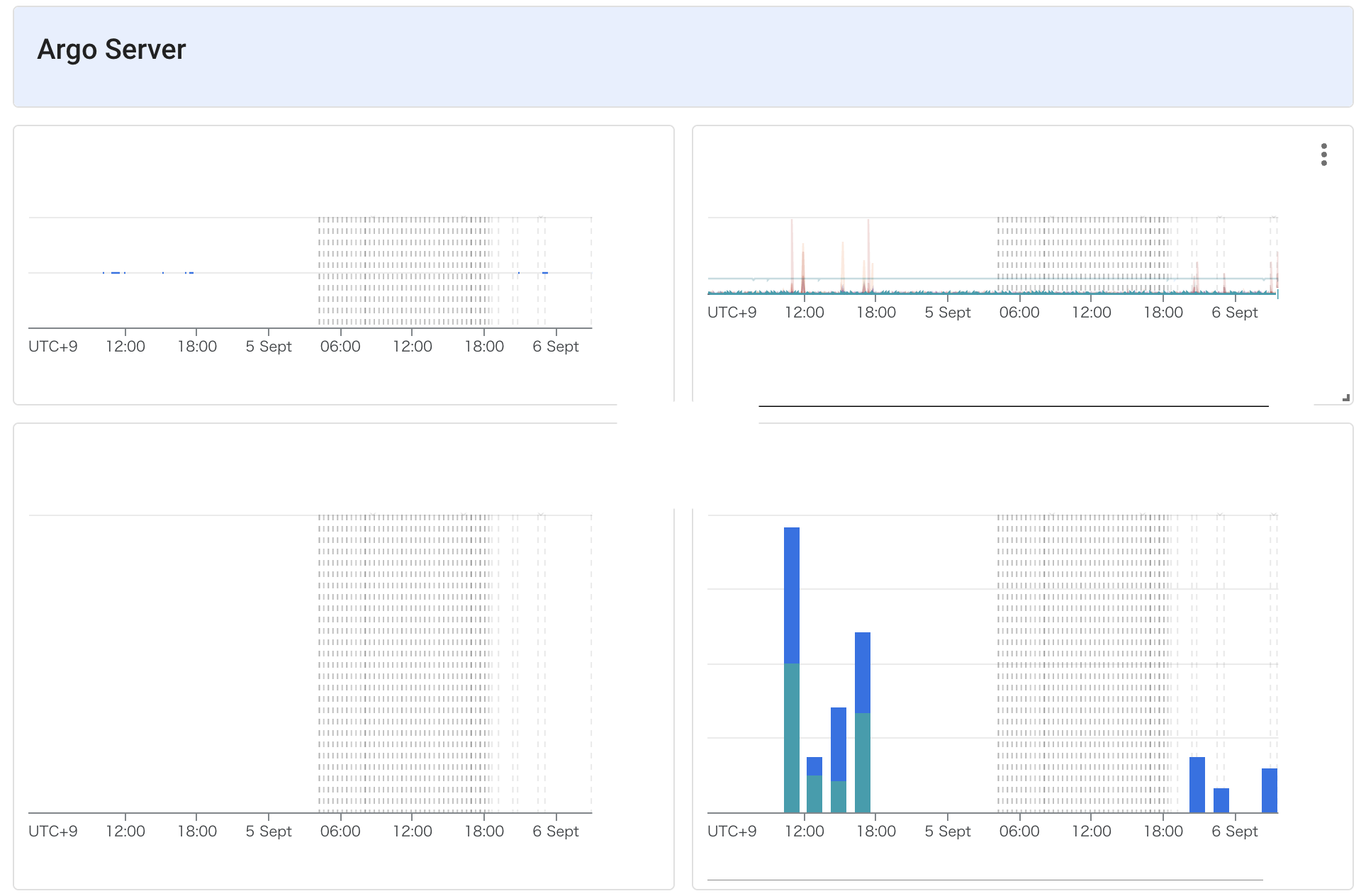
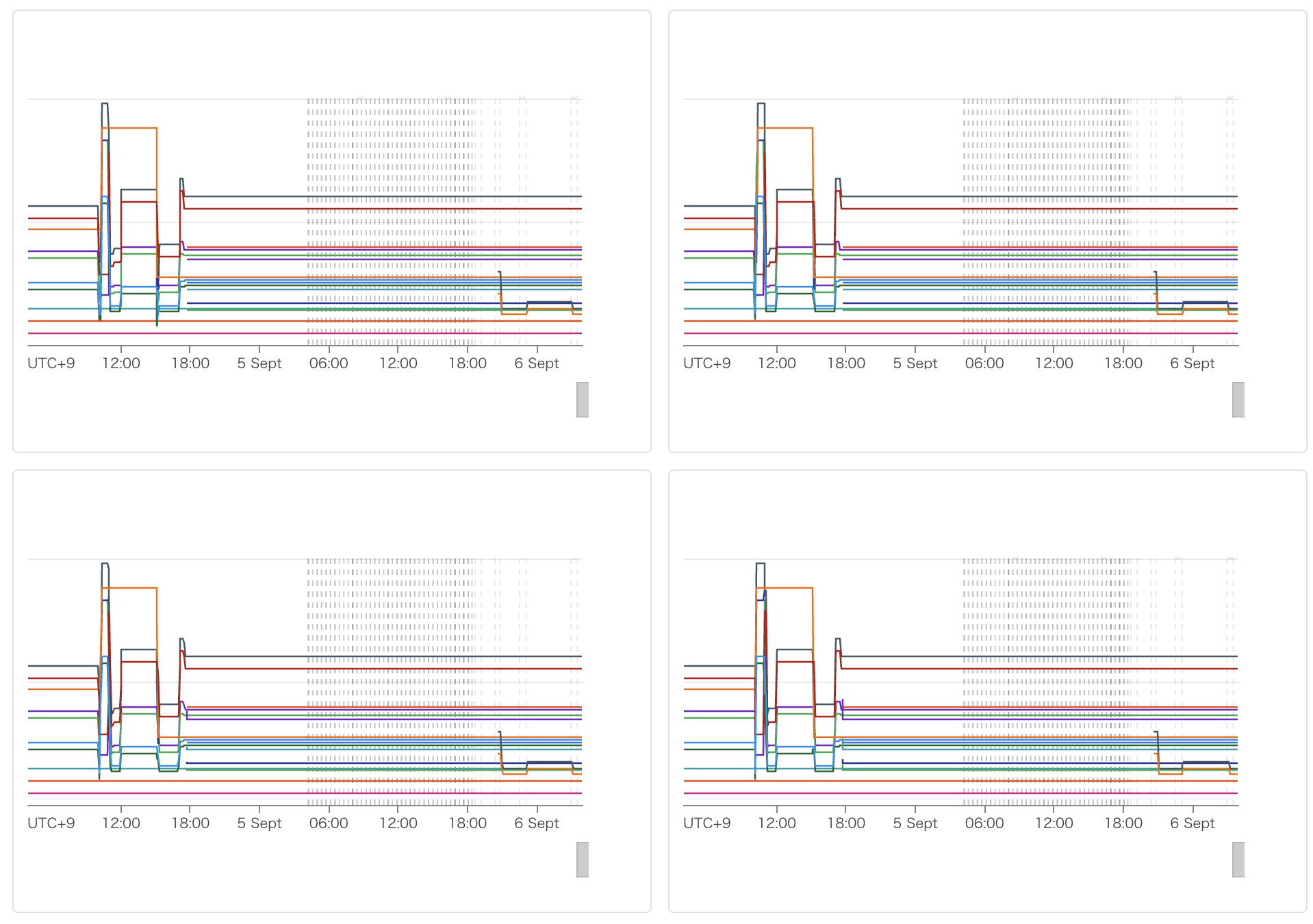
おわりに
今回はArgo Workflowsで構築したLLMを使った要約サービスのMLパイプラインの監視にManaged PrometheusとCloud Monitoringを使用した事例を紹介しました。少人数でGKE上に構築したサービスを運用する場合、Managed Prometheus + Cloud Monitoringは有力な候補になりうると思いました。低コストで上手くマネージドサービスを使用しつつ、必要なサーバメトリクスを取れるメリットはかなり大きいと思います。今回はどちらかというとソフトウェア側の監視になり、LLMの出力自体の監視やMLの監視はまだまだ発展途上ですが、今後このあたりのML監視にも力を入れていきたいと思います。




