はじめに
こんにちは、AI チームの長澤 (@sp_1999N) です。 この記事では Google によって開発・提供されている AutoMLOps を使って、充実した CI/CD パイプラインを手軽に構築してみようと思います。
今回は公式によって提供されているチュートリアルの流れに沿って、どのような GCP サービスが展開・構築されるのかを実際に手を動かして試してみます。
AutoMLOps
AutoMLOps は Google によって提供されている OSS で、CI/CD 機械学習パイプラインを手軽に構築できるツールになっています。
各パイプライン処理を実施する関数を定義するだけで、必要なサービスを自動で provisioning, deploy してくれます。
基本的な使い方
AutoMLOps での CI/CD パイプライン構築ですが、自分で行うのはコードベースで処理を定義する程度です。 少しだけ記述の仕方に癖がありますが、操作としては単純です。 パイプライン処理の記述で使うのは主に以下の2つのデコレータです。
@AutoMLOps.component(...)
パイプライン処理のそれぞれの処理を定義する際に使います。関数内で使用するライブラリなどのバージョンをここで指定することもできます。@AutoMLOps.pipeline(...)
それぞれのコンポーネントをパイプラインとして組み合わせる際に使用します。各要素をどのような順序で実行するかを制御できます。
この2つを使ってパイプライン処理を定義したら、実際にサービスをデプロイする作業に移ります。これを実現するために6つの関数が提供されています。
AutoMLOps.generate(...)
上の2つのデコレータを使って定義したパイプライン処理のための MLOps サービスを展開するために必要なコードを自動生成します。具体的には各コンポーネントごとに設定や構成情報が記述された YAML ファイルや GCP の各サービスを展開するために必要な CLI コマンドが記述されたスクリプトが自動作成されます。AutoMLOps.provision(...)
自動作成されたスクリプトをもとに、Artifact Registory の作成やサービスアカウントの設定等を実施するための関数です。AutoMLOps.deploy(...)
ビルドや docker image の push を行い、実際にパイプライン処理をデプロイするために使用します。AutoMLOps.monitor(...)
エンドポイントにデプロイされたモデルに対して、monitoring job を実行する際に使用します。-
AutoMLOps.launchAll(...)
generate(),provision(),deploy()の3つの関数を一気に実行します。 AutoMLOps.deprovision(...)
AutoMLOps によって自動作成された MLOps のインフラを削除するために使用します。terraformとpulumiをフレームワークとして指定して AutoMLOps を利用した場合のみ使えるようです。(記事公開時点)
今回は generate() で MLOps に必要なコードを自動生成し、provision(), deploy() でサービスを実際に展開したのち、 monitor() を使ってエンドポイントへ推論リクエストを送るところまで実施してみます。
実際に使ってみた
今回は GitHub ページに公開されているサンプルコードを使用します。 内容としては、BigQuery から学習データを取得し、多クラス分類を行う決定木モデルを学習、最後に推論エンドポイントを立てる流れになります。 コードをまとめたり、リージョンを変更するための編集を行いますが、基本的にはサンプルコードをそのまま利用する形になっています。
今回構築されるCI/CDパイプラインの全容としては以下のような形になっています(画像は GitHub ページより引用)。
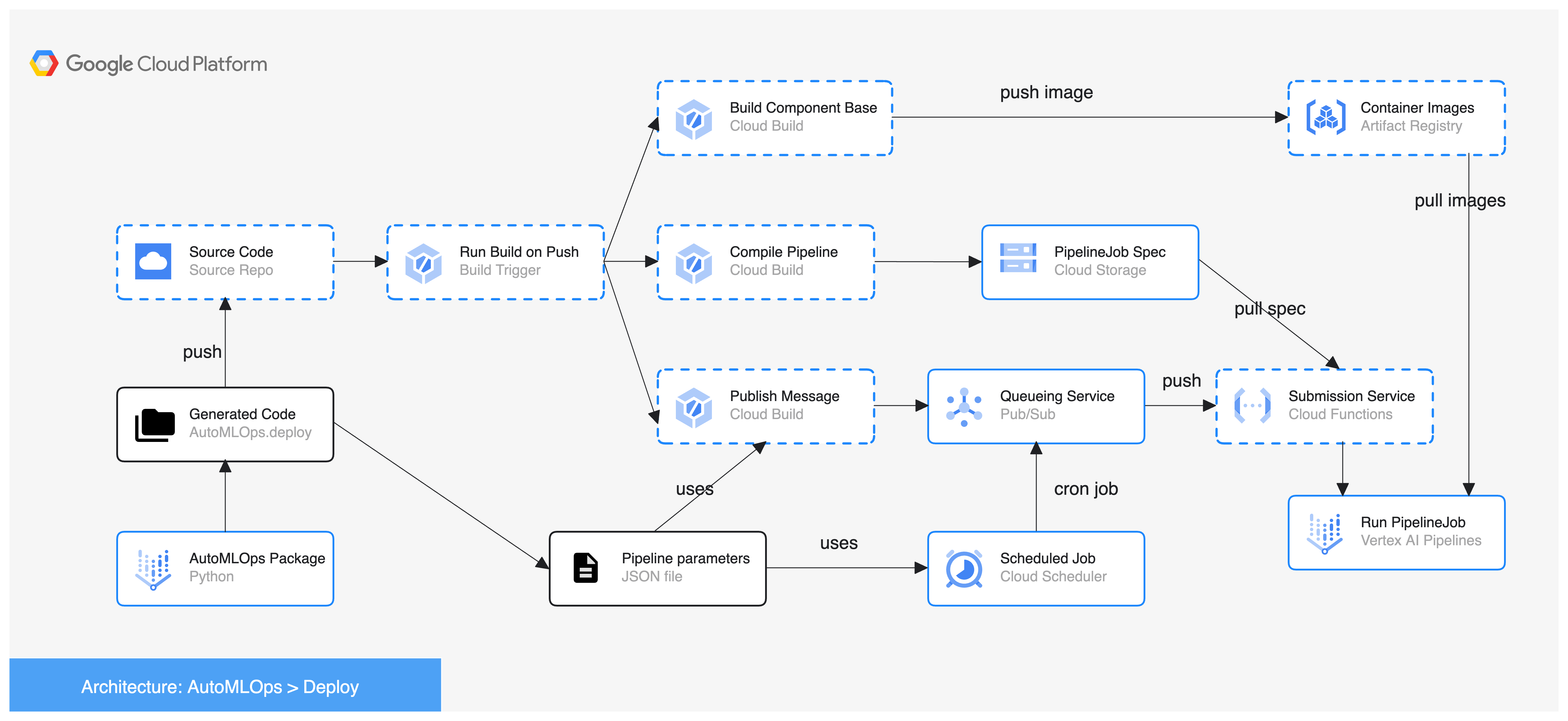
事前準備
ライブラリとして主に必要になるのは google-cloud-automlops ですが、必要に応じて google-cloud-bigquery や google-cloud-aiplatform も pip などでインストールしておきます。
また Python のバージョンとしては Python 3.7 - 3.10 がサポートされているようですので、ご留意頂ければと思います。
また事前準備として、使用するデータセットを BigQuery にアップロードしておきます。こちらも用意されている csv ファイルと関数を使えば手軽に準備できます。 以下のように BQ 上に展開されれば事前準備としては完了になります。

用意したプログラム
今回は以下のようなディレクトリ構造で開発をスタートします。
.
├── .env # リージョン指定などに使用する環境変数
├── data # BQ にアップロードしたデータセット
│ └── Dry_Beans_Dataset.csv
└── src
├── callable_functions.py # component を用意
├── main.py # pipeline を組み, AutoMLOps を実行
├── inference.py # 推論用のコードを記述
└── upload_to_bq.py # 事前準備で使用
主に必要になるのは、構成要素を定義する callable_functions.py とそれらをパイプラインとして組み立てる処理が記述された main.py になります。
inference.py は推論リクエスト処理に関するもので、本記事の後半で使用します。
またリージョンなどの環境変数は .env に定義することとします。
(Dry_Beans_Dataset.csv および upload_to_bq.py は事前準備のデータアップロードで使用したものになるので、以降は特に使用しません)
callable_functions.py
ここでは @AutoMLOps.component(...) のデコレータを使用してパイプラインで必要になる各処理を定義します。ここで AutoMLOps 特有の記述方法が出てきます。それはそれぞれの関数で処理に必要なライブラリを関数の内側で import する記述が必要になります。
またこの時、デコレータの引数として packages_to_installが用意されており、ライブラリのバージョン指定が可能となっています。バージョン指定が必要ない場合などは空でも問題ありません。
今回は「データの準備 → モデルの学習 → エンドポイントにデプロイ」するためにそれぞれを関数として用意します。
create_dataset(...): 学習に必要なファイルを BQ から取得し、前処理を行います。train_model(...): 多クラス分類を行う決定木モデルの学習、保存を行います。deploy_model(...): 学習済みのモデルをエンドポイントにデプロイし、推論リクエストを受け付けられるようにします。
関数の中に必要な処理を全て盛り込むような書き方になるので、少し煩雑に見えますが、処理としては比較的単純なものばかりとなっています。
from google_cloud_automlops import AutoMLOps
@AutoMLOps.component(
packages_to_install=[
'google-cloud-bigquery',
'pandas',
'pyarrow',
'db_dtypes',
'fsspec',
'gcsfs'
]
)
def create_dataset(
bq_table: str,
data_path: str,
project_id: str
):
from google.cloud import bigquery
import pandas as pd
from sklearn import preprocessing
bq_client = bigquery.Client(project=project_id)
def get_query(bq_input_table: str) -> str:
# sample code そのままですが、実行時はご注意ください
return f'''
SELECT *
FROM {bq_input_table}
'''
def load_bq_data(query: str, client: bigquery.Client) -> pd.DataFrame:
df = client.query(query).to_dataframe()
return df
dataframe = load_bq_data(get_query(bq_table), bq_client)
le = preprocessing.LabelEncoder()
dataframe['Class'] = le.fit_transform(dataframe['Class'])
dataframe.to_csv(data_path, index=False)
@AutoMLOps.component(
packages_to_install=[
'scikit-learn==1.2.2',
'pandas',
'joblib',
'tensorflow'
]
)
def train_model(
data_path: str,
model_directory: str
):
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
import tensorflow as tf
import pickle
import os
def save_model(model, uri):
"""Saves a model to uri."""
with tf.io.gfile.GFile(uri, 'w') as f:
pickle.dump(model, f)
df = pd.read_csv(data_path)
labels = df.pop('Class').tolist()
data = df.values.tolist()
x_train, x_test, y_train, y_test = train_test_split(data, labels)
skmodel = DecisionTreeClassifier()
skmodel.fit(x_train,y_train)
score = skmodel.score(x_test,y_test)
print('accuracy is:',score)
output_uri = os.path.join(model_directory, 'model.pkl')
save_model(skmodel, output_uri)
@AutoMLOps.component(
packages_to_install=[
'google-cloud-aiplatform'
]
)
def deploy_model(
model_directory: str,
project_id: str,
region: str
):
import pprint as pp
import random
from google.cloud import aiplatform
aiplatform.init(project=project_id, location=region)
# Check if model exists
models = aiplatform.Model.list()
model_name = 'beans-model'
if 'beans-model' in (m.name for m in models):
parent_model = model_name
model_id = None
is_default_version=False
version_aliases=['experimental', 'challenger', 'custom-training', 'decision-tree']
version_description='challenger version'
else:
parent_model = None
model_id = model_name
is_default_version=True
version_aliases=['champion', 'custom-training', 'decision-tree']
version_description='first version'
serving_container = 'us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-2:latest'
uploaded_model = aiplatform.Model.upload(
artifact_uri=model_directory,
model_id=model_id,
display_name=model_name,
parent_model=parent_model,
is_default_version=is_default_version,
version_aliases=version_aliases,
version_description=version_description,
serving_container_image_uri=serving_container,
serving_container_ports=[8080],
labels={'created_by': 'automlops-team'},
)
endpoint = uploaded_model.deploy(
machine_type='n1-standard-4',
deployed_model_display_name='deployed-beans-model')
sample_input = [[random.uniform(0, 300) for x in range(16)]]
# Test endpoint predictions
print('running prediction test...')
try:
resp = endpoint.predict(instances=sample_input)
pp.pprint(resp)
except Exception as ex:
print('prediction request failed', ex)
main.py
ここでは @AutoMLOps.pipeline(...) を使って機械学習パイプラインを構築します。
pipeline()関数を定義し、各コンポーネントを実行します。
この時それぞれの呼び出しのタイミングで .after(another_component) としてどの処理の後に実行するかを明示的に指定します。
これで AutoMLOps を利用する準備は完了です!
それでは main()関数として、サンプルコードに対して monitoring などの処理を少し書き加えて動かしてみようと思います。
import os
import sys
import datetime
import argparse
from dotenv import load_dotenv
from google.cloud import aiplatform
from google_cloud_automlops import AutoMLOps
from callable_functions import create_dataset, train_model, deploy_model
from inference import run_inference
load_dotenv()
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--operation', type=str, required=True,
choices=['provision', 'deploy', 'generate', 'monitor'])
return parser.parse_args()
@AutoMLOps.pipeline
def pipeline(
bq_table: str,
model_directory: str,
data_path: str,
project_id: str,
region: str):
create_dataset_task = create_dataset(
bq_table=bq_table,
data_path=data_path,
project_id=project_id)
train_model_task = train_model(
model_directory=model_directory,
data_path=data_path).after(create_dataset_task)
deploy_model_task = deploy_model(
model_directory=model_directory,
project_id=project_id,
region=region).after(train_model_task)
pipeline_params = {
'bq_table': os.getenv('TRAINING_DATASET'),
'model_directory': f'gs://{os.getenv("PROJECT_ID")}-{os.getenv("MODEL_ID")}-bucket/trained_models/{datetime.datetime.now()}',
'data_path': f'gs://{os.getenv("PROJECT_ID")}-{os.getenv("MODEL_ID")}-bucket/data.csv',
'project_id': os.getenv('PROJECT_ID'),
'region': os.getenv('REGION'),
}
if __name__ == '__main__':
args = get_args()
if args.operation == 'generate':
AutoMLOps.generate(
project_id=os.getenv('PROJECT_ID'),
pipeline_params=pipeline_params,
use_ci=True,
naming_prefix=os.getenv('MODEL_ID'),
schedule_pattern='59 11 * * 0', # retrain every Sunday at Midnight
setup_model_monitoring=True, # use this if you would like to use Vertex Model Mointoring
artifact_repo_location=os.getenv('REGION'),
build_trigger_location=os.getenv('REGION'),
pipeline_job_submission_service_location=os.getenv('REGION'),
schedule_location=os.getenv('REGION'),
storage_bucket_location=os.getenv('REGION'),
)
if args.operation == 'provision':
AutoMLOps.provision(hide_warnings=False)
if args.operation == 'deploy':
AutoMLOps.deploy(precheck=True, hide_warnings=False)
# optional
if args.operation == 'monitor':
aiplatform.init(project=os.getenv("PROJECT_ID"), location=os.getenv("REGION"))
endpoints = aiplatform.Endpoint.list(filter='display_name="beans-model_endpoint"')
print(aiplatform.Endpoint.list())
if not endpoints:
print('No endpoint found. Please deploy the model first.')
sys.exit()
else:
AutoMLOps.monitor(
alert_emails=['email'],
target_field='Class',
model_endpoint=aiplatform.Endpoint.list(filter='display_name="beans-model_endpoint"')[0].resource_name,
monitoring_interval=1,
auto_retraining_params=pipeline_params,
drift_thresholds={'Area': 0.000001, 'Perimeter': 0.000001},
skew_thresholds={'Area': 0.000001, 'Perimeter': 0.000001},
training_dataset=f'bq://{os.getenv("TRAINING_DATASET")}',
hide_warnings=False,
monitoring_location=os.getenv('REGION'),
)
run_inference()
AutoMLOps によるコード自動生成
まずはじめに、AutoMLOps.generate(...)で必要なファイルを自動生成します。
下記コマンド実行により AutoMLOps ディレクトリが自動生成されます。
このディレクトリには先ほど作成したパイプラインに基づいて、GCP の各種サービスを展開するために必要なマニフェストやスクリプトが含まれており、それぞれ provisioning や deploy を行うときに実行されるファイルとなっています。
またこの時 artifact_repo_location などの引数を使って、各種サービスを展開する際のリージョン指定や schedule_pattern でのスケジューリングパターンを指定できます。
python src/main.py --operation generate
上記コマンドを実行し Code Generation Complete. の文言が出力されれば成功です!
AutoMLOps による provisioning, deploy
では自動生成されたファイルを使って、実際にサービスの provisioning を行います。
以下のコマンドを叩いて AutoMLOps.provision(...) の実行します。
python src/main.py --operation provision
実体としては自動生成された AutoMLOps/provision/provision_resources.sh が実行されます。ここでは以下のサービスが自動で作成されますが、同名のものが既に存在する場合はスキップされます。
- Artifact Registory
- Cloud Storage Bucket
- Pipeline Job Runner Service Account の作成および権限設定
- Cloud Source Repogitory
- Pub/Sub Topic
- Cloud Run Function
- Cloud Build
- Cloud Scheduler
展開されるサービスの多さから、自動ながらもリッチな CI/CD パイプラインが自動構築される様子が伺えます。
続いてデプロイ作業を行います。以下のコマンドにより AutoMLOps.deploy(...) の実行します。
python src/main.py --operation deploy
このコマンドを実行すると Cloud Source Repogitory へのコード転送などが行われ、これをトリガーに docker image のビルドなどが走ります。ビルドの詳細については自動生成された AutoMLOps/cloudbuild.yamlに書かれています。Component ごとに image を分けたい場合は別途対応が必要になりますが、この辺りも自動で生成してくれるのはありがたいですね。
ビルドがうまくいくと VertexAI 上でモデル訓練のためのパイプライン処理が走ります。
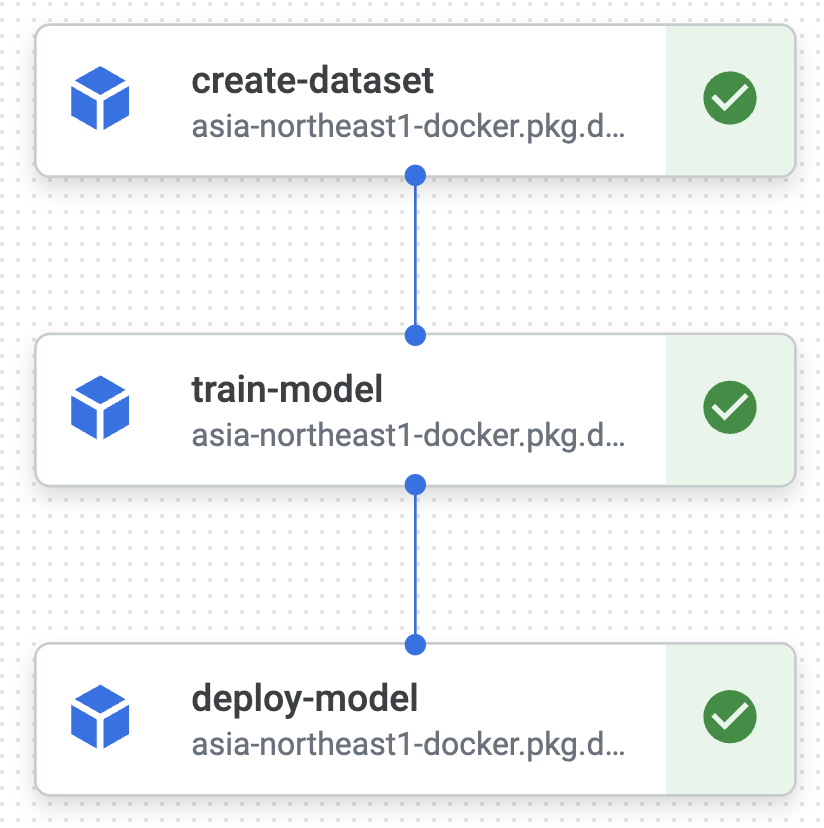
学習が完了するとモデルが Model Registory に出現し、エンドポイントに自動でデプロイされます。 また今回の場合、上記の VertexAI パイプラインは Cloud Scheduler の Pub/Sub トピック送信により Cloud Run 関数がトリガーされることで、定期的な実行もされるようになっています。
ここまで無事に実行されれば、あとはエンドポイントに対する推論リクエストが可能になります。
モデルエンドポイントのモニタリング
最後に、学習済みのエンドポイントに対して推論リクエストを送ります。以下のコマンドで AutoMLOps.monitor(...)を実行します。
VertexAI 上で monitoring job が作成されます。
import os
from dotenv import load_dotenv
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report
from google.cloud import bigquery, aiplatform
import pandas as pd
load_dotenv()
def get_query(bq_input_table: str) -> str:
# sample code そのままですが、実行時はご注意ください
return f'''
SELECT * FROM {bq_input_table}
'''
def load_bq_data(query: str, client: bigquery.Client) -> pd.DataFrame:
df = client.query(query).to_dataframe()
return df
def run_inference(num_samples: int=30):
bq_client = bigquery.Client(project=os.getenv('PROJECT_ID'))
df = load_bq_data(get_query(os.getenv('TRAINING_DATASET')), bq_client)
sampled_df = df.sample(n=num_samples)
X_sample = sampled_df.iloc[:, :-1][:num_samples].values.tolist()
Y_sample = sampled_df.iloc[:, -1][:num_samples].values.tolist()
endpoints = aiplatform.Endpoint.list(filter=f'display_name="beans-model_endpoint"')
endpoint_name = endpoints[0].resource_name
endpoint = aiplatform.Endpoint(endpoint_name)
response = endpoint.predict(instances=X_sample)
predictions = response[0]
# calc accuracy
le = LabelEncoder()
y_true = df.iloc[:, -1].values.tolist()
le.fit(y_true)
y_true_encoded = le.transform(Y_sample)
print(classification_report(y_true_encoded, predictions))
推論の中身としては上記の inference.py に記述したものを行います。
学習データからランダムに 30 件データをサンプルし、結果を見てみます。100% の accuracy となっている推論結果が無事に返ってきました。
precision recall f1-score support
0 1.00 1.00 1.00 3
1 1.00 1.00 1.00 2
2 1.00 1.00 1.00 3
3 1.00 1.00 1.00 11
4 1.00 1.00 1.00 5
5 1.00 1.00 1.00 5
6 1.00 1.00 1.00 1
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
このとき、スキューやドリフトが検知されると monitoring job によりメールが飛んでくることがあります。閾値やメール送信先の設定は AutoMLOps.monitor(...) の引数で指定できます。
実際の運用を考えると、こういった検知までを手軽に組み込めるのは嬉しいですね。
おわりに
この記事では AutoMLOps のサンプルコードを使用して実際にどのように動くのかを検証してみました。 AutoMLOps によって展開されるサービスはユーザが選択できる箇所もあり、希望に沿った柔軟な CI/CD パイプラインを組むことができます。例えば今回は Cloud Source Repogitory を利用していましたが、Github Actions や Gitlab, Bitbucket を代わりに使用することもできます。
この記事が「AutoMLOps、使ったことなかった」や「手軽に機械学習のCI/CDパイプラインを組みたかった」という気持ちを抱えていた人の一助になれば幸いです。




